Học AI Agents
"Học AI Agents" là một hành trình thực tiễn giúp người đọc khám phá và xây dựng các ứng dụng AI Agent thông minh, linh hoạt. Với trọng tâm là các công nghệ hiện đại như LangChain, LangGraph, và các mô hình ngôn ngữ lớn (LLMs), sách hướng dẫn từng bước để phát triển các agent có khả năng tương tác, ra quyết định và sử dụng công cụ hiệu quả. Bên cạnh lý thuyết súc tích, sách đi kèm nhiều ví dụ thực tế như tạo chatbot, trợ lý cá nhân, hệ thống phân tích tự động. Đặc biệt phù hợp cho developer, data engineer và những ai đang muốn ứng dụng AI vào sản phẩm của mình. Đây là cuốn sách cầu nối giữa tư duy kỹ thuật và sức mạnh của AI hiện đại.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
- Tìm Hiểu Tiềm Năng Thực Sự Của AI AGENTS
- Gen AI và AI Agents
- AI Agents và Multi-Agents
- Minh hoạ một hệ thống Multi-Agent trong nhà máy sản xuất cơ khí
- Thị Trường AI Agents: Cơ Hội, Chi Phí và Xu Hướng Ứng Dụng Trong Doanh Nghiệp
- Lợi Ích Chính Của AI Agent Trong Doanh Nghiệp Hiện Đại
- Nguyên tắc triển khai AI agent
- Các trường hợp ứng dụng của AI Agent trong đời sống
- Làm Thế Nào Để Xây Dựng Kế Hoạch Giới Thiệu AI Agents Trong Công Ty Của Bạn?
- Những thách thức triển khai AI Agents
- Yêu cầu pháp lý (Regulatory) trong xây dựng AI Agents:
- Sự hiện hữu của AI Agents
- Cách Xây Dựng AI AGENTS Chuyên Nghiệp
- Agent, Assistant và Message
- Giới thiệu
- Assistant và Agent
- HumanMessage – Tin nhắn từ người dùng
- AIMessage – Tin nhắn phản hồi từ AI
- SystemMessage - Thiết lập ngữ cảnh
- ToolMessage - Kết quả phản hồi từ một công cụ (tool)
- ToolCall - Mô hình ngôn ngữ gọi đến một công cụ
- Giới thiệu về LangGraph
- Giới thiệu về LangGraph
- Vì sao LangGraph ra đời và Graph có ý nghĩa gì
- Lập trình khai báo(declarative) và Lập trình mệnh lệnh(imperative)
- So sánh LangGraph và LangChain
- Tác nhân điều phối(Agentic) trong ứng dụng mô hình ngôn ngữ lớn (LLMs)
- Cấp độ hành vi của tác nhân(Agentic) trong ứng dụng LLM
- LangGraph Studio, giới thiệu, cài đặt và cách dùng
- Tạo ứng dụng cơ bản LangGraph AI Agents.
- LangGraph: Framework Xây Dựng Ứng Dụng LLM Dựa Trên Agent + Graph
- 5 Khái Niệm Trụ Cột
- Giới thiệu Poetry
- Cơ bản về GraphBuilder
- Xây dựng một ứng dụng đơn giản (graph) quyết định xem người dùng nên uống cà phê hay trà
- Ứng dụng LangGraph cơ bản với chatbot và công cụ
- Định tuyến(Router) trong LangGraph
- So sánh Router và Node trong LangGraph
- Hiểu rõ hơn về add_conditional_edges
- Bài Thực Hành Router Trong LangGraph
- Giới thiệu về ReAct Architecture
- Thực hành – Node LLM quyết định bước tiếp theo
- Kết nối các công cụ (tools) bằng bind_tools
- Xây dựng một ứng dụng quyết định xem có nên trò chuyện bằng LLM hay sử dụng công cụ
- Tóm tắt chương
- Memory (Bộ nhớ)
- Giới Thiệu
- Thêm Bộ Nhớ Ngắn Hạn vào Agent trong LangGraph
- Thực hành bộ nhớ ngắn hạn
- Định dạng state schema trong LangGraph từ TypeDict sang Pydantic
- Cách Tùy Chỉnh Cập Nhật Trạng Thái bằng Reducers
- Public State, Private State và Multiple State Schemas trong LangGraph
- Thực hành Public State and Private State
- Hiệu quả bộ nhớ và khả năng lưu trữ bộ nhớ trong Agent LangGraph
- Giới thiệu
- Tối Ưu Chi Phí và Quản Lý Bộ Nhớ Khi Xây Dựng Ứng Dụng AI Với OpenAI
- Tối ưu hóa bộ nhớ ngắn hạn bằng cách tóm tắt hội thoại
- Giới thiệu về Bộ nhớ Ngoài (Persistent Memory) với LangGraph
- Tóm tắt chương
- Phản hồi từ người dùng(Human Feedback)
- Giới thiệu
- Streaming và Human-in-the-loop trong LangGraph
- Breakpoints và Human-in-the-loop trong LangGraph
- OpenAI Agent SDK
- Giới thiệu
- 3 Bước với OpenAI Agents SKD
- OpenAI Agent SDK vs. LangGraph
- Agent, Runner, and Trace Classes
- Vibe Coding - Lập Trình Theo Cảm Hứng với AI
- Core Concepts for AI Development
- Tạo 3 agent bán hàng với phong cách giao tiếp khác nhau
- Tạo 3 Agents bán hàng theo kiểu luồng (streaming)
- Agent trong OpenAI Agent SDK để gọi dữ liệu sản phẩm từ một API thật(Tool)
- AI Sales Agents sử dụng OpenAI Agent SDK, SendGrid để gửi email chào hàng
- Xây Dựng Hệ Thống Sales Agent Thông Minh với OpenAI SDK
- Agent as Tool và Handoff
- Bài tập thực hành: Tự động hóa bán hàng với OpenAI Agent SDK
- “Hàng Rào An Toàn” Cho AI - Guardrails
- Thực hành Xây dựng AI Agent “Sales Manager” với Guardrails
- Giới Thiệu Dịch vụ web-search
- Tạo Ứng Dụng Agent Tự Nghiên Cứu
- Xây dựng "Planner Agent" – Trợ lý lập kế hoạch tìm kiếm thông minh
- Bài Thực Hành: "Trợ Lý Lập Kế Hoạch Marketing"
- BÀI THỰC HÀNH: Xây dựng Deep Research Agent và gửi kết quả qua Email
Tìm Hiểu Tiềm Năng Thực Sự Của AI AGENTS
AI Agents đang thay đổi cách chúng ta làm việc, học tập và tương tác với công nghệ. Không chỉ đơn thuần là công cụ tự động hóa, chúng còn có khả năng ra quyết định, thích ứng và cộng tác như một “đồng nghiệp số” thực thụ. Để tận dụng hết tiềm năng này, chúng ta cần hiểu rõ cách AI Agents hoạt động, ứng dụng và tạo ra giá trị thực trong doanh nghiệp và cuộc sống.
Gen AI và AI Agents
Gen AI là gì?
Gen AI (viết tắt của Generative Artificial Intelligence) là một nhánh của trí tuệ nhân tạo tập trung vào việc tạo ra nội dung mới thay vì chỉ phân tích hay nhận diện như AI truyền thống.
Ví dụ về Gen AI:
-
Viết văn bản
-
Vẽ tranh, tạo ảnh từ mô tả
-
Viết code
-
Tạo nhạc
-
Viết bài thơ, kịch bản, v.v.
Công nghệ nền tảng:
-
Mô hình ngôn ngữ lớn (Large Language Models – LLMs) như GPT-4, Gemini, Claude, LLaMA...
-
Diffusion models: thường dùng trong tạo hình ảnh (Stable Diffusion, Midjourney)
AI Agents là gì?
AI Agents (hay còn gọi là Autonomous Agents) là những hệ thống AI có khả năng tự chủ động thực hiện các hành động để đạt được mục tiêu nào đó. Chúng không chỉ phản hồi một câu hỏi đơn giản, mà còn có thể:
-
Tự lên kế hoạch (planning)
-
Tự thực hiện các bước nhỏ
-
Tự điều chỉnh hành vi khi gặp lỗi hoặc có dữ liệu mới
Ví dụ dễ hiểu:
Bạn nói với AI Agent:
“Tìm kiếm thông tin về thị trường ô tô Việt Nam, viết báo cáo, tạo biểu đồ và gửi vào email tôi.”
Thì AI Agent có thể:
-
Dùng công cụ tìm kiếm → tổng hợp thông tin
-
Phân tích dữ liệu → viết báo cáo
-
Tạo biểu đồ bằng code (Python, Excel, v.v.)
-
Kết nối Gmail → gửi mail
Tất cả các bước đều tự động, và có logic suy nghĩ như một con người làm việc.
Một số Framework phổ biến:
-
LangChain
-
AutoGPT
-
AgentGPT
-
CrewAI
So sánh đơn giản:
| Đặc điểm | Gen AI | AI Agent |
|---|---|---|
| Mục tiêu chính | Tạo nội dung | Hoàn thành nhiệm vụ |
| Tính chủ động | Phản hồi theo yêu cầu | Tự ra quyết định, tự thực hiện |
| Ví dụ | ChatGPT viết bài, DALL·E vẽ tranh | AutoGPT hoàn thành project |
Dưới đây là ví dụ cụ thể về Gen AI và AI Agents được áp dụng trong lĩnh vực sản xuất (ví dụ: cơ khí, nhà máy, ERP...):
Gen AI trong sản xuất:
Tình huống: Hỗ trợ lập báo cáo sản xuất
Bạn cần viết một báo cáo năng suất xưởng gia công trong tuần để gửi cho giám đốc.
Gen AI làm gì?
Bạn chỉ cần nhập:
“Tạo báo cáo tổng kết năng suất xưởng A từ dữ liệu sau: số lượng sản phẩm, tỷ lệ lỗi, thời gian vận hành máy...”
→ Gen AI (như ChatGPT) sẽ viết một báo cáo hoàn chỉnh với văn phong chuyên nghiệp, có thể thêm biểu đồ hoặc gợi ý cải tiến.
Tình huống: Đào tạo công nhân mới
Bạn có một nhóm công nhân mới chưa quen quy trình.
Gen AI làm gì?
Bạn dùng Gen AI để:
-
Tạo tài liệu đào tạo bằng ngôn ngữ dễ hiểu
-
Tự động chuyển tài liệu thành video, hình ảnh minh hoạ
-
Tạo chatbot nội bộ: “Hỏi gì cũng trả lời về quy trình sản xuất A”
AI Agents trong sản xuất:
Tình huống: Quản lý đơn hàng và tồn kho tự động
Bạn muốn tự động hoá việc:
-
Theo dõi tồn kho
-
Đặt hàng nguyên vật liệu
-
Cảnh báo nếu hàng chậm trễ hoặc vượt định mức
AI Agent làm gì?
-
Theo dõi hệ thống tồn kho
-
Nếu thấy sắp hết → tự động gửi đơn đặt hàng cho nhà cung cấp
-
Nếu phát hiện đơn hàng giao chậm → gửi cảnh báo cho phòng mua hàng
-
Nếu vượt mức tiêu hao nguyên vật liệu → gợi ý kiểm tra lỗi quy trình
Bạn chỉ cần thiết lập mục tiêu:
“Đảm bảo tồn kho nguyên vật liệu tối thiểu 500 đơn vị và không để ngưng sản xuất”
→ Agent sẽ tự vận hành như một nhân viên giám sát thông minh.
Tình huống: Kiểm soát chất lượng (QC)
Bạn muốn AI giám sát quy trình QC và đưa ra đánh giá.
AI Agent có thể:
-
Nhận dữ liệu từ cảm biến, camera, máy đo
-
Phân tích dữ liệu theo tiêu chuẩn
-
Tự động báo lỗi, cảnh báo nếu chất lượng sản phẩm không đạt
-
Gợi ý bước xử lý tiếp theo (ví dụ: cách khắc phục, đổi máy, kiểm tra lô hàng)
Tóm lại:
| Tình huống | Gen AI làm gì | AI Agent làm gì |
|---|---|---|
| Viết báo cáo QC | Viết nội dung, định dạng báo cáo | Lấy dữ liệu, tổng hợp, gửi báo cáo đúng giờ |
| Đào tạo nhân viên mới | Tạo tài liệu học, video minh hoạ | Tùy theo trình độ nhân viên, chọn nội dung học phù hợp |
| Quản lý đơn hàng | Viết email, báo cáo mua hàng | Tự đặt hàng, kiểm tra tiến độ, báo lỗi |
| Giám sát sản xuất | Viết cảnh báo nếu có lỗi | Tự thu thập dữ liệu, phát hiện lỗi, báo cáo |
-
AI Agent kiểm soát tồn kho tự động
-
Gen AI tạo báo cáo lỗi sản xuất từ dữ liệu thực tế
1. AI Agent kiểm soát tồn kho (Tự động hóa)
Mục tiêu:
“Đảm bảo nguyên vật liệu Thép tấm A luôn đủ trong kho để sản xuất, không bị gián đoạn.”
Quy trình hoạt động của Agent:
Input:
-
Số lượng tồn kho hiện tại (lấy từ hệ thống ERP)
-
Dữ liệu tiêu thụ trung bình hàng ngày
-
Thời gian giao hàng từ nhà cung cấp (3 ngày)
Agent thực hiện:
-
Kiểm tra tồn kho hiện tại
-
Ví dụ: còn 120 tấm Thép A
-
-
Dự đoán tiêu thụ trong 3 ngày tới
-
Dựa vào dữ liệu lịch sử: 30 tấm/ngày → 3 ngày = 90 tấm
-
-
So sánh tồn kho và mức an toàn
-
Nếu 120 - 90 < 50 → cần đặt hàng
-
-
Tự động gửi đơn hàng
-
Gửi email/mẫu đơn tới nhà cung cấp
-
-
Gửi cảnh báo tới phòng vật tư
-
“Dự kiến tồn kho xuống thấp trong 3 ngày. Đã gửi yêu cầu đặt hàng.”
-
Agent thực hiện mỗi ngày (cron job hoặc real-time)
Có thể xây bằng gì?
-
LangChain + Python: kết nối với Excel/ERP
-
Zapier/Make (no-code) nếu ERP có API
-
Giao diện web mini để giám sát Agent
2. Gen AI viết báo cáo lỗi sản xuất
Mục tiêu:
Viết báo cáo lỗi sản xuất trong tuần cho xưởng gia công cơ khí.
|
|
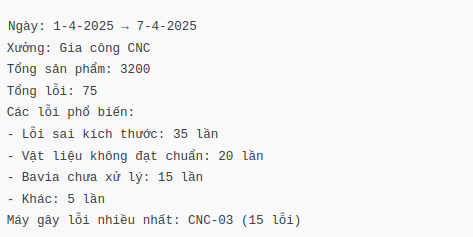
Gen AI tạo báo cáo:

Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
AI Agents và Multi-Agents
AI Agent là gì?
AI Agent là một hệ thống trí tuệ nhân tạo có thể tự hành động để hoàn thành mục tiêu nào đó. Nó có thể suy nghĩ, lên kế hoạch, ra quyết định và hành động mà không cần con người can thiệp liên tục.
Một AI Agent thường gồm 4 thành phần:
| Thành phần | Vai trò |
|---|---|
| Perception (Cảm nhận) | Nhận dữ liệu từ môi trường hoặc hệ thống |
| Reasoning (Suy luận) | Phân tích dữ liệu và đưa ra lựa chọn |
| Planning (Lập kế hoạch) | Xác định các bước cần làm |
| Action (Hành động) | Thực hiện hành động cụ thể (gửi email, chạy code, gọi API...) |
Ví dụ về AI Agent:
"Tạo Agent kiểm soát tồn kho nguyên vật liệu"
-
Nhận dữ liệu từ kho
-
Phân tích mức tiêu thụ
-
Dự đoán nguy cơ thiếu hụt
-
Tự động gửi yêu cầu đặt hàng
Multi-Agent là gì?
Multi-Agent System (Hệ thống đa tác tử) là một hệ thống gồm nhiều AI Agents làm việc cùng nhau, mỗi agent có vai trò riêng, phối hợp để hoàn thành một nhiệm vụ phức tạp hơn.
So sánh:
| AI Agent | Multi-Agent System | |
|---|---|---|
| Số lượng Agent | 1 | Nhiều |
| Mức độ phức tạp | Thấp đến trung bình | Cao |
| Tự vận hành | Có | Có, và có phối hợp với agent khác |
| Ứng dụng | Tác vụ đơn | Tác vụ phức tạp cần chia vai trò |
Ví dụ thực tế – Hệ thống Multi-Agent trong sản xuất
Mục tiêu: Quản lý toàn bộ quy trình sản xuất từ đơn hàng → sản xuất → QC → giao hàng
Gồm 4 AI Agents:
| Agent | Nhiệm vụ |
|---|---|
| Order Agent | Nhận đơn hàng, lên lịch sản xuất |
| Production Agent | Giám sát tiến độ sản xuất |
| QC Agent | Theo dõi lỗi, kiểm tra chất lượng |
| Logistics Agent | Điều phối giao hàng, lên lịch xe |
→ Các Agent này giao tiếp với nhau: ví dụ khi Production Agent hoàn thành, nó sẽ báo cho QC Agent kiểm tra.
Một số công cụ hỗ trợ Multi-Agent:
-
CrewAI – thiết kế nhóm Agent như 1 đội làm việc
-
AutoGen (Microsoft) – tạo Agent cộng tác với nhau
-
LangGraph (LangChain) – thiết kế luồng Multi-Agent phức tạp
-
MetaGPT – mô phỏng nhóm nhân viên (PM, Dev, QA...) làm dự án thật
Tổng kết:
| Khái niệm | AI Agent | Multi-Agent System |
|---|---|---|
| Định nghĩa | Hệ thống AI tự động xử lý một nhiệm vụ | Nhiều AI agents phối hợp để xử lý tác vụ phức tạp |
| Phạm vi | Tác vụ riêng lẻ | Dự án/Quy trình lớn |
| Giao tiếp | Không cần (hoặc ít) | Cần giao tiếp giữa các agent |
| Ứng dụng | Trả lời câu hỏi, giám sát thiết bị | Quản lý sản xuất, tài chính, lập kế hoạch |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Minh hoạ một hệ thống Multi-Agent trong nhà máy sản xuất cơ khí
Mô hình Multi-Agent cho Nhà máy Cơ khí
Mục tiêu:
Tự động hóa quy trình từ đặt hàng → sản xuất → QC → lưu kho → giao hàng, với các AI Agents phối hợp như một đội nhân sự.
Các AI Agents và nhiệm vụ
| Tên Agent | Vai trò chính |
|---|---|
| 🧾 Order Agent | Tiếp nhận đơn hàng, kiểm tra tồn kho, lên lịch sản xuất |
| ⚙️ Production Agent | Theo dõi tiến độ sản xuất, cập nhật trạng thái |
| 🔍 QC Agent | Tự động kiểm tra dữ liệu lỗi và đánh giá chất lượng |
| 📦 Inventory Agent | Kiểm soát kho, đảm bảo tồn kho nguyên vật liệu và thành phẩm |
| 🚚 Logistics Agent | Lên kế hoạch giao hàng và điều phối xe |
| 🤝 Communication Agent (Tùy chọn) | Gửi thông báo email, cảnh báo hoặc báo cáo |
Mô phỏng quy trình hoạt động
Order Agent
-
Nhận đơn hàng từ khách hàng (qua web/app)
-
Kiểm tra kho nguyên vật liệu với
Inventory Agent -
Nếu đủ → chuyển lệnh sản xuất cho
Production Agent -
Nếu thiếu → gửi yêu cầu mua hàng
Production Agent
-
Nhận lệnh sản xuất
-
Theo dõi từng công đoạn (CNC, hàn, phay…)
-
Cập nhật tiến độ
-
Khi hoàn tất từng lô → báo
QC Agent
QC Agent
-
Nhận thông báo từ sản xuất
-
Truy cập dữ liệu cảm biến/máy đo/ghi lỗi
-
Phân tích dữ liệu → đánh giá đạt hay không đạt
-
Gửi phản hồi:
-
Nếu đạt: chuyển hàng sang kho
-
Nếu lỗi: tạo báo cáo lỗi và gửi cảnh báo
-
Inventory Agent
-
Nhập hàng thành phẩm từ QC
-
Cập nhật tồn kho theo lô
-
Dự đoán thiếu hụt nguyên liệu và gửi cảnh báo
-
Hợp tác với Order Agent để đặt hàng bổ sung
Logistics Agent
-
Nhận thông tin hàng đã sẵn sàng
-
Lên lịch giao hàng
-
Tạo lệnh xuất kho
-
Gửi thông báo giao hàng cho khách
Communication Agent (tuỳ chọn)
-
Gửi thông báo qua Email/Zalo/Slack:
-
“Đơn hàng ABC đã hoàn tất QC, chuẩn bị giao hàng”
-
“Máy CNC-03 gặp lỗi liên tục, cần bảo trì”
-
“Tồn kho Thép SS400 dưới mức an toàn”
-
Sơ đồ hệ thống Multi-Agent (giản lược)
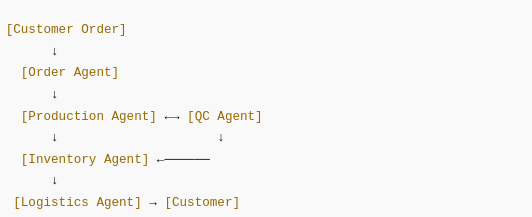
Công nghệ có thể sử dụng để triển khai:
| Nhu cầu | Gợi ý công nghệ |
|---|---|
| Xây dựng Agents | LangChain, CrewAI, AutoGen |
| Kết nối dữ liệu, API, ERP | Python, FastAPI, REST API |
| Tích hợp với hệ thống sẵn có | VHTerp, Odoo, SAP, SQL Server, Excel |
| Giao tiếp giữa Agents | WebSocket, Message Queue (RabbitMQ, MQTT) |
| Trực quan hóa trạng thái | Streamlit, Dash, React Dashboard |
Lợi ích thực tế
Giảm thời gian xử lý thủ công
Tăng độ chính xác trong lập lịch sản xuất
Cảnh báo sớm rủi ro (thiếu nguyên vật liệu, lỗi hàng loạt)
Tự động hoá báo cáo và thông báo
Giao tiếp giữa các bộ phận hiệu quả, không lệ thuộc con người
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thị Trường AI Agents: Cơ Hội, Chi Phí và Xu Hướng Ứng Dụng Trong Doanh Nghiệp
Cơ hội thị trường (Opportunities)
Thị trường AI Agents đang bùng nổ nhờ:
-
Tăng trưởng AI tổng quát (GenAI): ChatGPT, Claude, Gemini đang tạo đà phát triển cho các ứng dụng tự động hoá thông minh.
-
Tối ưu hoá vận hành doanh nghiệp: AI Agents có thể xử lý các tác vụ như lập kế hoạch sản xuất, chăm sóc khách hàng, kiểm soát chất lượng, phân tích dữ liệu...
-
Giảm chi phí nhân sự và tăng tốc độ ra quyết định.
-
Mở rộng khả năng cá nhân hoá trong trải nghiệm khách hàng.
Theo báo cáo của McKinsey, đến năm 2030, AI Agents có thể giúp tăng thêm 13 nghìn tỷ USD cho nền kinh tế toàn cầu.
Chi phí (Cost)
Chi phí phát triển và triển khai AI Agents phụ thuộc vào nhiều yếu tố:
| Hạng mục | Chi phí ước tính | Ghi chú |
|---|---|---|
| Phát triển nội bộ | Trung đến cao | Tốn thời gian, cần đội ngũ kỹ sư AI |
| Dùng nền tảng có sẵn | Thấp đến trung bình | CrewAI, LangChain, AutoGen, AgentOps... |
| Mô hình AI (LLM) | Biến động theo API | Dùng OpenAI, Claude, Mistral, LLaMA... |
| Bảo trì & tích hợp hệ thống | Trung bình | Cần đảm bảo bảo mật, hiệu suất cao |
Tổng quan, chi phí đang giảm nhờ mã nguồn mở, mô hình mã hoá nhẹ, và nền tảng hỗ trợ no-code/low-code.
Mức độ áp dụng trong doanh nghiệp (Enterprise adoption)
Các doanh nghiệp đang tích cực thử nghiệm và triển khai AI Agents, đặc biệt trong các khâu như:
-
Tự động hoá email, lịch trình, tạo báo cáo
-
Tối ưu chuỗi cung ứng và sản xuất
-
Phân tích dữ liệu người dùng, dự đoán hành vi
-
Trả lời câu hỏi nội bộ (internal Q&A agents)
🔹 Công ty đi đầu: Microsoft, Google, Meta, SAP, ServiceNow, Nvidia, OpenAI
🔹 Thị trường SMB (doanh nghiệp vừa và nhỏ) cũng đang thử nghiệm qua các nền tảng như Zapier AI Agents, LangGraph, hay MultiOn.
Ứng dụng theo ngành
1. Nội dung & Marketing (Content)
-
Tạo nội dung tự động (blog, email, bài quảng cáo)
-
Tối ưu SEO, phân tích hành vi khách hàng
-
Tương tác tự động với người dùng qua chatbot
Công cụ: Jasper, Copy.ai, Writer, AutoGPT
2. Y tế (Healthcare)
-
Trợ lý chẩn đoán ban đầu
-
Tổng hợp bệnh án, dữ liệu lâm sàng
-
Tư vấn sức khoẻ tự động (phù hợp cho telehealth)
Thí dụ: Agent kiểm tra triệu chứng, tổng hợp dữ liệu bệnh nhân để gửi bác sĩ.
3. Công nghệ sinh học (Biotech)
-
Tự động hoá quá trình tìm thuốc
-
Sàng lọc dữ liệu thử nghiệm lâm sàng
-
Hợp tác giữa các AI Agents mô phỏng phản ứng sinh học
Ví dụ: Agent đề xuất cấu trúc phân tử mới dựa trên dữ liệu protein.
4. Dịch vụ tài chính (Financial Services)
-
Phân tích rủi ro đầu tư, đề xuất danh mục
-
Phát hiện gian lận giao dịch
-
Tạo báo cáo tài chính định kỳ tự động
Ví dụ: Agent đọc và tổng hợp báo cáo lợi nhuận để hỗ trợ phòng tài chính ra quyết định.
5. Phát triển phần mềm (Software Development)
-
AI Agent đảm nhiệm vai trò Product Owner, Developer, Tester
-
Tạo/tối ưu code, viết tài liệu kỹ thuật
-
Quản lý backlog, tracking tiến độ
Ví dụ: Dự án MetaGPT mô phỏng cả đội làm sản phẩm: PM, Tech Lead, QA, Dev...
Tương lai của AI Agents
-
Tích hợp sâu với hệ thống doanh nghiệp (ERP, CRM, Data Warehouse…)
-
Khả năng tự học liên tục, nhớ ngữ cảnh, hiểu tổ chức
-
Multi-Agent coordination: nhiều Agent phối hợp như một nhóm người thật
-
Điều chỉnh hành vi theo văn hóa doanh nghiệp
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Lợi Ích Chính Của AI Agent Trong Doanh Nghiệp Hiện Đại
Trong kỷ nguyên chuyển đổi số, AI Agent (tác tử AI) đang trở thành một trong những công cụ mạnh mẽ nhất giúp doanh nghiệp nâng cao hiệu suất, giảm chi phí và tăng khả năng cạnh tranh. Với khả năng tự động hoá thông minh, phản ứng linh hoạt và học hỏi liên tục, AI Agent không chỉ là một công cụ – mà là một trợ lý ảo có tư duy.
Dưới đây là những lợi ích chính mà AI Agent mang lại:
Tự động hoá thông minh
AI Agent có thể đảm nhiệm nhiều công việc phức tạp mà trước đây đòi hỏi con người, ví dụ:
-
Xử lý email, phản hồi khách hàng
-
Tạo báo cáo, phân tích dữ liệu
-
Lên lịch họp, nhắc nhở công việc
-
Theo dõi và tối ưu quy trình sản xuất
⏱️ Kết quả: Tiết kiệm thời gian, tăng hiệu suất và giảm sai sót.
Ra quyết định nhanh và chính xác
AI Agent được hỗ trợ bởi các mô hình học máy (Machine Learning) và AI tổng quát (Generative AI), giúp:
-
Đưa ra quyết định dựa trên dữ liệu thời gian thực
-
Phân tích xu hướng, phát hiện bất thường
-
Dự báo nhu cầu, rủi ro, hành vi khách hàng
📊 Kết quả: Doanh nghiệp đưa ra quyết định dựa trên dữ liệu thay vì cảm tính.
Làm việc liên tục 24/7
Không như con người, AI Agent không cần nghỉ ngơi và có thể làm việc liên tục mọi thời điểm:
-
Phản hồi khách hàng ngoài giờ hành chính
-
Giám sát hệ thống, dây chuyền sản xuất cả ban đêm
-
Tự động cập nhật dữ liệu định kỳ
🌙 Kết quả: Đảm bảo quy trình hoạt động liền mạch, không bị gián đoạn.
Cá nhân hoá trải nghiệm người dùng
AI Agent có thể nhớ và học từ hành vi của từng người dùng để:
-
Gợi ý sản phẩm/dịch vụ phù hợp
-
Giao tiếp theo phong cách riêng biệt
-
Tư vấn tự động trong chăm sóc khách hàng
💬 Kết quả: Tăng sự hài lòng, giữ chân khách hàng và tạo ấn tượng chuyên nghiệp.
Giảm chi phí vận hành
Việc thay thế các thao tác thủ công bằng AI Agent giúp:
-
Tối ưu nguồn lực nhân sự
-
Giảm chi phí vận hành và đào tạo
-
Tăng ROI (lợi tức đầu tư) từ hạ tầng số
💰 Kết quả: Doanh nghiệp có thể mở rộng quy mô mà không cần tăng tương ứng về nhân sự.
Khả năng học hỏi và thích nghi
AI Agents có thể được huấn luyện và cải tiến liên tục để:
-
Hiểu quy trình doanh nghiệp sâu hơn
-
Thích ứng với thay đổi chính sách, quy định
-
Giao tiếp và hành xử theo văn hoá tổ chức
🧠 Kết quả: AI Agent ngày càng "thông minh" hơn và phù hợp hơn với môi trường thực tế.
Phối hợp linh hoạt trong môi trường Multi-Agent
Nhiều AI Agent có thể phối hợp như một đội ngũ chuyên trách, ví dụ:
-
Một Agent theo dõi sản xuất → báo QC Agent kiểm tra chất lượng
-
Agent phân tích dữ liệu → gọi báo cáo Agent tổng hợp thành báo cáo cuối
Kết quả: Xây dựng hệ thống làm việc thông minh, phân quyền rõ ràng và hiệu quả cao.
Kết luận
AI Agent đang trở thành “cánh tay phải kỹ thuật số” của mọi tổ chức hiện đại. Dù là trong sản xuất, tài chính, y tế, marketing hay chăm sóc khách hàng, việc áp dụng AI Agent không chỉ giúp doanh nghiệp đi nhanh hơn, mà còn đi đúng hướng và bền vững hơn trong tương lai.
Bạn đang cân nhắc đưa AI Agent vào doanh nghiệp mình? Hãy bắt đầu từ những tác vụ lặp đi lặp lại, nhiều dữ liệu – và mở rộng dần theo nhu cầu!
Gọi ngay cho đội ngũ VHTSoft(0969661340), chúng tôi sẽ hỗ trợ lập kế hoạch truyển khai mô hình AI cho doanh nghiệp bạn
Nguyên tắc triển khai AI agent
1. Cung cấp quyền truy cập nhật ký hệ thống(Provide Access to Logs)
Giới thiệu:
Ghi lại và truy cập nhật ký hoạt động của AI agent giúp theo dõi, kiểm tra và phân tích hành vi của hệ thống trong suốt vòng đời vận hành.
Key Practices:
-
Ghi nhật ký chi tiết các hành động, phản hồi, và đầu vào của AI.
-
Phân loại mức độ nhật ký (debug, info, warning, error).
-
Lưu trữ an toàn, bảo mật và có thể truy xuất lịch sử.
-
Cung cấp công cụ phân tích nhật ký cho nhà phát triển hoặc quản trị viên.
Benefits:
-
Giúp phát hiện lỗi và hành vi bất thường.
-
Hỗ trợ điều tra sự cố hoặc hành vi sai lệch.
-
Tăng cường tính minh bạch và độ tin cậy.
-
Cải thiện hệ thống qua việc phân tích hành vi thực tế.
2. Khả năng tạm dừng hoặc chấm dứt an toàn(Ability to Pause or Terminate Safely)
Giới thiệu:
Một AI agent nên được thiết kế sao cho có thể được tạm dừng hoặc chấm dứt hoạt động một cách an toàn mà không gây ra hậu quả nghiêm trọng hay mất mát dữ liệu.
Key Practices:
-
Thiết kế cơ chế “kill switch” (công tắc tắt nhanh).
-
Đảm bảo dừng AI không gây rối loạn hệ thống khác.
-
Tạo điểm dừng logic hoặc checkpoint cho việc tiếp tục.
-
Hạn chế AI tự vô hiệu hóa khả năng bị dừng bởi người.
Benefits:
-
Ngăn chặn hành vi ngoài kiểm soát.
-
Đảm bảo an toàn khi AI hoạt động trong môi trường thực.
-
Cho phép can thiệp kịp thời khi có sự cố.
-
Tăng cường khả năng kiểm soát bởi con người.
Giám sát bởi con người(Human Supervision)
Giới thiệu:
Sự can thiệp của con người đảm bảo rằng AI hoạt động đúng mục tiêu và đạo đức, đặc biệt khi xử lý các tình huống phức tạp hoặc có tác động lớn.
Key Practices:
-
Thiết lập các vai trò giám sát viên AI.
-
Tích hợp vòng phản hồi từ người giám sát.
-
Giao diện thân thiện để quan sát, đánh giá, và chỉnh sửa hành vi AI.
-
Áp dụng human-in-the-loop (con người trong vòng kiểm soát).
Benefits:
-
Ngăn ngừa hành vi sai lệch hoặc nguy hiểm.
-
Đảm bảo AI phù hợp với chuẩn mực xã hội và đạo đức.
-
Cải thiện AI nhờ phản hồi của con người.
-
Tăng niềm tin và khả năng chấp nhận từ người dùng.
4. Kiểm tra có hệ thống các dữ liệu lệch lạc(Systematic Audit for Biases )
Giới thiệu:
AI agent có thể vô tình học và khuếch đại các thiên lệch có trong dữ liệu huấn luyện. Do đó cần có quy trình kiểm tra định kỳ để phát hiện và giảm thiểu dữ liệu lệch lạc.
Key Practices:
-
Phân tích dữ liệu huấn luyện để phát hiện dữ liệu lệch lạc.
-
Thử nghiệm AI với các nhóm người dùng đa dạng.
-
Dùng các công cụ kiểm tra công bằng (fairness toolkits).
-
Lưu lại kết quả audit để đối chiếu theo thời gian.
Benefits:
-
Tăng tính công bằng và không phân biệt đối xử.
-
Tránh rủi ro pháp lý và tổn hại danh tiếng.
-
Cải thiện chất lượng và hiệu quả của AI.
-
Tạo ra trải nghiệm tích cực và đáng tin cậy cho người dùng.
5. Bảo vệ khỏi truy cập trái phép(Protect Against Unauthorized Access)
Giới thiệu:
AI agent cần được bảo vệ trước các mối đe dọa về an ninh mạng để tránh việc bị khai thác hoặc bị sử dụng vào mục đích xấu.
Key Practices:
-
Áp dụng cơ chế xác thực mạnh (multi-factor authentication).
-
Phân quyền truy cập theo vai trò.
-
Mã hóa dữ liệu và giao tiếp.
-
Kiểm tra bảo mật định kỳ và vá lỗ hổng kịp thời.
Benefits:
-
Bảo vệ dữ liệu người dùng và hệ thống.
-
Tránh bị lạm dụng hoặc điều khiển bởi tác nhân xấu.
-
Đáp ứng các tiêu chuẩn bảo mật (GDPR, ISO/IEC 27001, v.v.).
-
Duy trì sự tin tưởng và an toàn của hệ thống.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Các trường hợp ứng dụng của AI Agent trong đời sống
1. Dịch vụ tài chính(Financial Services)
Giới thiệu:
AI agents đang thay đổi cách ngành tài chính hoạt động thông qua việc tự động hóa quy trình, phân tích rủi ro, và cá nhân hóa trải nghiệm khách hàng.
Ứng dụng:
-
Phân tích tín dụng và rủi ro đầu tư
-
Phát hiện gian lận giao dịch theo thời gian thực
-
Tư vấn tài chính cá nhân (AI financial advisors)
-
Tự động hóa giao dịch chứng khoán (AI trading bots)
2. Phần mềm(Software )
Giới thiệu:
AI agents hỗ trợ tăng tốc quá trình phát triển phần mềm và cải thiện hiệu suất bảo trì, kiểm thử và triển khai hệ thống.
Ứng dụng:
-
Sinh mã tự động (code generation)
-
Hỗ trợ kiểm thử phần mềm (test case generation)
-
Phân tích lỗi và đề xuất sửa lỗi
-
Trợ lý lập trình tích hợp trong IDE
3. Marketing
Giới thiệu:
AI agents giúp cá nhân hóa nội dung, dự đoán hành vi khách hàng và tối ưu hóa chiến dịch tiếp thị một cách hiệu quả.
Ứng dụng:
-
Gợi ý nội dung, thông điệp quảng cáo phù hợp
-
Phân tích hành vi người dùng trên website/social media
-
Tự động hóa email marketing và chatbot tư vấn sản phẩm
-
Dự đoán xu hướng thị trường
4. Y tế(Healthcare)
Giới thiệu:
Trong ngành y tế, AI agents hỗ trợ chẩn đoán chính xác, theo dõi bệnh nhân và tối ưu hóa quá trình chăm sóc.
Ứng dụng:
-
Hỗ trợ bác sĩ trong chẩn đoán hình ảnh y khoa (X-ray, MRI)
-
Tư vấn sức khỏe ban đầu (virtual health assistant)
-
Nhắc lịch uống thuốc và theo dõi bệnh mạn tính
-
Phân tích hồ sơ bệnh án để phát hiện nguy cơ
5. Chuỗi cung ứng(Supply Chain)
Giới thiệu:
AI agents cải thiện khả năng dự báo, tối ưu hóa vận hành và quản lý tồn kho hiệu quả trong chuỗi cung ứng.
Ứng dụng:
-
Dự báo nhu cầu hàng hóa
-
Tối ưu tuyến đường vận chuyển
-
Quản lý kho thông minh
-
Phân tích rủi ro trong chuỗi cung ứng toàn cầu
6. Dịch vụ khách hàng(Customer Services)
Giới thiệu:
AI agents được sử dụng để cung cấp hỗ trợ khách hàng liên tục 24/7 và cá nhân hóa trải nghiệm tương tác.
Ứng dụng:
-
Chatbot trả lời câu hỏi thường gặp
-
Tự động phân loại và xử lý yêu cầu hỗ trợ
-
Phân tích cảm xúc khách hàng qua email/cuộc gọi
-
Tư vấn sản phẩm phù hợp dựa trên lịch sử mua hàng
7. Ứng phó khẩn cấp(Emergency Response)
Giới thiệu:
AI agents giúp cải thiện phản ứng nhanh và hiệu quả trong các tình huống khẩn cấp như thiên tai, tai nạn hoặc y tế.
Ứng dụng:
-
Dự đoán vị trí và tác động thiên tai (lũ, cháy rừng)
-
Trợ lý điều phối cấp cứu 115
-
Robot thăm dò khu vực nguy hiểm
-
Phân tích thông tin thời gian thực để hỗ trợ quyết định
8. Thương mại điện tử và bán lẻ(E-commerce and Retail)
Giới thiệu:
AI agents tạo ra trải nghiệm mua sắm thông minh hơn, giúp cá nhân hóa và tối ưu hóa chuỗi bán hàng.
Ứng dụng:
-
Gợi ý sản phẩm theo hành vi người dùng
-
Quản lý kho và tự động hóa đơn hàng
-
Trợ lý mua sắm bằng giọng nói
-
Phân tích phản hồi và đánh giá sản phẩm
9. Giáo dục và đào tạo(Education and Training)
Giới thiệu:
AI agents hỗ trợ người học cá nhân hóa lộ trình học tập, đưa ra phản hồi kịp thời và nâng cao hiệu quả giảng dạy.
Ứng dụng:
-
Gia sư ảo (AI tutor) theo dõi tiến độ học tập
-
Đánh giá bài viết, kiểm tra tự động
-
Tạo bài tập và đề thi phù hợp năng lực
-
Mô phỏng đào tạo trong môi trường ảo (VR + AI)
10. Trợ lý cá nhân và thiết bị thông minh(Personal Assistants and Smart Devices)
Giới thiệu:
AI agents ngày càng trở thành một phần thiết yếu trong đời sống cá nhân qua trợ lý ảo và các thiết bị IoT thông minh.
Ứng dụng:
-
Trợ lý ảo (như Siri, Alexa, Google Assistant)
-
Quản lý lịch, nhắc việc, điều khiển thiết bị trong nhà
-
Học thói quen người dùng để tối ưu hóa tự động hóa
-
Cảnh báo thời tiết, giao thông, sức khỏe
11. Robot thông minh(Robotics)
Giới thiệu:
AI agents đóng vai trò "bộ não" cho robot, giúp robot nhận thức môi trường, tương tác và đưa ra quyết định.
Ứng dụng:
-
Robot giao hàng, phục vụ trong nhà hàng
-
Robot y tế, chăm sóc người già
-
Robot cứu hộ ở khu vực nguy hiểm
-
Robot hỗ trợ sản xuất công nghiệp
12. Tác nhân đa nhiệm / Hệ thống nhiều tác nhân(Multi-Agents)
Giới thiệu:
Hệ thống nhiều AI agents làm việc cùng nhau để giải quyết các vấn đề phức tạp vượt quá khả năng của một tác nhân đơn lẻ.
Ứng dụng:
-
Mạng lưới drone phối hợp tìm kiếm cứu hộ
-
Tác nhân mô phỏng hành vi đám đông trong thành phố
-
Quản lý giao thông thông minh với nhiều AI agent
-
AI trong game chiến lược, mô phỏng hợp tác/đối đầu giữa nhiều tác nhân
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Làm Thế Nào Để Xây Dựng Kế Hoạch Giới Thiệu AI Agents Trong Công Ty Của Bạn?
Trong bối cảnh công nghệ ngày càng phát triển, AI Agents (tác nhân trí tuệ nhân tạo) đang trở thành công cụ đột phá giúp các doanh nghiệp nâng cao hiệu suất, tối ưu hóa vận hành và mở rộng khả năng sáng tạo. Nhưng làm sao để bắt đầu? Làm thế nào để hiểu tiềm năng thật sự của AI agents và từng bước xây dựng kế hoạch triển khai chúng trong tổ chức?
Hãy cùng khám phá một cách tiếp cận thực tiễn để giới thiệu AI Agents vào doanh nghiệp của bạn, từ khâu tìm hiểu đến triển khai và mở rộng.
1. Hiểu Rõ AI Agents Là Gì Và Mang Lại Lợi Ích Gì?
AI agents là những hệ thống có khả năng:
-
Quan sát môi trường,
-
Ra quyết định dựa trên dữ liệu đầu vào,
-
Hành động để đạt được mục tiêu cụ thể.
Khác với các hệ thống tự động hóa thông thường, AI agents có thể học hỏi, thích nghi và thậm chí phối hợp với các tác nhân khác (multi-agent systems) để giải quyết vấn đề phức tạp.
Lợi ích tiềm năng của AI Agents:
-
Tăng hiệu quả công việc (tự động hóa các tác vụ lặp đi lặp lại)
-
Cải thiện trải nghiệm khách hàng (chatbot, trợ lý ảo)
-
Tối ưu hóa quyết định (dựa trên phân tích dữ liệu)
-
Giảm sai sót và rủi ro vận hành
2. Đánh Giá Nhu Cầu Doanh Nghiệp & Các Tình Huống Ứng Dụng (Use Cases)
Trước khi xây dựng, bạn cần xác định các lĩnh vực có thể ứng dụng AI agents trong doanh nghiệp của mình. Một số lĩnh vực tiềm năng:
👉 Hãy bắt đầu từ một hoặc hai tình huống rõ ràng, có thể đo lường hiệu quả, trước khi mở rộng.
3. Thiết Kế Lộ Trình Triển Khai AI Agent
Dưới đây là các bước đề xuất trong kế hoạch triển khai:
Bước 1: Xây dựng đội ngũ và xác định người phụ trách
-
Tìm một nhóm nhỏ phụ trách AI (gồm kỹ thuật, nghiệp vụ và quản lý)
-
Phân công rõ vai trò: kỹ sư AI, chuyên gia dữ liệu, quản lý dự án,…
Bước 2: Chọn công nghệ và công cụ phù hợp
-
Có thể bắt đầu với các framework mã nguồn mở (LangChain, AutoGPT,…)
-
Tích hợp với dữ liệu hiện có: CRM, ERP, hệ thống nội bộ
-
Cân nhắc dùng nền tảng đám mây (Azure AI, OpenAI API, Google Vertex AI)
Bước 3: Phát triển phiên bản thử nghiệm (MVP)
-
Bắt đầu với quy mô nhỏ: một quy trình, một bộ phận
-
Đặt tiêu chí đo lường rõ ràng: tốc độ xử lý, độ chính xác, sự hài lòng người dùng
Bước 4: Đánh giá và cải tiến
-
Lắng nghe phản hồi từ người dùng nội bộ
-
Tinh chỉnh dữ liệu, mô hình và trải nghiệm tương tác
4. Đảm Bảo Các Yếu Tố Bảo Mật, Giám Sát Và Đạo Đức
Khi đưa AI agents vào hệ thống thực tế, bạn cần quan tâm đến:
-
Bảo mật dữ liệu: Tránh lộ thông tin cá nhân, dữ liệu kinh doanh nhạy cảm
-
Giám sát và kiểm soát: Cần có cơ chế để dừng AI agent khi cần
-
Tránh thiên vị (biases): Đảm bảo dữ liệu huấn luyện khách quan và đầy đủ
-
Tính minh bạch: Có khả năng truy vết và giải thích quyết định của AI
5. Mở Rộng Và Tích Hợp Sau Khi Thành Công Giai Đoạn Thử Nghiệm
Sau khi đã chứng minh hiệu quả của AI agent, bạn có thể:
-
Nhân rộng sang các bộ phận khác
-
Liên kết các agent lại thành hệ thống nhiều tác nhân (multi-agent)
-
Tối ưu liên tục dựa trên dữ liệu thu thập được trong quá trình hoạt động
Kết Luận
AI agents không phải là công nghệ xa vời — chúng đã và đang hiện diện trong các doanh nghiệp tiên phong. Với một kế hoạch rõ ràng, bạn hoàn toàn có thể:
-
Khám phá tiềm năng to lớn của AI,
-
Bắt đầu từ nhỏ và từng bước mở rộng,
-
Xây dựng hệ thống thông minh có khả năng học hỏi, thích nghi và phục vụ mục tiêu kinh doanh.
Bắt đầu hôm nay để đón đầu tương lai!
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Những thách thức triển khai AI Agents
Việc triển khai AI Agents trong doanh nghiệp và các tổ chức mở ra nhiều cơ hội đổi mới, nhưng cũng đi kèm với không ít thách thức phức tạp. Về mặt kỹ thuật, các AI Agents có thể gặp rủi ro như vòng lặp phản hồi vô hạn, thiếu khả năng giải thích quyết định, và đòi hỏi tài nguyên tính toán lớn. Hạ tầng công nghệ như mô hình nền tảng, phần cứng, điện toán đám mây và khả năng tích hợp phần mềm cũng có thể trở thành điểm nghẽn. Trong quá trình triển khai, doanh nghiệp cần đối mặt với các vấn đề như định nghĩa quy trình, bảo mật dữ liệu, giám sát con người và đảm bảo đạo đức AI. Bên cạnh đó, thị trường AI đang bị chi phối bởi các nhà cung cấp lớn, thỏa thuận độc quyền và rào cản từ các nền tảng di động. Cuối cùng, vấn đề quản trị như khung pháp lý, tiêu chuẩn, cơ chế minh bạch và hợp tác liên ngành cũng là yếu tố sống còn để đảm bảo AI phát triển bền vững và có trách nhiệm.
I. Rủi ro và hạn chế kỹ thuật của AI Agents
1. Sự hợp tác có nghĩa là nhiều rủi ro hơn
Mô tả: Khi nhiều AI agents cùng tương tác hoặc cộng tác để hoàn thành một nhiệm vụ, rủi ro hệ thống trở nên phức tạp hơn. Nếu một tác nhân có hành vi sai lệch, nó có thể ảnh hưởng dây chuyền đến các tác nhân khác, gây ra hiệu ứng domino.
Ví dụ: Trong một hệ thống AI hỗ trợ vận hành chuỗi cung ứng, một AI phụ trách dự đoán nhu cầu có thể đưa ra dự báo sai, khiến AI điều phối kho bãi nhập hàng dư thừa, và AI phụ trách vận chuyển phải xử lý khối lượng vượt mức — dẫn đến tắc nghẽn toàn hệ thống.
2. Vòng phản hồi vô hạn
Mô tả: Khi AI agent học từ phản hồi của chính mình hoặc từ tác nhân khác mà không có cơ chế giới hạn, có thể tạo ra vòng lặp phản hồi vô tận. Điều này dẫn đến hành vi lệch lạc, dữ liệu huấn luyện sai lệch hoặc quyết định ngày càng sai.
Ví dụ: Một chatbot AI trả lời khách hàng và đồng thời học từ phản hồi... của chính nó (vì bị nhầm là từ người dùng). Sau một thời gian, nó bắt đầu lặp lại câu trả lời không phù hợp và mất kiểm soát nội dung.
3. Tài nguyên tính toán
Mô tả: Các AI agents, đặc biệt là những agent phức tạp dùng mô hình ngôn ngữ lớn (LLMs), đòi hỏi sức mạnh tính toán rất cao. Điều này có thể làm tăng chi phí hạ tầng, chậm hệ thống hoặc gây quá tải.
Ví dụ: Một công ty triển khai AI trợ lý nội bộ sử dụng GPT để tổng hợp báo cáo. Khi hàng trăm nhân viên truy cập đồng thời, hệ thống trở nên chậm và tiêu tốn quá nhiều GPU trên cloud, gây tốn kém tài chính.
4. Thiếu khả năng giải thích
Mô tả: Nhiều AI agents hoạt động như hộp đen (black box), đưa ra quyết định mà con người khó hiểu được logic phía sau. Điều này gây khó khăn trong việc đánh giá, kiểm tra và tin tưởng AI.
Ví dụ: Một AI agent được giao nhiệm vụ từ chối hoặc duyệt đơn vay vốn, nhưng không thể giải thích lý do cụ thể tại sao đơn A được duyệt còn đơn B thì không, dù hồ sơ tương tự nhau. Điều này dễ dẫn đến nghi ngờ và khiếu nại.
II. Mô hình nền tảng
Mô tả: AI Agents thường dựa trên các mô hình ngôn ngữ lớn hoặc mô hình thị giác sâu đã được huấn luyện trước. Tuy nhiên, việc phụ thuộc vào các mô hình nền này có thể gây ra các vấn đề về chi phí, quyền truy cập, và độ phù hợp với từng trường hợp cụ thể. Ngoài ra, những mô hình này cũng có thể mang theo những thiên kiến và hạn chế từ dữ liệu gốc.
Ví dụ: Một công ty tài chính sử dụng GPT để hỗ trợ phân tích báo cáo tài chính. Tuy nhiên, mô hình nền tảng không hiểu rõ các khái niệm chuyên sâu trong ngành tài chính Việt Nam, dẫn đến phân tích sai hoặc thiếu thông tin quan trọng.
2. Phần cứng
Mô tả: Các tác nhân AI cần phần cứng mạnh mẽ, như GPU, TPU, RAM lớn hoặc thiết bị cảm biến chuyên biệt (trong robotics). Thiếu phần cứng phù hợp có thể làm chậm hệ thống, giảm hiệu suất, hoặc không thể chạy tác vụ thời gian thực.
Ví dụ: Một công ty bán lẻ triển khai robot AI để kiểm kê hàng hóa trong kho, nhưng robot không có đủ cảm biến hoặc camera chất lượng cao để đọc mã vạch trong điều kiện ánh sáng yếu — dẫn đến sai sót và tốn thời gian kiểm tra lại thủ công.
3. Hạ tầng đám mây
Mô tả: Hầu hết AI Agents hiện nay vận hành trên nền tảng điện toán đám mây. Tuy nhiên, hiệu suất của AI phụ thuộc nhiều vào khả năng mở rộng, bảo mật, và độ ổn định của cloud provider. Bất kỳ sự cố nào về mạng, bảo mật, hay tài nguyên hạn chế cũng ảnh hưởng đến toàn hệ thống.
Ví dụ: Một AI chăm sóc khách hàng đang vận hành qua dịch vụ đám mây bị gián đoạn do sự cố từ nhà cung cấp (ví dụ AWS bị downtime). Kết quả là hệ thống phản hồi khách hàng bị tê liệt trong nhiều giờ, ảnh hưởng đến trải nghiệm và uy tín thương hiệu.
4. Tích hợp phần mềm
Mô tả: Để AI agents hoạt động hiệu quả, chúng cần tích hợp liền mạch với các hệ thống hiện tại như CRM, ERP, HRM, v.v. Tuy nhiên, sự khác biệt về kiến trúc hệ thống, giao thức truyền thông hoặc độ tương thích có thể tạo ra rào cản lớn cho việc tích hợp.
Ví dụ: Một công ty muốn tích hợp AI để tự động tạo và gửi hóa đơn thông qua hệ thống kế toán cũ. Tuy nhiên, hệ thống hiện tại không hỗ trợ API hoặc không tương thích với mô hình AI hiện có, buộc phải xây dựng cầu nối trung gian tốn kém và mất thời gian.
III. Các vấn đề thực hiện
Triển khai AI Agents trong môi trường doanh nghiệp không chỉ đơn thuần là việc đưa một công nghệ mới vào hệ thống hiện có — đó là một quá trình phức tạp đòi hỏi sự chuẩn bị kỹ lưỡng về quy trình, hạ tầng và con người. Những thách thức này bắt đầu từ việc xác định rõ quy trình mà AI sẽ tham gia, cho đến việc tích hợp AI với các hệ thống hiện hành. Bảo mật dữ liệu là mối quan tâm hàng đầu, đặc biệt khi AI xử lý thông tin nhạy cảm. Đồng thời, AI cần có sự giám sát của con người để đảm bảo hoạt động đúng định hướng và phù hợp với giá trị đạo đức. Ngoài ra, việc duy trì tính công bằng, không dư thừa dữ liệu và đảm bảo khả năng mở rộng, bảo trì lâu dài cũng là những yếu tố sống còn cho sự thành công của AI trong thực tế.
1. Định nghĩa qui trình
Mô tả: Trước khi triển khai AI agent, doanh nghiệp cần xác định rõ quy trình nào sẽ được tự động hóa hoặc hỗ trợ. Thiếu định nghĩa quy trình rõ ràng sẽ khiến AI hoạt động không hiệu quả, chồng chéo với công việc con người hoặc gây gián đoạn vận hành.
Ví dụ: Một công ty muốn dùng AI để xử lý yêu cầu hỗ trợ khách hàng, nhưng không xác định rõ khi nào AI nên chuyển tiếp cho nhân viên thật. Hậu quả là AI giữ khách hàng quá lâu hoặc chuyển không đúng lúc, gây bất mãn.
2. Tích hợp
Mô tả: AI agents cần được tích hợp liền mạch vào hệ thống hiện có (CRM, ERP, website, v.v.). Quá trình này thường gặp khó khăn do không tương thích, thiếu API, hoặc kiến trúc phần mềm cũ.
Ví dụ: Một bệnh viện triển khai AI hỗ trợ đọc kết quả chụp X-quang, nhưng hệ thống AI không kết nối được với phần mềm lưu trữ hồ sơ bệnh án (EMR), khiến nhân viên phải nhập tay kết quả → chậm trễ và sai sót.
3. Bảo mật dữ liệu
Mô tả: AI agents cần truy cập và xử lý dữ liệu nhạy cảm như thông tin cá nhân, tài chính, y tế,… Nếu không được bảo vệ tốt, đây sẽ là lỗ hổng nghiêm trọng về bảo mật.
Ví dụ: Một AI hỗ trợ kế toán nội bộ bị khai thác qua API không được bảo mật, khiến dữ liệu lương và hợp đồng nhân sự bị rò rỉ ra bên ngoài.
4. Giám sát của con người
Mô tả: AI cần được giám sát bởi con người để đảm bảo hoạt động đúng, tránh lỗi hệ thống hoặc đưa ra quyết định không phù hợp. Thiếu giám sát có thể gây hậu quả nghiêm trọng, nhất là trong các ngành nhạy cảm.
Ví dụ: Một AI phỏng vấn tuyển dụng tự động loại bỏ nhiều ứng viên chỉ vì giọng nói địa phương, nhưng không có người kiểm tra lại các tiêu chí đánh giá → dẫn đến mất ứng viên chất lượng và phản ứng tiêu cực.
5. Mối quan tâm về đạo đức và thiên vị
Mô tả: AI có thể vô tình tái tạo hoặc khuếch đại các định kiến từ dữ liệu huấn luyện. Nếu không được kiểm soát, AI có thể đưa ra các quyết định phân biệt đối xử hoặc phi đạo đức.
Ví dụ: Một AI phân tích hồ sơ vay vốn học tập lại có xu hướng ưu tiên người từ khu vực đô thị hơn nông thôn, vì mô hình học từ dữ liệu lịch sử thiếu công bằng → gây bất bình đẳng xã hội.
6. Khả năng mở rộng và bảo trì
Mô tả: AI agent ban đầu có thể chạy tốt, nhưng khi số lượng người dùng hoặc dữ liệu tăng lên, hệ thống có thể bị quá tải nếu không được thiết kế để mở rộng. Đồng thời, AI cần được cập nhật và bảo trì định kỳ.
Ví dụ: Một cửa hàng online dùng AI để gợi ý sản phẩm. Trong mùa sale, lượng truy cập tăng gấp 10 lần khiến AI đưa ra đề xuất sai hoặc đứng hệ thống → làm mất doanh thu và trải nghiệm khách hàng.
III. Các nhà cung cấp chi phối thị trường
Thị trường hiện tại lại đang bị chi phối bởi một số rào cản lớn có thể cản trở khả năng phát triển và triển khai của các doanh nghiệp. Những thách thức này bao gồm sự thống trị của các nhà cung cấp lớn (dominant providers), các thỏa thuận độc quyền (exclusivity agreements), và sự kiểm soát chặt chẽ từ các nền tảng di động như hệ điều hành và chợ ứng dụng (mobile OS and app stores). Những yếu tố này không chỉ làm hạn chế sự lựa chọn công nghệ, mà còn ảnh hưởng đến khả năng tiếp cận, phân phối và sáng tạo trong không gian AI. Do đó, các doanh nghiệp muốn ứng dụng AI Agents cần hiểu rõ môi trường thị trường để xây dựng chiến lược thích nghi phù hợp và giảm thiểu rủi ro phụ thuộc.
1. Các nhà cung cấp chi phối thị trường
Mô tả: Thị trường AI hiện đang bị thống trị bởi một số ít công ty lớn như OpenAI, Google, Microsoft, Anthropic... Họ kiểm soát các mô hình AI nền tảng, hạ tầng tính toán và API, khiến doanh nghiệp nhỏ phụ thuộc và thiếu lựa chọn.
Ví dụ: Một công ty khởi nghiệp muốn xây dựng AI agent nội bộ nhưng buộc phải phụ thuộc vào GPT của OpenAI vì không đủ nguồn lực huấn luyện mô hình riêng. Khi OpenAI tăng giá API hoặc thay đổi chính sách, công ty này không có phương án thay thế.
2. Thỏa thuận độc quyền
Mô tả: Một số công ty công nghệ lớn ký thỏa thuận độc quyền với các nhà cung cấp AI, giới hạn quyền truy cập hoặc tích hợp vào nền tảng của đối thủ, khiến thị trường bị khóa và cản trở đổi mới.
Ví dụ: Microsoft ký thỏa thuận độc quyền tích hợp GPT vào các sản phẩm Microsoft 365. Một đối thủ trong lĩnh vực phần mềm văn phòng không thể tích hợp cùng mức độ hoặc chức năng tương đương, dẫn đến mất lợi thế cạnh tranh.
3. Hệ điều hành và cửa hàng ứng dụng di động
Mô tả: Các nền tảng như iOS (Apple) và Android (Google) kiểm soát chặt chẽ hệ sinh thái ứng dụng, bao gồm quyền truy cập vào phần cứng, dữ liệu người dùng, và cả phân phối ứng dụng. Việc đưa AI agent lên điện thoại gặp rào cản chính sách, giới hạn kỹ thuật hoặc chia sẻ doanh thu.
Ví dụ: Một startup phát triển AI agent tương tác bằng giọng nói cho thiết bị di động, nhưng Apple không cho phép quyền truy cập toàn phần vào micro hoặc Siri. Ngoài ra, ứng dụng phải chia 30% doanh thu cho Apple nếu bán qua App Store.
IV. Quản trị AI Agents
Quản trị(Governance) trong lĩnh vực AI đề cập đến việc xây dựng các cơ chế, chính sách, luật pháp và quy trình nhằm đảm bảo rằng các hệ thống AI – bao gồm cả AI Agents – được phát triển, triển khai và vận hành một cách an toàn, minh bạch, có trách nhiệm và tuân thủ đạo đức.
Khi AI Agents ngày càng trở nên tự chủ và mạnh mẽ, việc quản trị chúng không còn là một lựa chọn, mà là điều bắt buộc để ngăn ngừa rủi ro và bảo vệ lợi ích xã hội, doanh nghiệp và cá nhân.
1. Quy định pháp lý
Mô tả: Các luật lệ và quy định từ chính phủ hoặc cơ quan quốc tế nhằm kiểm soát cách AI được thiết kế, triển khai và sử dụng.
Ví dụ:
-
Liên minh Châu Âu ban hành AI Act, yêu cầu các hệ thống AI có mức rủi ro cao phải được kiểm tra nghiêm ngặt về an toàn, độ tin cậy và quyền riêng tư.
-
Ở Việt Nam, nếu AI Agent xử lý dữ liệu cá nhân nhạy cảm mà không tuân thủ Luật An ninh mạng hoặc Luật Bảo vệ dữ liệu cá nhân (dự thảo), doanh nghiệp có thể bị xử phạt.
2. Tiêu chuẩn kỹ thuật
Mô tả: Các hướng dẫn và tiêu chuẩn chung để thiết kế, phát triển và đánh giá AI một cách nhất quán, minh bạch và có thể kiểm chứng.
Ví dụ:
-
ISO/IEC 42001 là tiêu chuẩn quốc tế mới cho hệ thống quản lý AI.
-
Doanh nghiệp xây dựng AI Agent theo chuẩn IEEE P7001 để đảm bảo tính minh bạch trong thuật toán ra quyết định.
3. Cơ chế trách nhiệm
Mô tả: Xác định rõ ai chịu trách nhiệm khi AI Agent gây ra sự cố hoặc hành vi sai lệch. Điều này giúp doanh nghiệp không "đổ lỗi cho AI" mà phải gắn trách nhiệm với con người hoặc tổ chức cụ thể.
Ví dụ:
Nếu một AI Agent từ chối đơn bảo hiểm sai do lỗi thuật toán, công ty bảo hiểm cần có bộ phận chịu trách nhiệm xử lý khiếu nại, sửa lỗi hệ thống, và bồi thường nếu cần.
4. Yêu cầu minh bạch
Mô tả: Các AI Agent cần minh bạch trong hoạt động của mình: chúng đưa ra quyết định như thế nào, sử dụng dữ liệu gì, và người dùng có thể hiểu (hoặc kiểm tra) quá trình đó.
Ví dụ:
Một AI Agent gợi ý sản phẩm trên sàn thương mại điện tử cần nêu rõ lý do: "Sản phẩm này được đề xuất vì bạn đã mua các sản phẩm tương tự trong 30 ngày qua".
5. Hợp tác liên ngành
Mô tả: Các tổ chức, doanh nghiệp, cơ quan chính phủ và giới học thuật cần phối hợp cùng nhau để đảm bảo AI phát triển một cách cân bằng, bền vững, và toàn diện.
Ví dụ:
-
Một AI Agent hỗ trợ chẩn đoán y tế cần được xây dựng với sự hợp tác giữa công ty công nghệ, bệnh viện, bộ y tế và các tổ chức đạo đức để đảm bảo tính chính xác, an toàn và nhân đạo.
-
Trong lĩnh vực tài chính, ngân hàng cần hợp tác với các chuyên gia pháp lý và công nghệ để triển khai AI tuân thủ các quy định chống rửa tiền (AML) và biết khách hàng (KYC).
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Yêu cầu pháp lý (Regulatory) trong xây dựng AI Agents:
-
Đảm bảo thị trường cạnh tranh và thúc đẩy đổi mới sáng tạo
Tránh độc quyền công nghệ, tạo môi trường để các công ty nhỏ và startup cũng có cơ hội tham gia và sáng tạo AI Agents. -
Đảm bảo quyền riêng tư và bảo mật dữ liệu
AI Agents cần tuân thủ nghiêm ngặt các quy định về bảo vệ dữ liệu cá nhân, tránh thu thập hoặc xử lý dữ liệu nhạy cảm một cách trái phép. -
Bảo vệ quyền sở hữu trí tuệ
Các mô hình AI không được sao chép hoặc tái sử dụng nội dung, phần mềm, hoặc dữ liệu của bên thứ ba mà không có sự cho phép hợp pháp. -
Ngăn chặn thông tin sai lệch, đe doạ mạng và lạm dụng AI
AI Agents không được trở thành công cụ phát tán tin giả, tấn công mạng, hoặc bị sử dụng cho các mục đích độc hại như deepfake hoặc lừa đảo. -
Giảm thiểu tác động môi trường và đảm bảo phát triển bền vững
Khuyến khích phát triển các mô hình AI tiết kiệm năng lượng, tối ưu hóa tính toán và giảm phát thải carbon. -
Hạn chế sự thiên lệch (bias)
Đảm bảo AI Agents không tạo ra hoặc tái tạo định kiến giới, chủng tộc, địa lý, hoặc xã hội trong quá trình xử lý dữ liệu hay ra quyết định. -
Đảm bảo tính minh bạch và cơ chế giải trình
Người dùng và tổ chức phải hiểu được cách AI Agents hoạt động, đưa ra quyết định và có thể kiểm tra, truy xuất nguồn gốc kết quả nếu cần. -
Bồi thường thiệt hại do mất việc làm và tác động kinh tế tiêu cực
Khi AI thay thế công việc truyền thống, cần có chính sách hỗ trợ đào tạo lại lao động, phân phối lại lợi ích một cách công bằng. -
Cân bằng giữa đổi mới công nghệ và trách nhiệm xã hội
Khuyến khích phát triển AI nhanh chóng nhưng không đánh đổi các giá trị đạo đức, quyền con người và lợi ích cộng đồng.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Sự hiện hữu của AI Agents
1. Từ bản demo đến sản phẩm thực tế (From Demos to Products)
-
AI Agents không còn bị giới hạn trong các thử nghiệm phòng lab. Trước đây, AI Agents chủ yếu là mô hình thử nghiệm mang tính nghiên cứu. Hiện nay, chúng đang được triển khai thực tế để giải quyết vấn đề cụ thể trong doanh nghiệp như chăm sóc khách hàng, xử lý đơn hàng, tự động hóa công việc nội bộ.
-
Ví dụ: Một AI Agent giúp xử lý email khách hàng tự động đã không còn là thử nghiệm – nó đang hoạt động tại các trung tâm hỗ trợ thực tế.
2. Tăng tốc triển khai (Acceleration)
-
Việc ứng dụng AI Agents sẽ diễn ra nhanh chóng khi nhiều tổ chức nhận ra giá trị của chúng. Doanh nghiệp nào áp dụng AI Agents sớm (early adopters) sẽ có lợi thế cạnh tranh nhờ tối ưu chi phí, cải thiện năng suất và đổi mới sản phẩm nhanh hơn.
3. Mở rộng các tình huống ứng dụng (Expansion of use cases)
-
Các lĩnh vực khác nhau sẽ ngày càng áp dụng AI Agents, không chỉ giới hạn trong công nghệ hay tài chính, AI Agents sẽ xuất hiện trong giáo dục, logistics, y tế, sản xuất, dịch vụ công, v.v.
4. Kết hợp với công nghệ mới nổi (With Emerging Tech)
-
AI Agents sẽ được tích hợp với các công nghệ khác như IoT, Blockchain, Robot, AR/VR, 5G để tạo ra những giải pháp thông minh mạnh mẽ và tương tác tốt hơn.
-
Ví dụ: Một AI Agent trong dây chuyền sản xuất có thể kết nối với cảm biến IoT để tự động phát hiện lỗi kỹ thuật.
5. Cuộc cách mạng lực lượng lao động (Workforce Revolution)
-
AI Agents sẽ thay đổi cách con người làm việc, giúp tự động hóa các công việc lặp đi lặp lại và tạo điều kiện để nhân viên tập trung vào các nhiệm vụ sáng tạo, chiến lược hơn.
-
Ví dụ: Thay vì xử lý thủ công hàng trăm đơn hàng, nhân viên chỉ cần giám sát AI Agent làm việc đó và đưa ra quyết định cuối cùng.
6. Đối tác cộng tác thông minh (Collaborative Partners)
-
AI Agents không phải thay thế con người, mà sẽ trở thành trợ lý kỹ thuật số hợp tác để nâng cao hiệu suất công việc.
7. Đội nhóm lai (Hybrid Teams)
-
Doanh nghiệp trong tương lai sẽ có các nhóm làm việc "lai", nơi con người và AI Agents cùng tham gia xử lý công việc – mỗi bên phát huy thế mạnh của mình.
-
Ví dụ: Một nhóm marketing có thể bao gồm 3 nhân viên và 1 AI Agent chuyên tổng hợp dữ liệu thị trường mỗi ngày.
8. Thị trường AI Agent (AI Agent Marketplaces)
-
Sẽ có các nền tảng cho phép doanh nghiệp tìm mua, thuê hoặc chia sẻ AI Agents đã được huấn luyện sẵn theo từng lĩnh vực.
-
Ví dụ: Bạn có thể truy cập marketplace để tải về một AI Agent chuyên về hỗ trợ pháp lý hoặc chăm sóc khách hàng bằng tiếng Việt.
9. Khuyến nghị (Recommendations)
Để chuẩn bị cho tương lai này, các tổ chức nên:
-
Training: Đào tạo đội ngũ về kỹ năng AI cơ bản và ứng dụng AI Agents.
-
Experiment: Bắt đầu thử nghiệm AI Agents trong một vài quy trình nhỏ.
-
Optimize Costs: Lựa chọn giải pháp AI phù hợp với ngân sách, tối ưu chi phí khi triển khai.
10. Sự phát triển công nghệ (Tech Evolution)
-
Hạ tầng phần cứng, mô hình ngôn ngữ lớn (LLMs), điện toán biên, GPU… sẽ tiếp tục phát triển, giúp AI Agents ngày càng thông minh, nhanh và đáng tin cậy hơn.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Cách Xây Dựng AI AGENTS Chuyên Nghiệp
Hướng dẫn dành cho các tổ chức, doanh nghiệp và nhà phát triển muốn khai thác tối đa tiềm năng của AI Agents. Bài viết sẽ giúp bạn hiểu rõ các yếu tố cốt lõi trong thiết kế, triển khai và quản trị AI Agents một cách bài bản. Từ chiến lược công nghệ đến yếu tố đạo đức và vận hành, đây là nền tảng để xây dựng các tác nhân AI hiệu quả, an toàn và đáng tin cậy.
Xây Dựng AI Agents Chuyên Nghiệp với LangGraph
Trong hành trình này, bạn sẽ được học cách xây dựng các AI Agent hiện đại bằng LangGraph – một công cụ mạnh mẽ đang thay đổi cách chúng ta tạo ra các hệ thống AI tương tác. Khóa học được thiết kế từ cơ bản đến nâng cao, từng bước hướng dẫn bạn vượt qua những khó khăn ban đầu, để rồi làm chủ những mô hình phức tạp, thực tế và hiệu quả.
Bài học thực chiến với ví dụ chi tiết
Agent, Assistant và Message
Trong LangChain, các loại Message đóng vai trò rất quan trọng khi làm việc với các mô hình như ChatOpenAI, nhất là khi xây dựng các hệ thống hội thoại (conversational agents). Những message này mô phỏng cách người và AI giao tiếp với nhau trong một cuộc trò chuyện.
Giới thiệu
Trong LangChain, Message là thành phần cốt lõi dùng để mô tả các tương tác giữa người dùng, hệ thống và mô hình ngôn ngữ (LLM). Việc hiểu rõ các loại Message giúp bạn xây dựng các tác vụ hội thoại, agent, và ứng dụng AI một cách chính xác, dễ kiểm soát và có thể mở rộng.
LangChain định nghĩa nhiều loại message khác nhau, mỗi loại phản ánh một vai trò cụ thể trong quá trình giao tiếp. Dưới đây là tổng quan các loại message chính:
1. HumanMessage – Tin nhắn từ người dùng
Đây là loại message đại diện cho đầu vào từ người dùng cuối. Khi bạn nhập văn bản để hỏi AI, LangChain sẽ đóng gói nội dung đó thành một HumanMessage.
from langchain.schema import HumanMessage
message = HumanMessage(content="Bạn có thể giúp tôi tính 5 nhân 3 không?")Dùng khi mô phỏng hoặc truyền input từ con người.
2. AIMessage – Phản hồi từ AI
Đại diện cho phản hồi từ LLM, thường là kết quả sau khi xử lý HumanMessage. Ngoài văn bản, AIMessage còn có thể bao gồm tool calls, nếu AI quyết định gọi một công cụ thay vì trả lời trực tiếp.
from langchain.schema import AIMessage
message = AIMessage(content="Kết quả là 15.")Dùng để mô tả output từ AI.
3. SystemMessage – Định hướng AI
Được dùng để thiết lập bối cảnh hoặc hướng dẫn hành vi của AI từ đầu. Những chỉ dẫn như “bạn là một trợ lý thân thiện” hay “chỉ trả lời bằng tiếng Việt” thường được đặt trong SystemMessage.
from langchain.schema import SystemMessage
message = SystemMessage(content="Bạn là một trợ lý AI chuyên nghiệp.")Dùng để hướng dẫn mô hình trước khi bắt đầu cuộc trò chuyện.
4. ToolMessage – Phản hồi từ công cụ (tool)
Khi một AI gọi tool (hàm toán học, API, công cụ bên ngoài…), kết quả trả về sẽ được biểu diễn qua ToolMessage. Nó mô tả output của tool, và giúp AI tiếp tục hội thoại dựa trên dữ liệu đó.
from langchain.schema import ToolMessage
message = ToolMessage(
tool_call_id="abc123",
content="Kết quả của phép chia là 2.5"
)
Dùng khi bạn có workflow với tool calling.
5. ToolCall – Yêu cầu từ AI gọi một tool
Không phải là message, nhưng thường được gói trong AIMessage. Khi AI muốn gọi một hàm cụ thể, nó tạo ra một ToolCall để mô tả tên tool và các tham số truyền vào.
from langchain.schema.messages import ToolCall
call = ToolCall(
name="multiply",
args={"a": 5, "b": 3},
id="tool_call_1"
)Gắn liền với quá trình sử dụng bind_tools() hoặc khi xây dựng các agent có tool.
Tóm lại
| Message Type | Vai trò chính | Dùng khi nào? |
|---|---|---|
HumanMessage |
Người dùng gửi yêu cầu | Mọi input của người dùng |
AIMessage |
AI phản hồi hoặc gọi tool | Output từ AI |
SystemMessage |
Thiết lập bối cảnh và hành vi AI | Trước khi bắt đầu cuộc trò chuyện |
ToolMessage |
Phản hồi từ công cụ (tool) | Khi một tool được AI gọi và trả về kết quả |
ToolCall |
(Không phải message) – Gọi hàm/tool | Khi AI quyết định gọi tool thay vì trả lời |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Assistant và Agent
I. Assistant là gi?
Assistant trong thường là một hệ thống AI đơn lẻ được thiết kế để thực hiện các nhiệm vụ cụ thể, thường làm việc theo prompt cố định: ví dụ nhận input, trả lời output, không linh hoạt nhiều.
Trong nhiều dự án, bạn thấy "Assistant" = "OpenAI Assistant", tức là chỉ một chatbot đơn giản trả lời tin nhắn.
-
Đặc điểm:
-
Thường là single-purpose (mục đích đơn lẻ)
-
Có phạm vi hoạt động hẹp và xác định rõ
-
Hoạt động theo luồng cố định (fixed workflow)
-
Ít khả năng ra quyết định phức tạp
-
-
Ví dụ: Một assistant trả lời FAQ, assistant lập lịch họp, assistant dịch thuật
Dùng Assistant khi:
-
Bạn cần giải pháp nhanh cho vấn đề đơn giản
-
Workflow cố định và predictable (có thể dự đoán)
-
Không cần tích hợp nhiều công cụ bên ngoài
Kiến trúc Assistant:
User Input → [Assistant] → Output
VÍ dụ
-
Bạn hỏi: "Hôm nay thời tiết thế nào?"
-
Nó trả lời ngay: "Hôm nay trời nắng tại Hà Nội."
II. Agent là gì
Agent là một khái niệm nâng cao hơn với nhiều khả năng phức tạp:
-
Đặc điểm:
-
Có agency (khả năng tự quyết định hành động)
-
Có thể sử dụng tools (công cụ bên ngoài)
-
Có trạng thái (state) được duy trì
-
Có thể học và thích nghi
-
Thường có feedback loop (vòng lặp phản hồi)
-
-
Ví dụ: Agent nghiên cứu tự động, agent giao dịch chứng khoán, agent hỗ trợ phát triển phần mềm
Agent là một thực thể (entity) có thể:
-
-
Nhận đầu vào (input),
-
Xử lý logic riêng,
-
Quyết định hành động (ví dụ: gọi API, chọn công cụ, tính toán, suy luận, trả lời),
-
Và trả ra đầu ra (output).
-
Agent thường tự động làm việc, có trí thông minh riêng tùy theo mục đích lập trình cho nó thế nào.
Ví dụ Agent:
-
-
Bạn hỏi: "Hôm nay thời tiết thế nào?"
-
Nó suy nghĩ: "Tôi nên tra cứu API thời tiết → lấy dữ liệu → xử lý → trả lời."
-
Thậm chí nếu lỗi API, nó có thể chọn hỏi lại bạn địa điểm, hoặc thử cách khác.
-
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
HumanMessage – Tin nhắn từ người dùng
Trong LangChain, HumanMessage là một trong những loại message cơ bản nhất, đại diện cho lời nói, câu hỏi hoặc yêu cầu từ người dùng trong cuộc trò chuyện với mô hình ngôn ngữ (LLM).
Khi bạn gọi mô hình bằng ChatModel như ChatOpenAI, bạn có thể truyền vào một danh sách các message. HumanMessage mô phỏng nội dung do con người nhập vào — tương đương với việc bạn gõ câu hỏi vào ChatGPT.
Cú pháp khai báo
from langchain.schema import HumanMessage
message = HumanMessage(content="Hôm nay thời tiết thế nào?")-
content: là văn bản người dùng gửi. -
Có thể dùng thêm
namenếu bạn muốn đặt tên cho người gửi (không bắt buộc).
Ví dụ đơn giản sử dụng với ChatOpenAI
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
# Khởi tạo mô hình
llm = ChatOpenAI()
# Tạo HumanMessage
user_message = HumanMessage(content="Hãy tính giúp tôi 7 + 5 là bao nhiêu?")
# Gửi message đến mô hình và in kết quả
response = llm([user_message])
print(response.content)
Kết quả có thể là:7 + 5 = 12.
Dùng nhiều messages trong cuộc hội thoại
from langchain.schema import HumanMessage, AIMessage, SystemMessage
from langchain.chat_models import ChatOpenAI
chat = ChatOpenAI()
messages = [
SystemMessage(content="Bạn là một trợ lý AI thông minh và lịch sự."),
HumanMessage(content="Bạn tên là gì?"),
AIMessage(content="Tôi là trợ lý AI được thiết kế để hỗ trợ bạn."),
HumanMessage(content="Bạn có thể dịch câu 'Hello' sang tiếng Việt không?")
]
response = chat(messages)
print(response.content)
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
AIMessage – Tin nhắn phản hồi từ AI
Trong LangChain, AIMessage đại diện cho phản hồi từ mô hình ngôn ngữ (LLM) sau khi nhận một hoặc nhiều HumanMessage.
Bạn có thể nghĩ nó giống như câu trả lời mà ChatGPT gửi lại sau khi bạn hỏi.
LangChain cho phép bạn truyền danh sách các message vào mô hình — trong đó AIMessage giúp mô phỏng những phản hồi trước đó từ AI để giữ ngữ cảnh hội thoại.
Cú pháp khai báo
from langchain.schema import AIMessage
message = AIMessage(content="Tôi có thể giúp gì cho bạn hôm nay?")-
content: là nội dung phản hồi của AI. -
Cũng có thể dùng thêm
name, nhưng thường không cần vì AI chỉ có 1 vai trò chính.
Ví dụ sử dụng với ChatOpenAI
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, AIMessage
chat = ChatOpenAI()
messages = [
HumanMessage(content="Bạn tên là gì?"),
AIMessage(content="Tôi là trợ lý ảo của bạn."),
HumanMessage(content="Bạn có thể giúp tôi dịch từ 'apple' sang tiếng Việt không?")
]
response = chat(messages)
print(response.content)Kết quả có thể là:
"Từ 'apple' trong tiếng Việt là 'quả táo'."
Sử dụng trong hội thoại nhiều lượt (multi-turn conversation)
from langchain.schema import HumanMessage, AIMessage, SystemMessage
messages = [
SystemMessage(content="Bạn là trợ lý lịch sự, trả lời bằng tiếng Việt."),
HumanMessage(content="Xin chào!"),
AIMessage(content="Chào bạn! Tôi có thể giúp gì hôm nay?"),
HumanMessage(content="Thời tiết hôm nay như thế nào ở Hà Nội?")
]
Bạn có thể gửi messages này vào ChatOpenAI() để giữ toàn bộ ngữ cảnh từ đầu đến cuối.
AIMessage sử dụng trong những trường hợp
-
Khi bạn lưu trữ phản hồi của AI trong một cuộc trò chuyện và muốn phát lại sau này.
-
Khi bạn cần thêm bối cảnh vào lời nhắc (prompt) hiện tại để mô hình hiểu mạch hội thoại.
-
Khi bạn muốn mô phỏng lại các cuộc đối thoại giữa người dùng và AI.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
SystemMessage - Thiết lập ngữ cảnh
Trong LangChain, SystemMessage là một loại message đặc biệt dùng để thiết lập ngữ cảnh hoặc hướng dẫn hành vi cho mô hình ngôn ngữ (LLM).
Nó giống như "lệnh nền" mà người dùng không thấy, nhưng ảnh hưởng đến cách AI trả lời.
Cú pháp
from langchain.schema import SystemMessage
system_msg = SystemMessage(content="Bạn là một trợ lý AI nói tiếng Việt và luôn lịch sự.")-
content: Văn bản chỉ dẫn cho mô hình. -
Không hiển thị với người dùng cuối, nhưng cực kỳ quan trọng để định hình cá tính và hành vi của AI.
Mục đích sử dụng
-
Thiết lập vai trò cho AI (ví dụ: giáo viên, chuyên gia, chatbot vui vẻ...).
-
Quy định giọng điệu (ví dụ: lịch sự, vui vẻ, nghiêm túc).
-
Áp đặt giới hạn, như "không trả lời nếu không chắc chắn".
Ví dụ đơn giản
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage, SystemMessage
llm = ChatOpenAI()
messages = [
SystemMessage(content="Bạn là một trợ lý AI lịch sự và vui tính."),
HumanMessage(content="Hôm nay bạn khỏe không?")
]
response = llm(messages)
print(response.content)Kết quả có thể là
Cảm ơn bạn đã hỏi! Tôi là AI nên không có cảm giác, nhưng nếu có thì chắc chắn hôm nay tôi rất tuyệt vời. Còn bạn thì sao?Thấy không? AI trở nên "vui tính" và "lịch sự" đúng như chỉ dẫn trong SystemMessage.
Ví dụ hội thoại có nhiều loại message
from langchain.schema import HumanMessage, AIMessage, SystemMessage
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI()
messages = [
SystemMessage(content="Bạn là một chuyên gia lịch sử Việt Nam, nói ngắn gọn."),
HumanMessage(content="Ai là vua đầu tiên của triều Nguyễn?"),
]
response = llm(messages)
print(response.content)Kết quả mẫu:
Vua đầu tiên của triều Nguyễn là Gia Long, lên ngôi năm 1802.Mẹo chuyên sâu
-
SystemMessagenên luôn được đặt đầu tiên trong danh sách messages. -
Nếu dùng
memory, bạn có thể thêmSystemMessagemột lần duy nhất để mô hình nhớ bối cảnh trong suốt cuộc trò chuyện. -
Bạn có thể sử dụng
SystemMessageđể giới hạn độ dài, độ chính xác, hoặc hành vi không mong muốn của AI. -
Muốn ví dụ sử dụng
SystemMessageđể tạo các kiểu AI khác nhau như:-
Trợ lý thân thiện
-
Chuyên gia tài chính
-
Luật sư
-
Dịch giả tự động
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft -
ToolMessage - Kết quả phản hồi từ một công cụ (tool)
Trong LangChain, ToolMessage đại diện cho kết quả phản hồi từ một công cụ (tool) sau khi mô hình LLM gọi tool đó.
Nó giống như AI bảo: "Tôi cần dùng máy tính để tính 2 + 2", sau đó bạn gửi lại kết quả "4" bằng
ToolMessage.
Khi nào dùng ToolMessage?
Khi bạn dùng bind_tools() để cho phép LLM gọi các hàm (tools), LangChain sẽ:
-
LLM tạo một ToolCall (ví dụ: gọi hàm
multiply(a=2, b=3)). -
Bạn thực thi hàm Python tương ứng.
-
Sau đó, bạn dùng
ToolMessageđể truyền kết quả trả về của tool đó lại cho LLM.
Cú pháp
from langchain_core.messages import ToolMessage
msg = ToolMessage(tool_call_id="abc123", content="Kết quả là 6")Các tham số:
| Tham số | Ý nghĩa |
|---|---|
tool_call_id |
ID của lời gọi hàm (do ToolCallMessage sinh ra) |
content |
Nội dung trả lời (kết quả của tool) |
Ví dụ đầy đủ: Gọi hàm nhân trong Python
1. Định nghĩa hàm (tool)
def multiply(a: int, b: int) -> int:
"""Nhân hai số."""
return a * b2. Dùng LLM + tool
from langchain_core.messages import HumanMessage, ToolMessage
from langchain_openai import ChatOpenAI
chat = ChatOpenAI().bind_tools([multiply], parallel_tool_calls=False)3. LLM đưa ra ToolCall
messages = [
HumanMessage(content="Hãy nhân 4 với 5")
]
response = chat.invoke(messages)
tool_call = response.tool_calls[0]
print(tool_call) # --> thông tin về lời gọi hàm multiply
4. Gửi kết quả về lại cho LLM bằng ToolMessage
# Gọi hàm thủ công
result = multiply(**tool_call.args)
# Gửi kết quả về lại
followup = chat.invoke([
response,
ToolMessage(tool_call_id=tool_call.id, content=str(result))
])
print(followup.content) # => LLM phản hồi dựa trên kết quả toolQuan trọng
-
ToolMessagecực kỳ quan trọng khi bạn dùng nhiều bước logic có liên quan đến tool. -
tool_call_idphải khớp chính xác vớiToolCallMessagetừ LLM, để LLM biết bạn đang trả lời cho yêu cầu nào. -
Bạn có thể dùng nhiều
ToolMessagenếu LLM gọi nhiều hàm cùng lúc (nếuparallel_tool_calls=True).
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
ToolCall - Mô hình ngôn ngữ gọi đến một công cụ
Trong LangChain, ToolCall đại diện cho việc mô hình ngôn ngữ gọi đến một công cụ (function) để thực hiện một hành động cụ thể.
Nói cách khác, khi bạn dạy AI cách gọi các hàm Python, thì
ToolCalllà cách mô hình nói: “Tôi muốn dùng hàmadd(5, 3)nhé.”
Tại sao cần ToolCall?
Mô hình ngôn ngữ rất giỏi hiểu và tạo ra văn bản, nhưng lại không giỏi tính toán, truy vấn API, hoặc thao tác với dữ liệu phức tạp.
Khi cần làm những việc như vậy, mô hình sẽ gọi một “tool” (được định nghĩa trước bằng Python), thông qua một ToolCall.
Cấu trúc cơ bản của ToolCall
from langchain_core.messages import ToolCall
tool_call = ToolCall(
name="multiply",
args={"a": 5, "b": 3},
id="call_123"
)Các thành phần:
-
name: tên hàm (tool) mà AI muốn gọi (giống với tên bạn đăng ký khi dùngbind_tools). -
args: tham số truyền vào cho hàm đó. -
id: mã định danh của tool call (thường là tự sinh).
Ví dụ đầy đủ: Sử dụng ToolCall với LLM
Bước 1: Định nghĩa công cụ
def add(a: int, b: int) -> int:
return a + bBước 2: Bind tool vào LLM
from langchain_openai import ChatOpenAI
llm = ChatOpenAI(model="gpt-4o")
llm_with_tools = llm.bind_tools([add])
Bước 3: Gửi tin nhắn có yêu cầu tính toán
from langchain_core.messages import HumanMessage
messages = [HumanMessage(content="Hãy cộng 4 và 7 giúp tôi")]
response = llm_with_tools.invoke(messages)
print(response.tool_calls) # Đây chính là danh sách ToolCall
[
ToolCall(
name='add',
args={'a': 4, 'b': 7},
id='toolu_abc123'
)
]
Tức là mô hình quyết định gọi hàm add với a=4, b=7 thông qua ToolCall.
Tương tác hoàn chỉnh: Gọi Tool và trả lại kết quả
from langchain_core.messages import AIMessage, ToolMessage
# Gọi hàm add
tool_result = add(4, 7)
# Trả kết quả lại cho AI thông qua ToolMessage
final_response = llm_with_tools.invoke([
HumanMessage(content="Hãy cộng 4 và 7"),
AIMessage(tool_calls=[ToolCall(name="add", args={"a": 4, "b": 7}, id="call_1")]),
ToolMessage(tool_call_id="call_1", content=str(tool_result))
])
print(final_response.content)Output
Kết quả là 11!Tóm tắt so sánh
| Thành phần | Vai trò |
|---|---|
ToolCall |
Yêu cầu gọi hàm từ mô hình LLM |
ToolMessage |
Trả kết quả từ tool về để LLM tiếp tục xử lý |
bind_tools |
Cho LLM biết có thể gọi những hàm nào |
Khi nào cần dùng ToolCall?
-
Khi mô hình phải tính toán, xử lý logic cụ thể, hoặc truy vấn dữ liệu thật.
-
Khi xây dựng chatbot có khả năng "hành động", như đặt lịch, gọi API, v.v.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Giới thiệu về LangGraph
Dưới đây là một bài viết giới thiệu về LangGraph, được trình bày theo kiểu bài viết chia sẻ kiến thức công nghệ, phù hợp cho tài liệu kỹ thuật.
Giới thiệu về LangGraph
LangGraph Tạo LLM Workflow dễ dàng như vẽ đồ thị
Trong thời đại của trí tuệ nhân tạo và mô hình ngôn ngữ lớn (LLM), việc xây dựng các workflow phức tạp để xử lý ngôn ngữ tự nhiên đang trở nên ngày càng quan trọng. Tuy nhiên, quản lý các chuỗi tác vụ, rẽ nhánh logic, và vòng lặp trong quá trình tương tác với LLM có thể nhanh chóng trở nên phức tạp. Đây chính là lý do LangGraph ra đời.
LangGraph là gì?
LangGraph là một thư viện mã nguồn mở được phát triển dựa trên LangChain, cho phép bạn xây dựng các đồ thị trạng thái (stateful graphs) cho các ứng dụng sử dụng LLM. Thay vì chỉ chạy một chuỗi cố định các bước, LangGraph cho phép bạn xây dựng các quy trình linh hoạt hơn, bao gồm:
-
Rẽ nhánh điều kiện (conditional branching)
-
Vòng lặp (looping)
-
Giao tiếp hai chiều giữa người dùng và LLM
-
Quản lý trạng thái qua nhiều bước xử lý
LangGraph mang lại cách tiếp cận kết hợp giữa Lập trình khai báo(declarative) và Lập trình mệnh lệnh(imperative), giúp bạn dễ dàng hình dung và kiểm soát luồng dữ liệu và trạng thái trong quá trình xử lý.
Vì sao nên sử dụng LangGraph?
Dễ hiểu, dễ hình dung
Bạn xây dựng workflow như một đồ thị gồm các nút (nodes), mỗi nút thực hiện một tác vụ cụ thể, như gọi API, xử lý dữ liệu, tương tác với LLM, hay rẽ nhánh theo điều kiện.
Tái sử dụng và mở rộng tốt
Mỗi nút trong LangGraph là một function, nên bạn dễ dàng viết lại, mở rộng hoặc chia sẻ logic giữa các ứng dụng khác nhau.
Tích hợp chặt chẽ với LangChain
LangGraph kế thừa sức mạnh từ LangChain nên bạn có thể dễ dàng kết hợp với các PromptTemplate, Agents, Memory, hay Tools trong hệ sinh thái LangChain.
Cách hoạt động của LangGraph
Cấu trúc cơ bản của một LangGraph bao gồm:
-
State: Biến lưu trữ dữ liệu cần thiết trong quá trình chạy đồ thị.
-
Node: Hàm xử lý dữ liệu (có thể là gọi LLM, tính toán, rẽ nhánh…).
-
Edges: Kết nối các node theo logic định sẵn.
Ví dụ đơn giản về đồ thị gồm 3 node:
from langgraph.graph import StateGraph, END
# Định nghĩa trạng thái
class MyState(TypedDict):
input: str
output: str
# Định nghĩa node
def process_input(state):
result = state["input"].upper()
return {"output": result}
# Tạo đồ thị
builder = StateGraph(MyState)
builder.add_node("process", process_input)
builder.set_entry_point("process")
builder.set_finish_point("process", END)
graph = builder.compile()
# Chạy đồ thị
result = graph.invoke({"input": "hello"})
print(result)
Ứng dụng thực tế
LangGraph rất phù hợp cho các bài toán phức tạp với LLM như:
-
Chatbot nhiều bước với trạng thái duy trì qua từng lượt chat
-
Tóm tắt tài liệu theo yêu cầu với logic tùy chỉnh
-
Agent phức tạp với hành vi có điều kiện
-
Hệ thống tư vấn, hỏi đáp với nhiều nhánh logic
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Vì sao LangGraph ra đời và Graph có ý nghĩa gì
Khi các ứng dụng xây dựng trên mô hình ngôn ngữ lớn (LLM) ngày càng trở nên phức tạp – từ chatbot đơn giản đến hệ thống tự động hóa tác vụ – thì nhu cầu về cách điều phối luồng suy nghĩ, trạng thái, và hành động của LLMs cũng tăng theo.
Đó là lý do vì sao LangGraph ra đời.
LangGraph là một framework kết hợp LLMs với cấu trúc đồ thị trạng thái (stateful graphs), giúp tạo ra các ứng dụng có khả năng:
-
Gọi nhiều công cụ khác nhau
-
Lặp lại hành động nếu cần thiết
-
Chuyển hướng luồng xử lý dựa trên kết quả
-
Giữ được trạng thái trong suốt quá trình suy luận
I. Tại sao lại là LangGraph?
1. Giới hạn của mô hình agent truyền thống (LangChain Agents)
Các agents trong LangChain rất linh hoạt, nhưng đôi khi:
-
Thiếu khả năng kiểm soát luồng suy luận
-
Khó kiểm tra và debug khi có nhiều bước
-
Thiếu khả năng giữ trạng thái rõ ràng (statefulness)
-
Gặp khó khăn với các vòng lặp (loop), nhánh (branch), hoặc điều kiện lặp lại
Kết quả là khi xây dựng các ứng dụng phức tạp như AutoGPT, trợ lý đa tác vụ, hệ thống hỏi đáp nhiều bước... developer phải viết rất nhiều code xử lý luồng hoặc hack workaround.
2. LangGraph: Giải pháp điều phối LLM theo kiểu đồ thị trạng thái
LangGraph đưa ra một kiến trúc mới, nơi quá trình suy nghĩ và hành động của LLM được mô hình hóa như một đồ thị (graph).
Mỗi node trong đồ thị:
-
Có thể là một hành động cụ thể (gọi API, suy nghĩ, hỏi người dùng…)
-
Có thể gọi LLM để đưa ra quyết định chuyển hướng (routing)
Lợi ích chính:
| Tính năng | Ý nghĩa |
|---|---|
| Có trạng thái | Lưu giữ thông tin giữa các bước |
| Có vòng lặp | Hỗ trợ dễ dàng quá trình phản xạ (reflection), retry, sửa lỗi |
| Modular | Mỗi node độc lập, dễ tái sử dụng |
| Dễ debug | Có thể quan sát từng node và hướng đi trong quá trình xử lý |
| Tùy chọn luồng | Có thể dùng LLM để quyết định đi hướng nào trong graph |
II. Tại sao lại dùng từ “Graph”?
1. Graph = Đồ thị trạng thái có hướng
LangGraph sử dụng lý thuyết đồ thị (directed graph) như một cách để mô hình hóa quy trình tư duy của một agent.
Trong graph:
-
Node là một bước trong quy trình (ví dụ: "Phân tích yêu cầu", "Tìm kiếm trên web", "Tóm tắt dữ liệu", "Phản hồi")
-
Edge là hướng đi từ một bước đến bước kế tiếp, có thể phụ thuộc vào điều kiện (ví dụ: nếu LLM nói "Chưa đủ dữ liệu", hãy quay lại bước tìm kiếm)
Graph này giống như flowchart thông minh, nhưng được điều khiển bởi LLM.
2. Graph giúp dễ hình dung quy trình phức tạp
Dưới dạng graph, developer có thể:
-
Nhìn thấy toàn bộ hành trình của agent
-
Điều chỉnh từng bước mà không ảnh hưởng đến toàn hệ thống
-
Thêm logic phức tạp (loop, điều kiện, xử lý lỗi) một cách trực quan
Ví dụ:
[User Input]
↓
[LLM hiểu yêu cầu]
↓
[Chọn hành động] ──→ [Dùng công cụ] ──→ [Tóm tắt kết quả]
↑ ↓
[Thiếu dữ liệu?] ←──────[Kiểm tra đủ chưa?]
III. Khi nào nên dùng LangGraph?
LangGraph cực kỳ phù hợp khi bạn xây dựng:
Multi-step reasoning (suy luận nhiều bước)
Agents có khả năng reflection / retry / repair
Workflow có trạng thái (stateful flows)
Hệ thống cần kiểm soát logic chặt chẽ
Quy trình có loop, branching hoặc fallback logic
Ví dụ ứng dụng:
-
Trợ lý hỏi đáp tài liệu nhiều bước (hay bị "không đủ dữ liệu")
-
Tác nhân viết báo cáo (chia nhỏ tác vụ và lặp lại từng phần)
-
QA system với logic xác minh độ chính xác
-
Tác nhân phân tích dữ liệu và tự sửa lỗi truy vấn
| ❓ Câu hỏi | ✅ Trả lời |
|---|---|
| Vì sao LangGraph? | Vì các ứng dụng LLM ngày càng phức tạp, cần khả năng điều phối, giữ trạng thái, và xử lý logic phức tạp. |
| Vì sao "Graph"? | Vì LangGraph mô hình hóa tư duy của agent dưới dạng đồ thị trạng thái có hướng — giúp kiểm soát, mở rộng, debug dễ dàng hơn. |
Lập trình khai báo(declarative) và Lập trình mệnh lệnh(imperative)
Lập trình khai báo(declarative) và Lập trình mệnh lệnh(imperative) là hai phong cách lập trình khác nhau — chúng phản ánh cách bạn mô tả công việc mà máy tính cần thực hiện
I. Lập trình khai báo(declarative)
-
Bạn nói cho máy tính biết bạn muốn đạt được gì.
-
Tập trung vào cái gì là kết quả cuối cùng.
-
Máy tính sẽ tự lo cách thực hiện.
# Declarative (giống kiểu functional programming)
result = [x * 2 for x in data if x > 10]
Hoặc ví dụ quen thuộc hơn:
SELECT * FROM users WHERE age > 18;Bạn không nói “lặp qua từng dòng, kiểm tra tuổi”, mà chỉ nói “hãy lấy dữ liệu theo điều kiện”.
II. Lập trình mệnh lệnh(imperative)
-
Bạn nói cho máy tính biết từng bước phải làm gì.
-
Tập trung vào cách để đạt được mục tiêu.
-
Ví dụ: viết một vòng lặp
for, gọi hàm này rồi hàm kia, kiểm tra điều kiện…# Imperative result = [] for x in data: if x > 10: result.append(x * 2)Bạn phải quản lý từng bước cụ thể.
III. Trong LangGraph thì sao?
LangGraph kết hợp cả hai phong cách:
-
Bạn khai báo các node và mối quan hệ giữa chúng (kiểu Lập trình khai báo(declarative) – giống vẽ sơ đồ luồng).
-
Nhưng bên trong mỗi node, bạn viết các bước cụ thể xử lý dữ liệu (kiểu Lập trình mệnh lệnh(imperative) – như viết hàm bình thường).
Ví dụ:
builder.add_node("process", process_input) # declarative
def process_input(state): # imperative
return {"output": state["input"].upper()}
Tóm lại:
LangGraph giúp bạn tận dụng sức mạnh kết hợp: vừa dễ hình dung (declarative), vừa dễ điều khiển (imperative).
| Phong cách | Bạn mô tả... | Ưu điểm | Nhược điểm |
|---|---|---|---|
| Imperative | CÁCH máy tính phải làm | Kiểm soát chi tiết | Dễ rối với quy trình phức tạp |
| Declarative | CÁI GÌ bạn muốn đạt được | Gọn, dễ hiểu | Khó kiểm soát từng bước nhỏ |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
So sánh LangGraph và LangChain
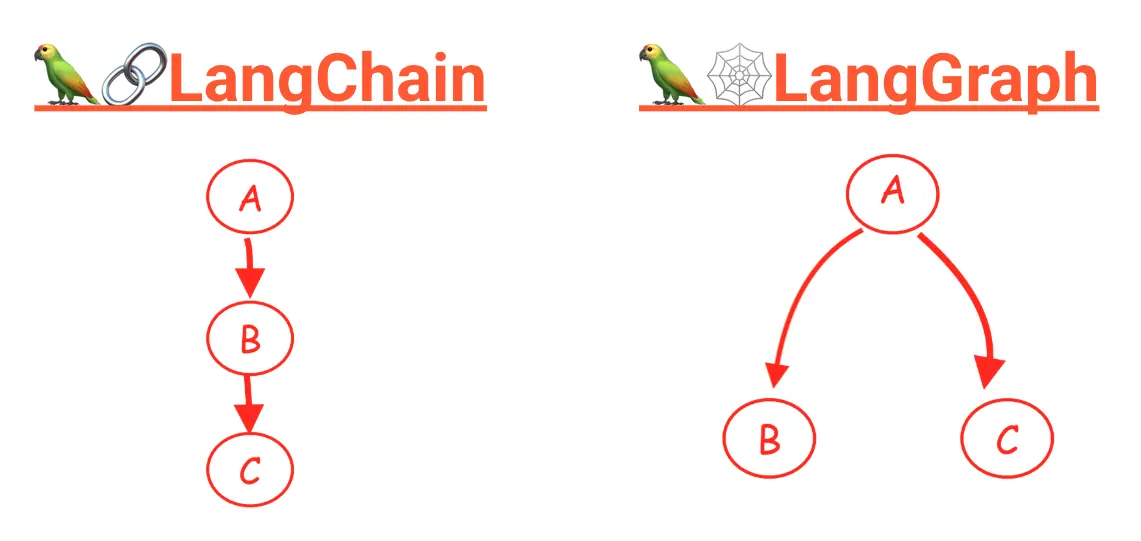
Với sự phát triển nhanh chóng của các mô hình ngôn ngữ lớn như GPT, Claude, Mistral..., các thư viện như LangChain và LangGraph ra đời để giúp lập trình viên dễ dàng xây dựng ứng dụng sử dụng LLM. Nhưng giữa hai cái tên quen thuộc này, bạn nên chọn cái nào? Hoặc khi nào nên dùng cả hai?
Bài viết này sẽ giúp bạn hiểu rõ sự khác biệt, điểm mạnh, và cách sử dụng của LangChain và LangGraph.
I. Tổng quan
| Đặc điểm | LangChain | LangGraph |
|---|---|---|
| Mục tiêu | Tạo pipeline (chuỗi) LLM logic | Tạo workflow (đồ thị trạng thái) phức tạp |
| Cấu trúc | Tuyến tính (linear chain / agent) | Đồ thị trạng thái có vòng lặp, rẽ nhánh |
| Mô hình dữ liệu | Stateless (không lưu trạng thái) | Stateful (quản lý trạng thái qua nhiều bước) |
| Tích hợp LLM | Rất mạnh, nhiều tools tích hợp | Kế thừa từ LangChain |
| Độ linh hoạt | Cao với chuỗi đơn giản hoặc agents | Rất cao với workflow phức tạp |
| Sử dụng chính | Chatbot, Q&A, Retrieval, Agents | Bot đa bước, phân nhánh logic, memory flows |
II. Kiến trúc hoạt động
LangChain
LangChain cung cấp một tập hợp các abstractions như:
-
LLMChain: Gọi một LLM với prompt -
Chain: Kết hợp nhiều bước xử lý nối tiếp nhau -
Agent: Cho phép mô hình quyết định hành động tiếp theo -
Memory: Lưu trạng thái cuộc hội thoại tạm thời
Mỗi chain là tuyến tính — dữ liệu đi từ đầu đến cuối qua từng bước.
Ưu điểm: Dễ dùng, dễ hiểu, setup nhanh.
Nhược điểm: Hạn chế khi bạn muốn rẽ nhánh, lặp lại, hoặc xử lý logic phức tạp.
LangGraph
LangGraph đưa kiến trúc lên tầm cao hơn: bạn không chỉ nối các bước, bạn vẽ ra một đồ thị trạng thái. Trong đó:
-
Mỗi node là một bước xử lý
-
Bạn có thể rẽ nhánh tùy vào điều kiện
-
Có thể lặp lại một node hoặc quay lại node trước
-
Trạng thái được lưu và truyền qua toàn bộ đồ thị
LangGraph kế thừa toàn bộ các công cụ từ LangChain như LLMChain, PromptTemplate, Tool, Memory, Agent,… nhưng nâng cấp khả năng tổ chức luồng xử lý lên mức workflow engine.
Ưu điểm: Xử lý logic phức tạp, hỗ trợ đa chiều, có vòng lặp.
Nhược điểm: Khó hơn để bắt đầu, yêu cầu hiểu về state và luồng.
III. Khi nào dùng LangChain?
Dùng LangChain khi bạn:
-
Chỉ cần chạy một chuỗi các bước (pipeline)
-
Viết một chatbot đơn giản
-
Làm Q&A với Retriever
-
Gọi LLM để xử lý văn bản đầu vào và trả lại đầu ra ngay lập tức
-
Không cần quản lý nhiều trạng thái phức tạp
Ví dụ: Lấy nội dung từ một file, tóm tắt nó bằng GPT, rồi gửi email.
IV. Khi nào dùng LangGraph?
Dùng LangGraph khi bạn:
-
Cần xây dựng các hệ thống xử lý nhiều bước có rẽ nhánh
-
Muốn xây chatbot đa luồng hội thoại (conversation flows)
-
Có logic phức tạp: vòng lặp, kiểm tra điều kiện, lùi lại bước trước
-
Quản lý trạng thái giữa nhiều bước, hoặc muốn lưu vào database
-
Xây dựng agent với logic phức tạp hơn
ReAct
Ví dụ:
Hệ thống kiểm tra đơn hàng:
-
Người dùng gửi mã đơn →
-
Hệ thống kiểm tra trạng thái đơn →
-
Nếu đơn đang giao: gửi thông báo;
-
Nếu đơn bị huỷ: hỏi lý do → ghi log → gửi xác nhận.
Bạn khó làm điều này gọn gàng với LangChain, nhưng LangGraph làm rất tốt.
V. Có thể dùng kết hợp không?
Hoàn toàn có thể!
LangGraph thực tế được xây dựng trên nền LangChain, nên bạn có thể dùng LLMChain, RetrievalChain, Agents, PromptTemplate bên trong các node của LangGraph.
Ví dụ: Một node trong đồ thị LangGraph có thể gọi một LangChain Agent để xử lý một phần công việc.
VI. So sánh ngắn gọn qua ví dụ
LangChain (linear):
chain = SimpleSequentialChain(chains=[chain1, chain2])
result = chain.run("Hello world")
LangGraph (graph):
builder = StateGraph()
builder.add_node("step1", step1)
builder.add_node("step2", step2)
builder.add_edge("step1", "step2")
builder.set_entry_point("step1")
graph = builder.compile()
graph.invoke({"input": "Hello world"})
VII. Kết luận
| Nếu bạn cần... | Hãy chọn... |
|---|---|
| Xây dựng nhanh một chuỗi xử lý | 🟢 LangChain |
| Quản lý nhiều trạng thái phức tạp | 🟢 LangGraph |
| Làm chatbot đơn giản | 🟢 LangChain |
| Làm agent với hành vi linh hoạt | 🟢 LangGraph |
| Kết hợp các công cụ và logic rẽ nhánh | 🟢 LangGraph |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tác nhân điều phối(Agentic) trong ứng dụng mô hình ngôn ngữ lớn (LLMs)
Với sự phát triển mạnh mẽ của các mô hình ngôn ngữ lớn (LLMs), chúng ta có thể xây dựng nhiều loại ứng dụng khác nhau. Trong đó, hai hướng tiếp cận nổi bật là:
-
Non-Agentic LLM Apps – ứng dụng không có tác nhân điều phối
-
Agentic LLM Apps – ứng dụng có "tác nhân" (agent) tự điều phối hành động
Vậy đâu là sự khác biệt, điểm mạnh – điểm yếu, và bạn nên chọn loại nào cho dự án của mình?
I. Định nghĩa
1. Non-Agentic LLM App là gì?
Đây là các ứng dụng chạy theo logic tuyến tính, được xác định rõ ràng. Mỗi bước được lập trình cụ thể, LLM chỉ làm từng nhiệm vụ một cách tường minh.
Đặc điểm:
-
Không có khả năng tự ra quyết định.
-
Luồng xử lý cố định.
-
Phù hợp với các tác vụ đơn giản, lặp lại.
Ví dụ:
-
Tóm tắt văn bản.
-
Dịch ngôn ngữ.
-
Chatbot hỗ trợ theo kịch bản cố định.
-
Lấy dữ liệu từ cơ sở kiến thức rồi trả lời.
summary = llm("Tóm tắt đoạn văn sau...")
2. Agentic LLM App là gì?
Là ứng dụng mà trong đó LLM hoạt động như một "agent" (tác nhân) — có khả năng:
-
Ra quyết định
-
Lập kế hoạch
-
Chọn công cụ phù hợp để thực thi nhiệm vụ
-
Tự kiểm tra lại kết quả và tiếp tục cho đến khi hoàn thành
Đặc điểm:
-
Có khả năng tư duy nhiều bước.
-
Có thể gọi nhiều công cụ khác nhau.
-
Tự động hóa quy trình phức tạp.
Ví dụ:
-
Một trợ lý AI có thể:
-
Tìm kiếm trên Google,
-
Lấy dữ liệu từ API,
-
Phân tích dữ liệu,
-
Gửi email báo cáo → mà bạn chỉ cần ra lệnh: “Tóm tắt số liệu bán hàng tuần này và gửi qua email cho sếp.”
-
II. So sánh chi tiết
| Đặc điểm | Non-Agentic | Agentic |
|---|---|---|
| Mục tiêu | Xử lý 1 nhiệm vụ đơn giản hoặc theo kịch bản | Tự động hóa nhiều bước, xử lý tác vụ mở |
| Luồng xử lý | Tuyến tính, xác định trước | Rẽ nhánh, điều kiện, có thể điều phối vòng lặp |
| Khả năng lập kế hoạch | ❌ Không | Có (có thể lên kế hoạch và thực thi từng bước) |
| Khả năng chọn công cụ phù hợp | ❌ Không | Có thể chọn tool/action phù hợp theo ngữ cảnh |
| Tính linh hoạt | Trung bình – cao | Rất cao |
| Dễ debug, kiểm soát | Rất dễ | ❌ Phức tạp hơn do có hành vi tự động |
| Hiệu suất | Nhanh hơn, ít token hơn | Chậm hơn, tốn token hơn do phải lập kế hoạch |
| Khả năng sử dụng thực tế | Rất tốt với quy trình ổn định | Tốt với quy trình phức tạp hoặc cần tự thích nghi |
3. Minh họa đơn giản
Tác vụ: “Hãy tìm thông tin về Elon Musk và tóm tắt”
Non-Agentic:
-
Gửi prompt: “Tóm tắt thông tin về Elon Musk”
-
GPT trả lời bằng những gì đã học.
Agentic:
-
Agent tự chọn hành động:
-
Gọi công cụ
WebSearch -
Lấy 3 kết quả đầu
-
Tóm tắt chúng
-
Kiểm tra nếu có thông tin mới → bổ sung → xuất bản kết quả
-
4. Công nghệ hỗ trợ
| Tính năng | Non-Agentic | Agentic |
|---|---|---|
| Thư viện phổ biến | LangChain, Transformers | LangChain Agents, LangGraph, AutoGPT |
| Công cụ gọi ngoài (Tools) | Có, nhưng gọi tường minh | LLM tự chọn công cụ thông minh |
| Bộ nhớ (Memory) | Đơn giản hoặc không có | Quan trọng để theo dõi trạng thái |
| Loop / Retry logic | Phải lập trình thủ công | Agent có thể tự thực hiện |
5. Khi nào nên dùng loại nào?
| Trường hợp | Nên chọn |
|---|---|
| Xử lý một bước (dịch, tóm tắt, phân loại) | ✅ Non-Agentic |
| Luồng cố định, logic rõ ràng | ✅ Non-Agentic |
| Tác vụ phức tạp, cần suy luận nhiều bước | ✅ Agentic |
| Cần tương tác nhiều hệ thống / API / Tool | ✅ Agentic |
| Trợ lý AI hoặc hệ thống hỗ trợ quyết định | ✅ Agentic |
| Ưu tiên tốc độ, đơn giản, tiết kiệm tài nguyên | ✅ Non-Agentic |
6. Tổng kết
| Tiêu chí | Non-Agentic App | Agentic App |
|---|---|---|
| Đơn giản | ✅ | ❌ (phức tạp hơn) |
| Linh hoạt | ❌ | ✅ |
| Tự chủ | ❌ | ✅ |
| Dễ kiểm soát | ✅ | ❌ |
| Tác vụ phức tạp | ❌ | ✅ |
| Sử dụng tool ngoài | Có nhưng hạn chế | Mạnh mẽ, linh hoạt |
Không có lựa chọn "tốt hơn tuyệt đối" — bạn cần chọn dựa trên mức độ phức tạp của bài toán, khả năng chấp nhận rủi ro, và yêu cầu logic xử lý.
-
Nếu bạn đang xây chatbot trả lời kiến thức công ty, hãy bắt đầu với Non-Agentic.
-
Nếu bạn muốn một trợ lý AI làm việc như con người, thì Agentic là tương lai.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Cấp độ hành vi của tác nhân(Agentic) trong ứng dụng LLM

LLMs như GPT, Claude, hay Gemini, ngày càng nhiều ứng dụng được xây dựng theo kiến trúc agentic – tức là cho phép mô hình "suy nghĩ", lập kế hoạch, và tự ra quyết định. Nhưng không phải ứng dụng nào cũng cần mức độ agentic giống nhau.
Vì vậy, khái niệm Cấp độ hành vi của tác nhân(Degrees of Agentic Behavior) ra đời – mô tả các cấp độ từ đơn giản đến phức tạp mà một hệ thống có thể thể hiện hành vi như một tác nhân (agent).
Agentic Behavior là gì?
"Agentic behavior" đề cập đến khả năng hành động một cách có mục đích của mô hình – không chỉ trả lời từng lệnh một, mà còn:
-
Lập kế hoạch hành động
-
Chọn công cụ phù hợp
-
Gọi nhiều hành động kế tiếp
-
Đánh giá lại kết quả
-
Điều chỉnh chiến lược
Ví dụ, thay vì chỉ trả lời “không biết”, một agentic app có thể:
“Tôi không có thông tin trong cơ sở dữ liệu. Tôi sẽ tìm kiếm trên web, tóm tắt, rồi trình bày kết quả.”
5 Cấp độ Hành vi Agentic (Degrees of Agentic Behavior)
Chúng ta có thể chia hành vi agentic thành năm cấp độ, từ đơn giản (non-agentic) đến phức tạp (autonomous agents):
Level 0 – Không có hành vi tác nhân(Non-Agentic)
🔹 Chỉ thực hiện một hành động theo prompt đã lập trình sẵn.
🔹 Không có logic điều phối, không lập kế hoạch.
Ví dụ:
response = llm("Hãy tóm tắt đoạn văn sau...")
Dùng cho:
-
Tóm tắt, dịch, phân loại
-
Chatbot trả lời trực tiếp
Level 1 – Tăng cường bằng công cụ - Sử dụng công cụ một bước(Tool-Enhanced - Single-step Tool Use)
🔹 Ứng dụng có thể sử dụng một công cụ bên ngoài, nhưng người lập trình phải chỉ định rõ khi nào dùng tool nào.
Ví dụ:
if "search" in user_input:
result = web_search_tool(query)
else:
result = llm(user_input)
Dùng cho:
-
Tìm kiếm trên web theo trigger
-
Trích xuất dữ liệu từ cơ sở kiến thức
Level 2 – Các tác nhân phản ứng - Sử dụng công cụ động(Reactive Agents - Dynamic Tool Use)
🔹 LLM tự quyết định khi nào cần dùng công cụ nào
🔹 Các công cụ (tools) được mô tả bằng prompt hoặc API
🔹 LLM chọn hành động tốt nhất dựa trên ngữ cảnh hiện tại
Ví dụ: LLM tự chọn Calculator để tính toán thay vì chỉ đoán kết quả.
Dùng LangChain Agents, OpenAI Function Calling, hoặc LangGraph Nodes.
Dùng cho:
-
Trợ lý cá nhân AI có khả năng tìm kiếm, phân tích, tóm tắt
-
Chatbot hiểu ngữ cảnh và chọn hành động phù hợp
Level 3 – Các tác nhân tự phản hồi hoặc thực hiện vòng lặp (Reflective / Iterative)
🔹 Agent có khả năng tự phản hồi (self-reflect) và thực hiện vòng lặp xử lý đến khi đạt được mục tiêu
🔹 Có thể lập kế hoạch, thực hiện hành động, kiểm tra lại, và sửa lỗi
Ví dụ:
if "search" in user_input:
result = web_search_tool(query)
else:
result = llm(user_input)
Dùng Looping Graphs trong LangGraph hoặc Agent Executors có khả năng hồi quy.
Dùng cho:
-
Tác vụ đòi hỏi tư duy nhiều bước (multi-step reasoning)
-
Tự kiểm tra và cải thiện kết quả
Level 4 – Các tác nhân tự chủ đa mục tiêu (Autonomous Multi-goal Agents)
🔹 Agent có khả năng:
-
Nhận mục tiêu tổng quát ("Viết báo cáo thị trường tháng này")
-
Tự chia nhỏ thành các sub-goals
-
Tự lên kế hoạch
-
Tự chạy, điều chỉnh, giám sát tiến trình
Ví dụ: AutoGPT, BabyAGI, OpenDevin
Có thể chạy nhiều vòng lặp, tự lưu trạng thái và chuyển hướng kế hoạch khi có lỗi.
Dùng cho:
-
Quản lý dự án
-
Trợ lý lập trình hoặc viết báo cáo tự động
-
Tự động hóa tác vụ phức tạp không xác định trước logic
So sánh nhanh
| Cấp độ | Tên gọi | Mức độ tự chủ | Có lập kế hoạch | Có hành vi phản xạ | Dùng cho tác vụ phức tạp |
|---|---|---|---|---|---|
| 0 |
Không có hành vi tác nhân (Non-agentic) |
❌ | ❌ | ❌ | ❌ |
| 1 |
Tăng cường bằng công cụ (Tool-enhanced) |
⬤ | ❌ | ❌ | ❌ |
| 2 |
Các tác nhân phản ứng (Reactive agents) |
✅ | ❌ | ❌ | ✅ (mức vừa) |
| 3 |
Các tác nhân tự phản hồi hoặc thực hiện vòng lặp (Reflective/Iterative agents) |
✅✅ | ✅ | ✅ | ✅✅ |
| 4 |
Các tác nhân tự chủ đa mục tiêu (Autonomous agents) |
✅✅✅ | ✅✅ | ✅✅ | ✅✅✅ |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
LangGraph Studio, giới thiệu, cài đặt và cách dùng
Giới thiệu LangGraph Studio – Trình quan sát & phát triển Agentic Graphs
I. LangGraph Studio là gì?
LangGraph Studio là một công cụ giao diện đồ họa (GUI) giúp bạn:
-
Quan sát trực quan đồ thị agent (agent graph)
-
Gỡ lỗi (debug) các bước thực thi của LLM agent
-
Theo dõi trạng thái, dữ liệu, và hướng đi qua từng node
-
Phát triển và kiểm thử agent nhanh chóng
Nó giống như một "developer console" dành riêng cho LangGraph, giúp bạn hiểu và kiểm soát quá trình suy luận và hành động của mô hình AI một cách rõ ràng, trực quan.
II. Tại sao nên dùng LangGraph Studio?
| Vấn đề khi không có Studio | LangGraph Studio giúp |
|---|---|
| ❌ Debug khó vì agent ẩn trong LLM | Hiển thị chi tiết từng bước, trạng thái |
| ❌ Khó hiểu LLM đang đi hướng nào | Hiển thị flow trực quan |
| ❌ Phát triển agent lặp đi lặp lại | Test từng phần trực tiếp |
| ❌ Không biết LLM nghĩ gì | Hiển thị prompt, output, action, tool dùng |
III. Cài đặt LangGraph Studio
LangGraph Studio được tích hợp sẵn trong thư viện langgraph. Để cài đặt và sử dụng, bạn chỉ cần:
1. Cài đặt thư viện:
pip install langgraph[dev]
Hoặc nếu bạn đã có langgraph:
pip install -U "langgraph[dev]"
dev extras sẽ cài thêm các gói phục vụ cho Studio như fastapi, uvicorn, jupyter, v.v.
IV. Cách dùng LangGraph Studio
LangGraph Studio hiện hỗ trợ hai cách chính để sử dụng:
1. Chạy dưới dạng local app (FastAPI server)
Bạn có thể thêm dòng sau vào project của bạn để chạy Studio như một app mini:
from langgraph.studio import start_trace_server
start_trace_server()
Mặc định server chạy tại http://localhost:4000
Khi bạn chạy graph của mình, Studio sẽ tự động ghi lại luồng xử lý, trạng thái, inputs/outputs, và hiển thị trên giao diện web.
2 . Tích hợp trong Jupyter Notebook
Nếu bạn đang làm việc trong Jupyter (hoặc Google Colab), bạn có thể dùng:
from langgraph.studio.jupyter import trace_graph
with trace_graph(graph) as session:
result = session.invoke(input_data)
Tính năng này giúp bạn:
-
Thấy flow đồ thị ngay trong notebook
-
Click để xem chi tiết từng node, prompt, tool call, response
-
So sánh nhiều lần chạy khác nhau (useful for debugging)
from langgraph.graph import StateGraph
from langgraph.studio import start_trace_server
# Define some simple node functions
def say_hello(state):
print("Hello!")
return state
def ask_name(state):
state["name"] = "Alice"
return state
# Build graph
builder = StateGraph(dict)
builder.add_node("hello", say_hello)
builder.add_node("ask", ask_name)
builder.set_entry_point("hello")
builder.add_edge("hello", "ask")
graph = builder.compile()
# Start studio server
start_trace_server()
# Run
graph.invoke({})
Khi chạy đoạn code này, bạn có thể truy cập http://localhost:4000 để thấy luồng hello → ask cùng với trạng thái và log chi tiết.
VI. Các tính năng nổi bật
| Tính năng | Mô tả |
|---|---|
| Flow Graph View | Hiển thị đồ thị agent và luồng thực tế đã đi qua |
| Prompt Viewer | Hiển thị đầy đủ prompt mà LLM nhận được |
| Input/Output Log | Xem tất cả input và output của từng bước |
| Multi-run Comparison | So sánh nhiều phiên bản chạy graph khác nhau |
| Token usage & Cost (tương lai) | Theo dõi chi phí sử dụng OpenAI, Anthropic,... |
| Node debug | Hiển thị error và traceback nếu có lỗi ở một node |
VII. Khi nào nên dùng LangGraph Studio?
-
Khi bạn xây dựng agent có nhiều bước
-
Khi bạn xử lý luồng có điều kiện, vòng lặp, branch
-
Khi cần kiểm soát tool call / prompt / phản hồi
-
Khi muốn debug graph state dễ dàng
VIII. Tổng kết
| Câu hỏi | Trả lời |
|---|---|
| LangGraph Studio là gì? | Là công cụ GUI để quan sát và phát triển LangGraph Agents một cách trực quan và có thể debug. |
| Làm gì được với nó? | Theo dõi prompt, response, trạng thái, tool call... từng bước trong graph |
| Cài đặt ra sao? | pip install langgraph[dev] |
| Chạy ở đâu? | Trong local (FastAPI) hoặc trong Jupyter Notebook |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tạo ứng dụng cơ bản LangGraph AI Agents.
Tài liệu này sẽ hướng dẫn bạn cách cài đặt dự án và hiểu rõ các thành phần cốt lõi trong một đồ thị (graph).
Từ đó, bạn có thể dễ dàng tùy chỉnh, mở rộng hoặc tích hợp thêm các công cụ để phù hợp với nhu cầu thực tế.
Biên soạn bởi:
Đỗ Ngọc Tú
CEO VHTSoft
LangGraph: Framework Xây Dựng Ứng Dụng LLM Dựa Trên Agent + Graph
LangGraph là một framework mã nguồn mở được xây dựng trên nền tảng của LangChain, cho phép bạn phát triển các ứng dụng sử dụng LLM (Large Language Models) theo mô hình agentic – nơi AI không chỉ trả lời câu hỏi, mà còn suy luận, quyết định, gọi tool, và ghi nhớ trạng thái trong nhiều bước.
Điểm đặc biệt của LangGraph là nó tổ chức toàn bộ logic ứng dụng dưới dạng một đồ thị trạng thái (stateful graph) – mỗi "node" là một hành động, một agent, hoặc một bước xử lý.
Tại sao cần LangGraph?
Các ứng dụng AI ngày nay không chỉ dừng ở hỏi-đáp đơn lẻ. Chúng cần:
-
Gọi nhiều công cụ (tool use)
-
Ghi nhớ trạng thái để suy luận liên tục
-
Lặp lại hành động hoặc rẽ nhánh theo kết quả
-
Kiểm soát logic phức tạp có điều kiện
LangGraph giúp bạn làm tất cả điều đó một cách có cấu trúc, dễ theo dõi và mở rộng.
LangGraph hoạt động như thế nào?
LangGraph xây dựng ứng dụng theo mô hình Finite-State Machine (FSM):
-
Mỗi node là một bước xử lý (ví dụ: gọi LLM, tìm kiếm, phân tích, v.v.)
-
State là dữ liệu được lưu và truyền qua từng bước
-
Edge quyết định luồng đi tiếp theo dựa trên kết quả hoặc trạng thái
Bạn có thể tạo các ứng dụng như:
-
Chatbot thông minh
-
Multi-tool agent (Google + Calculator + Document Retriever…)
-
Workflow phân tích dữ liệu
-
Trợ lý quy trình nghiệp vụ (ERP, CRM…)
Cú pháp cơ bản
from langgraph.graph import StateGraph
def greet(state): print("Hello!"); return state
def ask_name(state): state["name"] = "Alice"; return state
builder = StateGraph(dict)
builder.add_node("greet", greet)
builder.add_node("ask", ask_name)
builder.set_entry_point("greet")
builder.add_edge("greet", "ask")
graph = builder.compile()
graph.invoke({})
5 Khái Niệm Trụ Cột
LangGraph là một framework mạnh mẽ để xây dựng các ứng dụng LLM có logic phức tạp theo mô hình graph-based agent. Để làm chủ LangGraph, bạn cần hiểu rõ 5 thành phần chính: State, Schema, Node, Edge, và Compile.
1. State = Memory (Trạng thái là bộ nhớ)
Trong LangGraph, State là nơi lưu trữ toàn bộ thông tin mà ứng dụng của bạn cần ghi nhớ trong suốt quá trình chạy.
-
Nó có thể chứa input từ người dùng, kết quả từ LLM, thông tin truy xuất từ tool, v.v.
-
Mỗi node trong graph có thể đọc và ghi vào state.
-
State giúp ứng dụng suy nghĩ nhiều bước, ghi nhớ dữ kiện, và sử dụng lại ở bước sau.
Ví dụ:
{"question": "Chủ tịch nước Việt Nam là ai?", "llm_response": "..." }State giống như RAM của agent – càng tổ chức tốt, agent càng thông minh và hiệu quả.
2. Schema = Data Format (Định dạng dữ liệu)
LangGraph yêu cầu bạn định nghĩa Schema cho State để đảm bảo dữ liệu được quản lý nhất quán, an toàn và rõ ràng.
-
Schema là một class Python (thường dùng
pydantic.BaseModelhoặcTypedDict) -
Nó xác định rõ những gì tồn tại trong state, loại dữ liệu, và bắt buộc hay không.
Ví dụ:
from typing import TypedDict
class MyState(TypedDict):
question: str
answer: str
Schema = bản thiết kế dữ liệu, giúp bạn tránh lỗi, dễ debug và mở rộng.
3. Node = Step (Một bước xử lý)
Node là một bước trong đồ thị – nơi một phần công việc được thực hiện.
-
Có thể là một LLM call, một hành động với tool, một quyết định logic, v.v.
-
Mỗi node nhận
state, xử lý và trả lạistateđã được cập nhật.
Ví dụ node đơn giản:
def call_llm(state):
response = llm.invoke(state["question"])
state["answer"] = response
return state
4. Edge = Kết nối giữa các bước(Operation Between Steps)
Edge là mối liên kết giữa các node – giúp bạn định nghĩa luồng đi của chương trình.
-
Một node có thể có nhiều edge đi tới các bước khác nhau (ví dụ dựa vào kết quả).
-
Có thể định nghĩa logic rẽ nhánh (branching), lặp lại (loop) hoặc kết thúc tại đây.
Ví dụ:
graph.add_edge("ask_user", "call_llm")
graph.add_conditional_edges("call_llm", {
"need_more_info": "search_tool",
"done": END
})
Edge quyết định luồng suy nghĩ và logic quyết định của agent.
5. Compile = Đóng gói đồ thị để sử dụng(Pack)
Sau khi bạn đã định nghĩa đầy đủ các node, edge và schema, bước cuối cùng là compile – để tạo ra một graph sẵn sàng chạy.
-
compile()sẽ kiểm tra sự nhất quán, ràng buộc, và đóng gói toàn bộ graph. -
Sau đó, bạn có thể dùng
.invoke()để chạy agent một cách mượt mà.
Ví dụ:
builder = StateGraph(MyState)
# add node, edge...
graph = builder.compile()
graph.invoke({"question": "..."})
Compile = chuyển bản thiết kế sang sản phẩm hoàn chỉnh có thể vận hành.
Tóm lại
| Thành phần | Vai trò | Ví dụ dễ hiểu |
|---|---|---|
| State | Bộ nhớ dùng để truyền dữ liệu giữa các bước | “Tôi nhớ câu hỏi người dùng” |
| Schema | Định nghĩa cấu trúc và loại dữ liệu trong state | “State phải có ‘question’ dạng chuỗi” |
| Node | Một bước xử lý như LLM call, tool call, v.v. | “Gọi GPT để trả lời” |
| Edge | Điều khiển luồng di chuyển giữa các node | “Nếu xong thì kết thúc, nếu thiếu thì tìm tiếp” |
| Compile | Đóng gói toàn bộ graph để vận hành | “Biến các bước rời rạc thành một chương trình” |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Giới thiệu Poetry
Poetry – một công cụ hiện đại để quản lý gói (package) và môi trường (environment) trong Python.
Poetry là gì?
Poetry là một công cụ giúp bạn:
-
Quản lý dependencies (thư viện phụ thuộc).
-
Quản lý và build package Python.
-
Tạo môi trường ảo tự động.
-
Publish package lên PyPI dễ dàng.
Poetry thay thế việc bạn phải dùng pip, venv, requirements.txt, setup.py, pyproject.toml,... riêng lẻ — tất cả tích hợp trong một công cụ.
Tại sao nên dùng Poetry?
| Truyền thống (pip + venv + requirements) | Poetry |
|---|---|
| Quản lý môi trường và dependency riêng | Tất cả-in-one |
| Cần nhiều file config khác nhau | Dùng duy nhất pyproject.toml |
| Khó pin version chính xác | Poetry lock chính xác |
| Không tự động tạo môi trường | Poetry tự tạo virtualenv |
| Không có tính năng publish | Poetry có lệnh poetry publish |
Khi nào nên dùng Poetry?
-
Khi bạn muốn quản lý dependency dễ dàng và sạch sẽ.
-
Khi bạn muốn tạo project có thể publish lên PyPI.
-
Khi bạn làm việc nhóm hoặc CI/CD cần môi trường chính xác.
-
Khi bạn phát triển package, lib hoặc ứng dụng production.
Cài đặt Poetry
curl -sSL https://install.python-poetry.org | python3 -Sau đó thêm vào shell config nếu cần:
export PATH="$HOME/.local/bin:$PATH"
poetry --version
Khởi tạo project với Poetry
poetry new myproject
cd myproject
Cấu trúc thư mục sẽ được tạo sẵn:
myproject/
├── myproject/
│ └── __init__.py
├── tests/
├── pyproject.toml
└── README.rst
Thêm dependency
poetry add requests
Poetry sẽ:
-
Cài thư viện vào virtualenv riêng.
-
Ghi lại vào
pyproject.tomlvàpoetry.lock.
Muốn thêm dev-dependency?
poetry add --dev black
Tạo môi trường và chạy shell
poetry shellGiống như source venv/bin/activate — bạn sẽ vào môi trường ảo của Poetry.
Hoặc chạy lệnh trong môi trường mà không cần shell:
poetry run python script.pypyproject.toml là gì?
Đây là file cấu hình trung tâm của project Python hiện đại.
Poetry dùng file này để:
-
Khai báo tên project, version, mô tả...
-
Danh sách dependencies.
-
Cấu hình build.
Ví dụ:
[tool.poetry]
name = "VHTSoft"
version = "0.1.0"
description = "Dự án tuyệt vời"
authors = ["Bạn <admin@vhtsoft.com>"]
[tool.poetry.dependencies]
python = "^3.10"
requests = "^2.31.0"
[tool.poetry.dev-dependencies]
black = "^23.0.0"
Build và Publish
poetry build
poetry publish --username __token__ --password pypi-***
Bạn có thể đăng lên PyPI nếu muốn chia sẻ package.
Lệnh phổ biến
| Lệnh | Chức năng |
|---|---|
poetry new myproject |
Tạo mới một project |
poetry init |
Tạo pyproject.toml trong thư mục hiện tại |
poetry add <package> |
Thêm dependency |
poetry install |
Cài dependencies từ pyproject.toml |
poetry update |
Cập nhật toàn bộ thư viện |
poetry lock |
Tạo/cập nhật poetry.lock |
poetry run <cmd> |
Chạy lệnh trong môi trường ảo |
poetry shell |
Mở môi trường ảo |
poetry build |
Đóng gói project |
poetry publish |
Đăng lên PyPI |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Cơ bản về GraphBuilder
Trong LangGraph, bạn sẽ sử dụng một GraphBuilder để định nghĩa các bước (nodes), luồng xử lý (edges), điều kiện phân nhánh (routers), và điểm bắt đầu/kết thúc của một ứng dụng dựa trên LLM.
from langgraph.graph import StateGraph
builder = StateGraph(StateType)
Ở đây StateType là schema mô tả state (thường là TypedDict hoặc pydantic model).
Ví dụ
from typing import TypedDict, Literal
class DrinkState(TypedDict):
preference: Literal["coffee", "tea", "unknown"]1. builder.add_node(name, node_callable)
Thêm một bước xử lý (node) vào graph.
Cú pháp:
builder.add_node("tên_node", hàm_xử_lý)
Ví dụ
def ask_name(state):
state["name"] = input("Tên bạn là gì? ")
return state
builder.add_node("ask_name", ask_name)
2. builder.add_edge(from_node, to_node)
Tạo liên kết (đường đi) giữa hai node.
Cú pháp:
builder.add_edge("node_nguồn", "node_đích")Ví dụ:
builder.add_edge("ask_name", "ask_preference")3. builder.add_conditional_edges(from_router_node, conditions_dict)
from_router_node: là một hàm xử lý
Tạo đường đi có điều kiện (routing) từ một node tới nhiều node tùy thuộc vào kết quả của node đó.
Cú pháp:
builder.add_conditional_edges("router_node", {
"kết_quả_1": "node_1",
"kết_quả_2": "node_2",
...
})
Ví dụ:
builder.add_conditional_edges("router", {
"coffee_node": "coffee_node",
"tea_node": "tea_node",
"fallback_node": "fallback_node"
})
=> Node "router" sẽ trả về một chuỗi (ví dụ "coffee_node"), và flow sẽ đi đến node tương ứng.
4. builder.set_entry_point(node_name)
Xác định điểm bắt đầu của graph.
Ví dụ
builder.set_entry_point("start")5. builder.set_finish_point(node_name)
Đánh dấu node kết thúc, tức là sau node này thì flow dừng lại.
Có thể có nhiều node kết thúc!
Ví dụ
builder.set_finish_point("coffee_node")
builder.set_finish_point("tea_node")
6. builder.compile()
Biên dịch graph của bạn thành một CompiledGraph có thể chạy được.
Ví dụ
app = builder.compile()
Sau đó
app.invoke({"preference": "unknown"}7. Tổng kết
| Hàm | Mô tả |
|---|---|
add_node(name, node_fn) |
Thêm một bước xử lý đơn vào graph |
add_edge(from_node, to_node) |
Tạo liên kết tuyến tính giữa 2 node |
add_conditional_edges(name, mapping) |
Tạo node phân nhánh có điều kiện |
set_entry_point(name) |
Xác định điểm bắt đầu của flow |
set_finish_point(name) |
Xác định điểm kết thúc |
add_branch(name, sub_graph) |
Thêm một graph phụ (dạng phân nhánh) vào một node |
add_recursion(name, recursive_graph) |
Cho phép gọi đệ quy một graph con |
compile() |
Biên dịch toàn bộ graph thành một ứng dụng chạy được |
add_generator_node(name, generator_node) |
Thêm một node sử dụng generator (yield từng bước) |
add_parallel_nodes(nodes: dict) |
Chạy nhiều node song song trong một bước |
add_conditional_edges_with_default(name, conditions, default) |
Giống add_conditional_edges nhưng có nhánh mặc định |
add_stateful_node(name, node_fn) |
Dùng khi node cần giữ trạng thái riêng biệt |
add_async_node(name, async_node) |
Thêm node xử lý bất đồng bộ (async def) |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Xây dựng một ứng dụng đơn giản (graph) quyết định xem người dùng nên uống cà phê hay trà
Mục tiêu của bài tập này là làm quen với các thành phần và bước chính của ứng dụng LangGraph cơ bản. State, Schema, Node, Edge, và Compile.
I. Cài đặt
- Cài đặt Peotry tại đây
-
tại terminal:
- cd project_name
- pyenv local 3.11.4
- poetry install
- poetry shell
- jupyter lab
-
Tạo file .env
-
OPENAI_API_KEY=your_openai_api_key LANGCHAIN_TRACING_V2=true LANGCHAIN_ENDPOINT=https://api.smith.langchain.com # Bạn sẽ cần đăng ký tài khoản tại smith.langchain.com để lấy API key. LANGCHAIN_API_KEY=your_langchain_api_key LANGCHAIN_PROJECT=your_project_name - Kết nối với tệp .env nằm trong cùng thư mục vào notebook
-
#pip install python-dotenv -
import os from dotenv import load_dotenv, find_dotenv _ = load_dotenv(find_dotenv()) openai_api_key = os.environ["OPENAI_API_KEY"] -
Cài đặt LangChain(Nếu bạn đang sử dụng poetry shell được tải sẵn, bạn không cần phải cài đặt gói sau vì nó đã được tải sẵn cho bạn:)
-
#!pip install langchain - Kết nối với LLM
-
#!pip install langchain-openai from langchain_openai import ChatOpenAI chatModel35 = ChatOpenAI(model="gpt-3.5-turbo-0125") chatModel4o = ChatOpenAI(model="gpt-4o")
Đây là hình ảnh đồ họa của ứng dụng chúng ta sẽ xây dựng
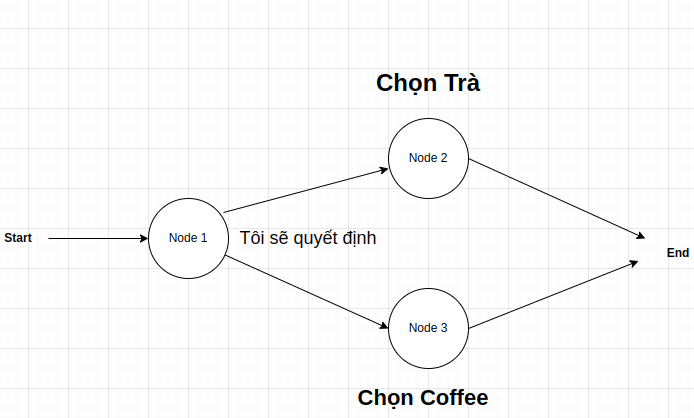
2. Xác định lược đồ trạng thái(state schema)
- Điều đầu tiên chúng ta sẽ làm là xác định State của ứng dụng.
- State schema cấu hình những gì, sẽ có trong state và với định dạng nào.
- State thường sẽ là TypedDict hoặc mô hình Pydantic.
Đối với ví dụ này, lớp State sẽ chỉ có một khóa, graph_state, với định dạng chuỗi
from typing_extensions import TypedDict
class State(TypedDict):
graph_state: strTypedDict là gì?
- TypedDict cho phép bạn định nghĩa các từ điển có cấu trúc cụ thể. Nó cho phép bạn chỉ định các khóa chính xác và các loại giá trị liên quan của chúng, giúp mã của bạn rõ ràng hơn và an toàn hơn về mặt kiểu.
Ví dụ, thay vì một từ điển đơn giản như
{"name": "Ngoc Tu", "age": 40}bạn có thể định nghĩa một TypedDict để thực thi rằng tên phải luôn là một chuỗi và tuổi phải luôn là một số nguyên.
Ở đây, một cấu trúc giống như từ điển mới có tên là State được định nghĩa.
State kế thừa từ TypedDict, nghĩa là nó hoạt động giống như một từ điển, nhưng có các quy tắc cụ thể về các khóa và giá trị mà nó phải có.
state: State = {"graph_state": "active"} # Đúngstate: State = {"graph_state": 123} # Sai, Điều này sẽ gây ra lỗi kiểm tra kiểu vì giá trị 123 không phải là chuỗi.3. Xác định các Nodes của ứng dụng
Các Nodes của ứng dụng này được định nghĩa là các hàm python.
Đối số đầu tiên của hàm Node là state. Mỗi Node có thể truy cập khóa graph_state, với state['graph_state'].
Trong bài tập này, mỗi Node sẽ trả về một giá trị mới của khóa trạng thái graph_state. Giá trị mới do mỗi Node trả về sẽ ghi đè lên giá trị state trước đó.
Nếu luồng đồ thị là Node 1 đến Node 2, trạng thái cuối cùng sẽ là "Chọn Trà".
Nếu luồng đồ thị là nút 1 đến nút 3, trạng thái cuối cùng sẽ là "Chọn Coffee".
def node_1(state):
print("---Node 1---")
return {"graph_state": state['graph_state'] +" Tôi sẽ quyết định"}
def node_2(state):
print("---Node 2---")
return {"graph_state": state['graph_state'] +" Chọn Trà"}
def node_3(state):
print("---Node 3---")
return {"graph_state": state['graph_state'] +" Chọn Coffee"}4. Xác định các Edges(cạnh) kết nối các Node
Cạnh thông thường đi từ Node này sang Node khác.
4.1 Edge không điều kiện giữa các node
builder = GraphBuilder()
# Thêm các node
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Tạo edge không điều kiện
builder.add_edge("node_1", "node_2") # Sau node_1 thì luôn đi đến node_2
builder.add_edge("node_2", "node_3") # Sau node_2 thì luôn đi đến node_3
# Đặt node bắt đầu
builder.set_entry_point("node_1")
# Tạo app và chạy thử
app = builder.compile()
initial_state = {"graph_state": ""}
final_state = app.invoke(initial_state)
print("Kết quả:", final_state["graph_state"])-
add_edge("node_1", "node_2"): Khi node_1 chạy xong, luôn luôn chuyển sang node_2. -
add_edge("node_2", "node_3"): Khi node_2 chạy xong, luôn luôn chuyển sang node_3. -
Không cần bất kỳ điều kiện nào – đó là lý do gọi là unconditional edge.
---Node 1---
---Node 2---
---Node 3---
Kết quả: Tôi sẽ quyết định. Chọn Trà. Chọn Coffee.4.2 Edge Có điều kiện giữa các node
Cạnh có điều kiện được sử dụng khi bạn muốn tùy chọn định tuyến giữa các Node. Chúng là các hàm chọn nút tiếp theo dựa trên một số logic.
Trong ví dụ trên, để sao chép kết quả quyết định của người dùng, chúng ta sẽ xác định một hàm để mô phỏng xác suất Chọn Trà là 60%.
import random
from typing import Literal
def decide_dring(state) -> Literal["node_2", "node_3"]:
"""
Quyết định nút tiếp theo dựa trên xác suất chia 60/40.
"""
# Mô phỏng xác suất 60% cho "node_2"
if random.random() < 0.6: # 60% chance
return "node_2"
# Còn lại 40% cơ hội
return "node_3"from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Build graph
builder = StateGraph(State)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
# Add the logic of the graph
builder.add_edge(START, "node_1")
builder.add_conditional_edges("node_1", decide_dring) #decide_dring trả về tên `node 2` hoặc `node 3`
builder.add_edge("node_2", END)
builder.add_edge("node_3", END)
# Compile the graph
graph = builder.compile()
# Visualize the graph
display(Image(graph.get_graph().draw_mermaid_png()))Đầu tiên, chúng ta khởi tạo StateGraph với lớp State mà chúng ta đã định nghĩa ở trên.
Sau đó, chúng ta thêm các nút và cạnh.
START Node là một nút đặc biệt gửi dữ liệu đầu vào của người dùng đến graph, để chỉ ra nơi bắt đầu đồ thị của chúng ta.
builder.add_conditional_edges("node_1", decide_dring)Mỗi lần hàm được gọi, nó đưa ra quyết định dựa trên cơ hội ngẫu nhiên:
60% cơ hội: Trả về "node_2".
40% cơ hội: Trả về "node_3".
Tại sao sử dụng điều này?
Để ra quyết định: Nó mô phỏng một lựa chọn xác suất, có thể hữu ích trong các ứng dụng như mô phỏng, trò chơi hoặc học máy.
Kiểu trả về theo nghĩa đen đảm bảo rằng hàm sẽ luôn chỉ trả về "node_2" hoặc "node_3", giúp dễ dự đoán và gỡ lỗi hơn.
END Node là một nút đặc biệt biểu thị một nút đầu cuối.
Chúng ta biên dịch graph của mình để thực hiện một vài kiểm tra cơ bản trên cấu trúc graph.
5. Chạy ứng dụng
Graph đã biên dịch triển khai giao thức runnable, một cách chuẩn để thực thi các thành phần LangChain. Do đó, chúng ta có thể sử dụng invoke làm một trong những phương pháp chuẩn để chạy ứng dụng này.
Đầu vào ban đầu của chúng ta là từ điển {"graph_state": "Xin chào, đây là VHTSoft."}, từ điển này đặt giá trị ban đầu cho từ điển trạng thái.
Khi invoke được gọi:
Biểu đồ bắt đầu thực thi từ nút START.
Nó tiến triển qua các nút đã xác định (node_1, node_2, node_3) theo thứ tự.
Cạnh có điều kiện sẽ đi qua từ nút 1 đến nút 2 hoặc 3 bằng quy tắc quyết định 60/40.
Mỗi hàm nút nhận trạng thái hiện tại và trả về một giá trị mới, giá trị này sẽ ghi đè trạng thái biểu đồ.
Việc thực thi tiếp tục cho đến khi đạt đến nút END.
graph.invoke({"graph_state" : "Hi, Tôi là VHTSoft."}){'graph_state': 'Hi, Tôi là VHTSoft. Tôi sẽ quyết định Chọn Trà'}Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Ứng dụng LangGraph cơ bản với chatbot và công cụ
Mục tiêu của ứng dụng.

Sử dụng LangGraph quyết định phản hồi bằng chatbot hoặc sử dụng công cụ
Chúng ta sẽ xây dựng một ứng dụng cơ bản thực hiện 4 thao tác
Sử dụng chat messages làm State
Sử dụng chat model làm Node
Liên kết một công cụ với chat model
Thực hiện lệnh gọi công cụ trong Node
I. Cài đặt
* cd project_name
* pyenv local 3.11.4
* poetry install
* poetry shell
* jupyter labtạo file .env
OPENAI_API_KEY=your_openai_api_key
* LANGCHAIN_TRACING_V2=true
* LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
* LANGCHAIN_API_KEY=your_langchain_api_key
* LANGCHAIN_PROJECT=your_project_name
Bạn sẽ cần đăng ký tài khoản tại smith.langchain.com để lấy API key.
Kết nối với file .env nằm trong cùng thư mục của notebook
#pip install python-dotenv
import os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai_api_key = os.environ["OPENAI_API_KEY"]#!pip install langchain-openai
from langchain_openai import ChatOpenAI
chatModel35 = ChatOpenAI(model="gpt-3.5-turbo-0125")
chatModel4o = ChatOpenAI(model="gpt-4o")II. Xác định State schema
from typing_extensions import TypedDict
from langchain_core.messages import AnyMessage
from typing import Annotated
from langgraph.graph.message import add_messages
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]from typing_extensions import TypedDict-
TypedDictcho phép bạn định nghĩa một kiểu dictionary có cấu trúc rõ ràng, giống nhưdataclass, nhưng dành cho dict. -
typing_extensionsđược dùng để hỗ trợ các tính năng mới khi bạn đang dùng phiên bản Python cũ hơn
from langchain_core.messages import AnyMessage
-
AnyMessagelà một kiểu tin nhắn (message) tổng quát trong LangChain. -
Có thể là tin nhắn từ người dùng (
HumanMessage), AI (AIMessage), hệ thống (SystemMessage)
from typing import Annotated-
Annotatedlà một cách để gắn thêm metadata vào kiểu dữ liệu. -
Không thay đổi kiểu dữ liệu, nhưng cho phép các công cụ/phần mềm xử lý kiểu đó biết thêm thông tin phụ.
Metadata là gì? Xem tại đây
Annotated là gì? Xem tại đây
from langgraph.graph.message import add_messages
-
add_messageslà một annotation handler từ thư việnlanggraph. -
Nó được dùng để bổ sung logic cho cách mà LangGraph xử lý trường
messages
class MessagesState(TypedDict):
messages: Annotated[list[AnyMessage], add_messages]III. Xác định Node duy nhất của ứng dụng
def simple_llm(state: MessagesState):
return {"messages": [chatModel4o.invoke(state["messages"])]}Đây là một LangGraph Node Function. Nó:
-
Nhận vào
state(dạng dictionary có cấu trúcMessagesState) -
Lấy danh sách tin nhắn từ
state["messages"] -
Gửi toàn bộ danh sách đó vào mô hình ngôn ngữ
chatModel4o -
Nhận lại một phản hồi từ LLM
-
Trả về phản hồi đó trong một dict mới dưới dạng
{"messages": [<message>]}
Ví dụ minh họa
Giả sử:
state = {
"messages": [
HumanMessage(content="Chào bạn"),
]
}Gọi
simple_llm(state)Trả về
{
"messages": [
AIMessage(content="Chào bạn! Tôi có thể giúp gì?")
]
}
Tóm lại
| Thành phần | Vai trò |
|---|---|
state: MessagesState |
Trạng thái hiện tại (danh sách message) |
chatModel4o.invoke(...) |
Gửi prompt đến LLM |
return {"messages": [...]} |
Trả về message mới để nối thêm vào state |
Vì trong ví dụ này chúng ta chỉ có một nút nên chúng ta không cần phải xác định các cạnh.
IV. Biên dịch ứng dụng
from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("simple_llm", simple_llm)
# Add the logic of the graph
builder.add_edge(START, "simple_llm")
builder.add_edge("simple_llm", END)
# Compile the graph
graph = builder.compile()
# Visualize the graph
display(Image(graph.get_graph().draw_mermaid_png()))from IPython.display import Image, display
-
Dùng trong Jupyter Notebook để hiển thị hình ảnh (ở đây là sơ đồ luồng graph).
-
display(...)dùng để hiển thị hình ảnh. -
Image(...)nhận vào dữ liệu ảnh hoặc URL.
from langgraph.graph import StateGraph, START, END
-
StateGraph: class để xây dựng graph gồm các bước (nodes) xử lý state. -
STARTvàEND: các node mặc định dùng để đánh dấu điểm bắt đầu và kết thúc.
Xây dựng Graph:
builder = StateGraph(MessagesState)Khởi tạo 1 builder để tạo ra graph, với MessagesState là định nghĩa schema cho state.
builder.add_node("simple_llm", simple_llm)-
Thêm một node có tên
"simple_llm"và hàm xử lý tương ứng làsimple_llm.
Kết nối các bước xử lý:
builder.add_edge(START, "simple_llm")
builder.add_edge("simple_llm", END)START → simple_llm → END: bạn đang định nghĩa luồng chạy của graph theo thứ tự:
-
Bắt đầu
-
Chạy
simple_llm -
Kết thúc
Biên dịch Graph:
graph = builder.compile()Hiển thị sơ đồ:
display(Image(graph.get_graph().draw_mermaid_png()))
V. Chạy ứng dụng
from pprint import pprint
from langchain_core.messages import AIMessage, HumanMessage
messages = graph.invoke({"messages": HumanMessage(content="Where is the Golden Gate Bridge?")})
for m in messages['messages']:
m.pretty_print()
- **Gọi Graph để xử lý một prompt** (giống như một chatbot).
- `graph.invoke(...)` là cách chạy luồng xử lý bạn đã định nghĩa bằng `StateGraph`.
- Bạn truyền vào một `dict` có key `"messages"` và giá trị là một **HumanMessage duy nhất**.
Trong thực tế, `"messages"` thường là **list[BaseMessage]**, nhưng LangGraph tự động chuyển đổi nếu bạn truyền một message duy nhất (nó sẽ biến nó thành `[HumanMessage(...)]`)
---### ```python
for m in messages['messages']:
m.pretty_print()
Kết quả in ra (ví dụ)
Giả sử AI trả lời như sau, bạn sẽ thấy:
Human: Where is the Golden Gate Bridge?
AI: The Golden Gate Bridge is located in San Francisco, California, USA.
Diễn giải toàn bộ quy trình
-
Bạn tạo một HumanMessage hỏi AI một câu.
-
Gửi message đó vào graph (đã xây bằng LangGraph).
-
Graph chạy các node, ví dụ
simple_llm, và thêmAIMessagephản hồi vào state. -
Trả về danh sách messages mới (có cả user + AI).
-
In ra từng message bằng
.pretty_print().
V. Bây giờ chúng ta hãy thêm một công cụ vào ChatModel4o
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
chatModel4o_with_tools = chatModel4o.bind_tools([multiply])Định nghĩa một hàm nhân 2 số nguyên a và b.
chatModel4o.bind_tools([multiply])
-
Gắn hàm
multiplyvào mô hìnhchatModel4onhư một tool (công cụ). -
Khi mô hình nhận câu hỏi phù hợp (ví dụ: "What is 6 times 7?"), nó có thể gọi hàm
multiplyđể xử lý thay vì tự trả lời.
VI. Bây giờ chúng ta hãy tạo một ứng dụng LangGraph thứ hai có thể quyết định xem ứng dụng đó có sử dụng chatbot LLM hay Công cụ Multiply để trả lời câu hỏi của người dùng hay không
# Node
def llm_with_tool(state: MessagesState):
return {"messages": [chatModel4o_with_tools.invoke(state["messages"])]}from IPython.display import Image, display
from langgraph.graph import StateGraph, START, END
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("llm_with_tool", llm_with_tool)
# Add the logic of the graph
builder.add_edge(START, "llm_with_tool")
builder.add_edge("llm_with_tool", END)
# Compile the graph
graph = builder.compile()
# Visualize the graph
display(Image(graph.get_graph().draw_mermaid_png()))
from pprint import pprint
from langchain_core.messages import AIMessage, HumanMessage
# The following two lines are the most frequent way to
# run and print a LangGraph chatbot-like app results.
messages = graph.invoke({"messages": HumanMessage(content="Where is the Eiffel Tower?")})
for m in messages['messages']:
m.pretty_print()================================ Human Message ================================= Where is the Eiffel Tower? ================================== Ai Message ================================== The Eiffel Tower is located in Paris, France. It is situated on the Champ de Mars, near the Seine River.
from pprint import pprint
from langchain_core.messages import AIMessage, HumanMessage
# The following two lines are the most frequent way to
# run and print a LangGraph chatbot-like app results.
messages = graph.invoke({"messages": HumanMessage(content="Multiply 4 and 5")})
for m in messages['messages']:
m.pretty_print()================================ Human Message ================================= Multiply 4 and 5 ================================== Ai Message ================================== Tool Calls: multiply (call_QRyPmp5TdcIlfEOyBrJ9E7V5) Call ID: call_QRyPmp5TdcIlfEOyBrJ9E7V5 Args: a: 4 b: 5
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Định tuyến(Router) trong LangGraph
Router trong LangGraph là gì?
Trong LangGraph, Router là một Node đặc biệt (tức một bước – step) cho phép bạn tạo ra các nhánh (branches) dựa trên dữ liệu hoặc trạng thái hiện tại.
Nói đơn giản:
Router giống như ngã ba đường — dựa trên state hiện tại, bạn chọn hướng đi tiếp theo (chuyển tới node A, B hoặc C).
Khi nào bạn cần dùng Router?
Khi bạn có logic như:
-
Nếu người dùng chọn "Coffee" → đi tới node xử lý coffee.
-
Nếu người dùng chọn "Tea" → đi tới node xử lý trà.
-
Nếu không rõ → hỏi lại hoặc kết thúc.
Bạn không muốn xử lý tất cả trong một node, mà tách nhánh theo logic, thì Router là giải pháp.
Cách dùng Router trong LangGraph
def my_router(state):
if state["preference"] == "coffee":
return "coffee_node"
elif state["preference"] == "tea":
return "tea_node"
else:
return "unknown_preference"
Đây là một Router node, tức là nó nhận một state (trạng thái hiện tại), và trả về tên node kế tiếp dựa trên logic.
state["preference"]là giá trị đầu vào mà bạn đưa vào để quyết định nhánh.
-
Nếu thích coffee, thì đi tới node
coffee_node. -
Nếu thích tea, thì đi tới node
tea_node. -
Nếu không rõ, thì về
unknown_preference(mặc dù node này chưa được thêm trong ví dụ – mình sẽ nói thêm ở dưới).
Đăng ký Router node trong graph
Ví dụ sau, Router không thực thi hành động chính mà chọn node tiếp theo dựa trên logic phân nhánh.
builder = StateGraph(StateSchema)
builder.add_node("start", start_node)
builder.add_node("router", my_router)
builder.add_node("coffee_node", coffee_node)
builder.add_node("tea_node", tea_node)
# Router branching
builder.add_edge("start", "router")
builder.add_conditional_edges(
"router",
{
"coffee_node": "coffee_node",
"tea_node": "tea_node"
}
)
- Node router sử dụng hàm my_router, hàm này sẽ trả về các giá trị là tea_node, coffee_node hoặc unknown_preference, LangGraph dùng kết quả đó để tra trong từ điển:
-
{ "coffee_node": "coffee_node", "tea_node": "tea_node" } -
Nếu kết quả là
"coffee_node"→ đi đến node"coffee_node" -
Nếu kết quả là
"tea_node"→ đi đến node"tea_node"
Lợi ích của Router
-
Tách logic phức tạp thành các bước nhỏ.
-
Tạo flow rõ ràng và dễ debug.
-
Xây dựng app agent có khả năng phân nhánh tùy theo trạng thái.
-
Dễ áp dụng trong các hệ thống có điều kiện (if/else).
Gợi ý dùng thực tế
| Use case | Router logic |
|---|---|
| Trợ lý cá nhân | Phân nhánh theo yêu cầu người dùng: tra cứu lịch, gửi mail, hoặc dịch văn bản |
| Ứng dụng học tập | Phân hướng học viên đến bài kiểm tra phù hợp trình độ |
| Ứng dụng đặt hàng | Nếu sản phẩm còn → đặt hàng; nếu không → đề xuất khác |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
So sánh Router và Node trong LangGraph
Dưới đây là bài so sánh chi tiết giữa Router và Node trong LangGraph, giúp bạn dễ phân biệt và áp dụng chính xác trong từng tình huống.
| Tiêu chí | Node (Nút xử lý) | Router (Bộ định tuyến) |
|---|---|---|
| Chức năng chính | Xử lý logic cụ thể và trả về dữ liệu mới | Định tuyến (chọn nhánh tiếp theo dựa trên trạng thái) |
| Trả về | Một dictionary chứa các giá trị mới cho state | Một chuỗi (string) tên của node tiếp theo |
| Điều hướng tiếp theo | Sử dụng add_edge() hoặc add_conditional_edges() |
Sử dụng add_conditional_edges() để ánh xạ chuỗi → node |
| Tính logic | Chứa logic chính như gọi LLM, xử lý dữ liệu... | Chứa logic quyết định hướng đi tiếp theo |
| Dữ liệu trả về | Ví dụ: { "graph_state": "Tôi chọn trà" } |
Ví dụ: "coffee_node" hoặc "tea_node" |
| Dùng khi nào? | Khi cần thực hiện một hành động/ghi nhớ dữ liệu | Khi cần rẽ nhánh theo điều kiện hoặc phân luồng logic |
Ví dụ minh họa
Node bình thường trả về giá trị mới cho state:
def coffee_node(state):
print("☕ Tôi chọn coffee")
return {"result": "Bạn sẽ có một ly coffee"}
Router trả về tên của node tiếp theo:
def my_router(state):
if state["preference"] == "coffee":
return "coffee_node"
elif state["preference"] == "tea":
return "tea_node"
else:
return "unknown_node"
Khi nào dùng Router thay vì Node?
-
Khi bạn cần rẽ nhánh logic theo điều kiện → dùng
router. -
Khi bạn cần thực hiện hành động cụ thể (gọi LLM, tính toán, ghi log,...) → dùng
node.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Hiểu rõ hơn về add_conditional_edges
Chúng ta lấy 2 ví dụ để so sánh
builder.add_conditional_edges("node_1", decide_dring)và
builder.add_conditional_edges("router", {
"coffee_node": "coffee_node",
"tea_node": "tea_node",
"fallback_node": "fallback_node"
})Hai dòng builder.add_conditional_edges(...) trên đều dùng để thêm điều kiện rẽ nhánh, nhưng cách dùng và mục đích của chúng có sự khác biệt rõ ràng.
| Tiêu chí | builder.add_conditional_edges("node_1", decide_dring) |
builder.add_conditional_edges("router", { "coffee_node": ..., ... }) |
|---|---|---|
| Kiểu truyền đối số | Truyền một hàm điều kiện (condition function) | Truyền một dict ánh xạ giá trị trả về từ router đến các node tương ứng |
| Ai quyết định rẽ nhánh? | Hàm decide_dring(state) sẽ quyết định đi đến node nào |
Hàm router(state) sẽ trả về một string → dict ánh xạ string đó đến node tương ứng |
| Giá trị trả về của hàm | Trả về tên node dưới dạng string | Trả về tên node dưới dạng string, phải trùng với key trong dict |
| Node được gắn vào | Gắn vào một node bình thường (node_1) |
Gắn vào một router node (router) |
| Sử dụng khi | Khi bạn muốn node đang xử lý tự quyết định rẽ nhánh tiếp theo | Khi bạn tách riêng logic định tuyến ra một router riêng biệt |
| Ví dụ hàm điều kiện | def decide_dring(state): return "coffee_node" if ... else "tea_node" |
def router(state): return "coffee_node" / "tea_node" / "fallback_node" |
| Thường dùng khi | Bạn muốn node_1 vừa xử lý vừa quyết định hướng đi tiếp |
Bạn muốn tách riêng xử lý (node) và định tuyến (router) một cách rõ ràng |
| Dạng | Ý nghĩa |
|---|---|
add_conditional_edges("node_1", decide_dring) |
Node xử lý xong rồi chọn tiếp theo đi đâu. |
add_conditional_edges("router", { ... }) |
Router chỉ quyết định hướng đi, còn xử lý nằm ở node khác. |
Khi nào dùng cái nào?
| Nếu bạn muốn... | Hãy dùng... |
|---|---|
| Một node tự quyết định rẽ nhánh tiếp theo | add_conditional_edges("node_1", decide_dring) |
| Một router chuyên dùng để rẽ nhánh | add_conditional_edges("router", { ... }) |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Bài Thực Hành Router Trong LangGraph
Mục tiêu: Tạo một LangGraph gồm các bước đơn giản, giúp người dùng quyết định sẽ uống Coffee hay Trà.
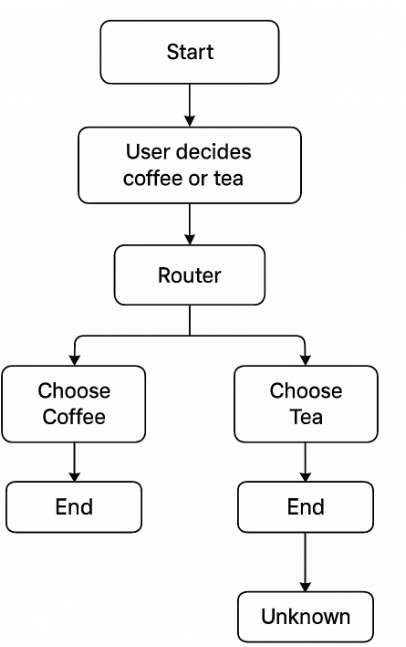
I. Cài đặt
* cd project_name
* pyenv local 3.11.4
* poetry install
* poetry shell
* jupyter labTạo .env file
OPENAI_API_KEY=your_openai_api_key
LANGCHAIN_TRACING_V2=true
LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
LANGCHAIN_API_KEY=your_langchain_api_key
LANGCHAIN_PROJECT=your_project_nameKết nối file .env
#pip install python-dotenvimport os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai_api_key = os.environ["OPENAI_API_KEY"]II. Kết nối LangChain
#!pip install langgraph langchain openaiIII. Định nghĩa State Schema (State = Memory)
from typing import TypedDict, Literal
class DrinkState(TypedDict):
preference: Literal["coffee", "tea", "unknown"]
TypedDict
-
Đây là một tính năng của Python (từ
typingmodule) cho phép bạn khai báo dictionary có cấu trúc rõ ràng, giống như mộtclass. -
Mục đích là để giúp IDE và trình kiểm tra kiểu như MyPy bắt lỗi sớm nếu bạn dùng sai key hoặc giá trị.
DrinkState
-
Là tên của lớp, đại diện cho trạng thái (state) của ứng dụng LangGraph của bạn.
preference: Literal["coffee", "tea", "unknown"]
-
Trường
preferencechỉ chấp nhận một trong ba giá trị cụ thể:"coffee","tea"hoặc"unknown". -
Đây là cách giới hạn giá trị hợp lệ, giúp bạn tránh lỗi như
"cofee"hay"t"do gõ sai.
IV. Định nghĩa các Nodes (mỗi Node là một Step)
# Node: Bắt đầu
def start_node(state: DrinkState) -> DrinkState:
print("👉 Bạn thích uống gì hôm nay?")
choice = input("Nhập 'coffee' hoặc 'tea': ").strip().lower()
if choice not in ["coffee", "tea"]:
choice = "unknown"
return {"preference": choice}
# Node: Nếu chọn coffee
def coffee_node(state: DrinkState) -> DrinkState:
print("☕ Bạn đã chọn Coffee! Tuyệt vời!")
return state
# Node: Nếu chọn tea
def tea_node(state: DrinkState) -> DrinkState:
print("🍵 Bạn đã chọn Trà! Thanh tao ghê!")
return state
# Node: Nếu nhập sai
def fallback_node(state: DrinkState) -> DrinkState:
print("Không rõ bạn chọn gì. Vui lòng thử lại.")
return state
V. Định nghĩa Router
def drink_router(state: DrinkState) -> str:
if state["preference"] == "coffee":
return "coffee_node"
elif state["preference"] == "tea":
return "tea_node"
else:
return "fallback_node"
VI. Xây dựng Graph
from langgraph.graph import StateGraph
builder = StateGraph(DrinkState)
# Thêm các nodes
builder.add_node("start", start_node)
builder.add_node("coffee_node", coffee_node)
builder.add_node("tea_node", tea_node)
builder.add_node("fallback_node", fallback_node)
builder.add_node("router", drink_router)
# Tạo flow giữa các bước
builder.set_entry_point("start")
builder.add_edge("start", "router")
builder.add_conditional_edges("router", {
"coffee_node": "coffee_node",
"tea_node": "tea_node",
"fallback_node": "fallback_node"
})
# Gắn điểm kết thúc cho mỗi nhánh
builder.set_finish_point("coffee_node")
builder.set_finish_point("tea_node")
builder.set_finish_point("fallback_node")
# Compile graph
app = builder.compile()
VII. Chạy thử
# Trạng thái khởi đầu rỗng
initial_state: DrinkState = {"preference": "unknown"}
final_state = app.invoke(initial_state)
Kết quả
Tùy người dùng nhập vào coffee hay tea, graph sẽ tự động điều hướng tới đúng bước xử lý, và in kết quả tương ứng.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Giới thiệu về ReAct Architecture
Kiến trúc ReAct là một mô hình rất quan trọng trong việc xây dựng các Agent dựa trên LLM. Tên “ReAct” là viết tắt của Reasoning and Acting – tức là kết hợp giữa lập luận và hành động. Đây là cách mà một Agent thông minh có thể thực hiện nhiều bước để hoàn thành một nhiệm vụ, thay vì chỉ trả lời một lần rồi kết thúc.
Giới thiệu về ReAct Architecture
ReAct cho phép các LLM (Large Language Models) hoạt động theo chu trình:
-
act (hành động)
Mô hình quyết định gọi một công cụ (tool) để thực hiện một hành động cụ thể. Ví dụ: tìm kiếm thông tin, tính toán, tra dữ liệu từ API, v.v. -
observe (quan sát)
Công cụ thực hiện hành động và trả về kết quả. Kết quả này sẽ được đưa trở lại LLM như một phần của cuộc hội thoại (hoặc “context”). -
reason (lập luận)
LLM tiếp nhận kết quả, phân tích và quyết định bước tiếp theo: có thể gọi thêm một công cụ khác, tiếp tục hỏi người dùng, hoặc kết thúc bằng một câu trả lời.
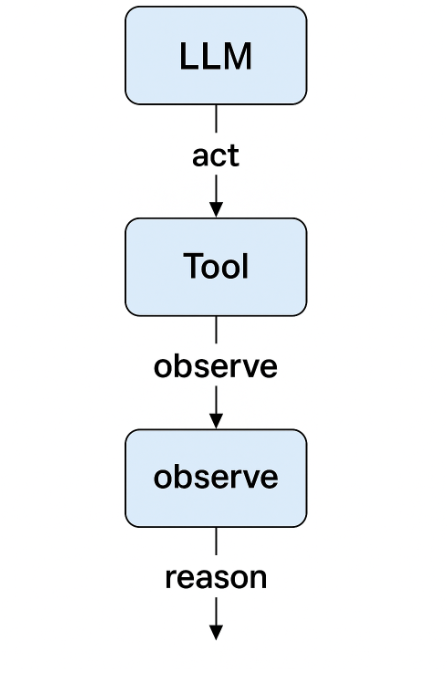
ReAct là cách mà AI (LLM) suy nghĩ và hành động như một con người:
“Nghĩ – Làm – Quan sát – Nghĩ tiếp – Làm tiếp…”
Câu chuyện đơn giản
Bạn nói với AI:
"Tính giúp tôi 3 + 5"
AI làm gì?
| Bước | Hành động | Giải thích dễ hiểu |
|---|---|---|
| Act | "Tôi sẽ gọi công cụ máy tính để tính toán" | (Gọi hàm calculator_tool) |
| Tool | Máy tính nhận yêu cầu, tính ra kết quả 8 |
|
| Observe | AI nhìn vào kết quả: 8 |
(Cập nhật kết quả vào bộ nhớ) |
| Reason | AI tự hỏi: “Người dùng muốn tính tiếp không?” | Nếu có, lặp lại từ đầu |
Ví dụ thực tế
Giả sử bạn hỏi:
"Hôm nay thời tiết ở TP Hồ Chí Minh như thế nào và tôi có nên mang ô không?"
Agent thực hiện:
-
act: Gọi một công cụ thời tiết để lấy dữ liệu thời tiết tại TP Hồ Chí Minh.
-
observe: Nhận được kết quả: "Trời có khả năng mưa vào chiều tối."
-
reason: LLM suy luận: "Trời có thể mưa → nên mang ô → trả lời người dùng."
Trả lời cuối cùng:
"Hôm nay TP Hồ Chí Minh có khả năng mưa vào chiều tối, bạn nên mang theo ô."
Ứng dụng của ReAct
-
Xây dựng multi-step agents: Giải quyết các bài toán phức tạp cần nhiều hành động trung gian.
-
Cho phép Agent có thể tự khám phá, điều chỉnh kế hoạch dựa trên kết quả trung gian.
-
Hữu ích trong các hệ thống như LangGraph, LangChain, nơi bạn cần điều phối nhiều bước và công cụ.
Ví dụ cơ bản
Tạo một agent hỏi người dùng một phép tính, gọi một công cụ để tính, rồi tiếp tục hỏi đến khi người dùng muốn dừng.
Kiến trúc Agent như sau
START
↓
LLM (hỏi phép tính)
↓
TOOL (tính kết quả)
↓
LLM (xem kết quả, hỏi tiếp hay kết thúc?)
→ Nếu tiếp → quay lại TOOL
→ Nếu kết thúc → END
1. Định nghĩa State
from typing import TypedDict, List, Optional
class CalcState(TypedDict):
history: List[str]
next_action: Optional[str]
question: Optional[str]
answer: Optional[str]
2. Tạo Tool Node
def calculator_tool(state: CalcState) -> CalcState:
question = state["question"]
try:
answer = str(eval(question)) # WARNING: chỉ dùng với ví dụ đơn giản!
except:
answer = "Không thể tính được."
state["answer"] = answer
state["history"].append(f"Q: {question}\nA: {answer}")
return state
3. Tạo LLM Node
def llm_node(state: CalcState) -> CalcState:
print("🧠 LLM: Tôi đang nghĩ...")
print(f"Câu hỏi: {state.get('question')}")
print(f"Kết quả: {state.get('answer')}")
# Quyết định bước tiếp theo
choice = input("Bạn muốn tiếp tục (yes/no)? ")
if choice.lower() == "no":
state["next_action"] = "end"
else:
new_q = input("Nhập phép tính mới: ")
state["question"] = new_q
state["next_action"] = "calculate"
return state
4. Router
def calc_router(state: CalcState) -> str:
return state["next_action"]5. Kết nối các bước bằng LangGraph
from langgraph.graph import StateGraph
builder = StateGraph(CalcState)
builder.add_node("llm_node", llm_node)
builder.add_node("tool_node", calculator_tool)
builder.add_node("router", calc_router)
builder.set_entry_point("llm_node")
builder.add_edge("llm_node", "router")
builder.add_conditional_edges("router", {
"calculate": "tool_node",
"end": "__end__"
})
builder.add_edge("tool_node", "llm_node")
graph = builder.compile()
- Dòng 5,6,7 Chúng ta thêm 3 nodes: llm_node, calculator_tool, calc_router
- Dòng 9, llm_node là được đặt là node đầu tiên
- Dòng 10, chúng ta nối node có id là llm_node với node có id là `router`(router là một node đặc biệt, node này không trả về một state mà trả về một chuỗi)
- Dòng 12, router thực hiện rẽ nhánh dựa trên add_conditional_edges
- "router" là id của node calc_router, nếu calc_router trả về "calculate" thì thực hiên tool_node, nếu calc_router trả về "end" thì thực hiện "__end__"
- Dòng 17, thực hiện nối "tool_node" với "llm_node" và tiếp tục
6. Chạy thử
state = {
"history": [],
"next_action": None,
"question": "2 + 3",
"answer": None,
}
graph.invoke(state)
Output mẫu
LLM: Tôi đang nghĩ...
Câu hỏi: 2 + 3
Kết quả: None
Nhập phép tính mới: 2 + 3
Q: 2 + 3
A: 5
Bạn muốn tiếp tục (yes/no)? yes
Nhập phép tính mới: 10 * 2
...
Tóm tắt kiến trúc ReAct
| Pha | Vai trò | Ý nghĩa |
|---|---|---|
Act |
LLM gọi công cụ | LLM yêu cầu tính một biểu thức toán học |
Observe |
Công cụ trả kết quả | Công cụ calculator_tool xử lý phép tính và trả về kết quả |
Reason |
LLM quyết định bước tiếp theo | Dựa trên kết quả, LLM quyết định tiếp tục hay dừng |
Tool |
Công cụ được LLM gọi | Ở đây là hàm calculator_tool dùng eval() để tính toán |
Phân tích chi tiết ví dụ trên
1. Act – LLM gọi công cụ
Trong hàm llm_node, nếu người dùng muốn tiếp tục:
state["next_action"] = "calculate"LLM quyết định hành động tiếp theo là gọi công cụ tính toán.
2. Observe – Công cụ trả kết quả
def calculator_tool(state: CalcState) -> CalcState:
...
state["answer"] = answerCông cụ thực hiện tính toán và cập nhật lại state (trạng thái) với kết quả.
LLM sẽ quan sát lại kết quả ở bước tiếp theo.
3. Reason – LLM quyết định tiếp theo
Sau khi đã có kết quả trong state["answer"], LLM đánh giá và hỏi:
choice = input("Bạn muốn tiếp tục (yes/no)? ")Nếu yes thì act lần nữa (gọi lại công cụ).
Nếu no thì kết thúc (gọi "end").
4. Tool – Công cụ độc lập
def calculator_tool(state: CalcState) -> CalcState:
...Đây chính là một công cụ (Tool) – thực hiện công việc cụ thể do LLM yêu cầu.
Nó không thông minh, chỉ đơn thuần xử lý dữ liệu đầu vào.
Tổng kết dễ hiểu
| Bước | Thành phần | Vai trò |
|---|---|---|
| 1 | llm_node |
Act: Quyết định gọi tool |
| 2 | calculator_tool |
Observe: Trả kết quả về |
| 3 | llm_node |
Reason: Xem kết quả và quyết định hành động tiếp theo |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thực hành – Node LLM quyết định bước tiếp theo
Chúng ta sẽ xây dựng lại ứng dụng trước đó, nhưng lần này sẽ bổ sung hành vi mang tính "agent" điển hình. Theo cách gọi của nhóm LangGraph, đây sẽ là Agent đầu tiên của chúng ta.
Những điểm chính:
-
Hành vi agent điển hình: node công cụ (tool node) sẽ phản hồi lại cho LLM, và sau đó LLM sẽ quyết định bước tiếp theo.
-
Node bao gồm chatbot, công cụ (tool), và thông điệp hệ thống (system message).
-
Các thao tác gọi công cụ theo trình tự (sequential tool-calling operations).
Agent Cơ Bản
-
Mục tiêu: Chúng ta sẽ xây dựng một ứng dụng tương tự như trong bài thực hành trước. Điểm khác biệt chính là trong ứng dụng lần này, node công cụ (tools node) sẽ phản hồi trở lại cho assistant (LLM) thay vì đi thẳng đến node KẾT THÚC (END Node).
-
Điều này thể hiện kiến trúc được gọi là ReAct: mô hình LLM sẽ tiếp tục sử dụng các công cụ cho đến khi nhận được phản hồi thỏa đáng.
-
act – LLM gọi một công cụ.
-
observe – công cụ trả kết quả lại cho LLM.
-
reason – LLM quyết định bước tiếp theo (gọi công cụ khác hoặc trả lời trực tiếp).
-
Thực hành
Tạo một agent sử dụng kiến trúc ReAct với quy trình:
-
Người dùng không biết chọn gì → LLM hỏi ý kiến.
-
LLM gọi một tool để kiểm tra trạng thái năng lượng người dùng.
-
Tool trả lời về mức năng lượng.
-
Dựa vào đó, LLM đưa ra lời khuyên nên uống trà hay cà phê.
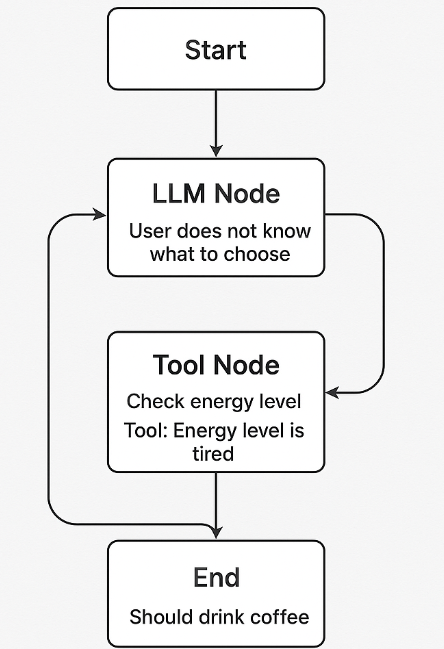
1. Cài đặt và chuẩn bị
pip install langgraph openai2. Định nghĩa State
from typing import TypedDict, Literal, Optional
class DrinkState(TypedDict):
preference: Literal["coffee", "tea", "unknown"]
energy_level: Optional[str]
messages: list[dict]3. Tạo công cụ kiểm tra năng lượng
def check_energy_level(state: DrinkState) -> DrinkState:
# Giả sử công cụ xác định người dùng đang "mệt"
energy = "tired"
state["energy_level"] = energy
state["messages"].append({"role": "tool", "content": f"Energy level is {energy}"})
return state4. Tạo node LLM để đưa ra quyết định
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0)
def llm_node(state: DrinkState) -> DrinkState:
messages = state["messages"]
response = llm.invoke(messages)
state["messages"].append({"role": "assistant", "content": response.content})
if "coffee" in response.content.lower():
state["preference"] = "coffee"
elif "tea" in response.content.lower():
state["preference"] = "tea"
return state5. Tạo Graph
from langgraph.graph import StateGraph
builder = StateGraph(DrinkState)
builder.add_node("llm", llm_node)
builder.add_node("check_energy", check_energy_level)
builder.set_entry_point("llm")
# LLM gọi tool rồi quay lại chính nó
builder.add_edge("llm", "check_energy")
builder.add_edge("check_energy", "llm")
# Thiết lập điểm kết thúc
builder.set_finish_point("llm")
graph = builder.compile()6. Chạy thử
initial_state = {
"preference": "unknown",
"energy_level": None,
"messages": [{"role": "user", "content": "Tôi không biết nên uống gì hôm nay"}],
}
final_state = graph.invoke(initial_state)
print("Gợi ý của Agent:", final_state["preference"])
Giải thích luồng hoạt động
-
Người dùng không đưa ra lựa chọn cụ thể.
-
LLM phân tích và quyết định cần kiểm tra mức năng lượng.
-
Tool
check_energytrả về trạng thái "mệt". -
LLM đưa ra khuyến nghị uống cà phê để tăng tỉnh táo.
-
Kết thúc.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Kết nối các công cụ (tools) bằng bind_tools
bind_tools là một tính năng trong LangChain (thường dùng với các mô hình như OpenAI’s GPT) để kết nối các công cụ (tools) với LLM. Nó cho phép mô hình gọi những tool đó khi cần, như tính toán, truy xuất thông tin, tra cứu, v.v.
ind_tools giúp bạn nói với LLM rằng:
"Ê, ngoài việc trả lời bằng văn bản, mày có thể gọi mấy tool này nếu thấy cần."
Cú pháp cơ bản
llm_with_tools = chat_model.bind_tools(
tools=[tool_1, tool_2],
parallel_tool_calls=False # hoặc True nếu muốn gọi song song nhiều tool
)
-
tools: danh sách các tool bạn định sử dụng (được định nghĩa trước). -
parallel_tool_calls: nếuTrue, mô hình có thể gọi nhiều tool một lúc (song song). NếuFalse, gọi từng cái một theo thứ tự.
Ví dụ đơn giản
Bước 1: Định nghĩa các tool
from langchain.tools import tool
@tool
def add(a: int, b: int) -> int:
"""Cộng hai số"""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Nhân hai số"""
return a * b
Bước 2: Bind tools vào mô hình
from langchain.chat_models import ChatOpenAI
chat_model = ChatOpenAI(model="gpt-4")
llm_with_tools = chat_model.bind_tools(
tools=[add, multiply],
parallel_tool_calls=False # toán học thường nên làm tuần tự
)
Bước 3: Gọi mô hình và để nó tự chọn tool
response = llm_with_tools.invoke("Hãy cộng 3 và 5 giúp tôi")
print(response.content)
Nếu LLM hiểu rằng cần thực hiện phép cộng, nó sẽ tự động gọi tool add(3, 5) và trả lại kết quả là 8.
bind_tools hữu ích vì
-
Modular hóa: LLM không cần biết cách hoạt động nội bộ của tool, chỉ cần mô tả chức năng.
-
Mở rộng dễ dàng: Bạn có thể thêm bao nhiêu tool tùy thích.
-
Tự động lựa chọn: LLM tự chọn tool phù hợp dựa trên yêu cầu người dùng.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Xây dựng một ứng dụng quyết định xem có nên trò chuyện bằng LLM hay sử dụng công cụ

1. Cài đặt
* cd project_name
* pyenv local 3.11.4
* poetry install
* poetry shell
* jupyter lab2. Tạo .env file
* OPENAI_API_KEY=your_openai_api_key
* LANGCHAIN_TRACING_V2=true
* LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
* LANGCHAIN_API_KEY=your_langchain_api_key
* LANGCHAIN_PROJECT=your_project_name3. Kết nối file .env
#pip install python-dotenvimport os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai_api_key = os.environ["OPENAI_API_KEY"]4. Cài đặt LangChain
#!pip install langchain
#!pip install langchain-openaifrom langchain_openai import ChatOpenAI
chatModel35 = ChatOpenAI(model="gpt-3.5-turbo-0125")
chatModel4o = ChatOpenAI(model="gpt-4o")5. LLM với các công cụ
from langchain.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
tools = [add, multiply, divide]
llm_with_tools = chatModel4o.bind_tools(tools, parallel_tool_calls=False)Define the State schema
from langgraph.graph import MessagesState
class MessagesState(MessagesState):
# Add any keys needed beyond messages, which is pre-built
passDefine the first Node
from langchain_core.messages import HumanMessage, SystemMessage
# System message, system prompt
sys_msg = SystemMessage(content="You are a helpful assistant tasked with performing arithmetic on a set of inputs.")
# Node
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}* Các nút của đồ thị được định nghĩa là các hàm python.
* Đối số đầu tiên của hàm Node là trạng thái. Do đó, trong bài tập này, mỗi nút có thể truy cập khóa `messages`, với `state['messages']`.
* Trong ví dụ này, chúng ta sẽ bắt đầu bằng một nút tương tự như nút chúng ta đã tạo trong bài tập trước, **nhưng lần này bằng SystemMessage**:
Kết hợp các nút và cạnh để xây dựng đồ thị
from langgraph.graph import START, StateGraph
from langgraph.prebuilt import tools_condition
from langgraph.prebuilt import ToolNode
from IPython.display import Image, display
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# Add the logic of the graph
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# If the latest message (result) from assistant is a tool call -> tools_condition routes to tools
# If the latest message (result) from assistant is a not a tool call -> tools_condition routes to END
tools_condition,
)
# PAY ATTENTION HERE: from the tools node, back to the assistant
builder.add_edge("tools", "assistant")
# PAY ATTENTION: No END edge.
# Compile the graph
react_graph = builder.compile()
# Visualize the graph
display(Image(react_graph.get_graph(xray=True).draw_mermaid_png()))
* act - LLM gọi một công cụ.
* observer - công cụ chuyển đầu ra trở lại LLM.
* reason - LLM quyết định phải làm gì tiếp theo (gọi một công cụ khác hoặc phản hồi trực tiếp).
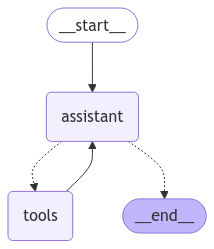
Chạy ứng dụng
messages = [HumanMessage(content="What was the relationship between Marilyn and JFK?")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()================================ Human Message =================================
What was the relationship between Marilyn and JFK?
================================== Ai Message ==================================
Marilyn Monroe and President John F. Kennedy (JFK) are often rumored to have had a romantic relationship, though concrete details about the nature and extent of their relationship remain speculative and are part of popular lore. The most famous public connection between them was Marilyn Monroe's sultry performance of "Happy Birthday, Mr. President" at a Democratic Party fundraiser and early birthday celebration for Kennedy in May 1962. However, both contemporaneous accounts and historical research have not conclusively proven a long-term affair, and much of the speculation is based on anecdotal evidence and hearsay.messages = [HumanMessage(content="Add 3 and 4. Multiply the output by 2. Divide the output by 5")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()================================ Human Message =================================
Add 3 and 4. Multiply the output by 2. Divide the output by 5
================================== Ai Message ==================================
Tool Calls:
add (call_UR7Cp0pbVpRyof8Dyq4kZUHm)
Call ID: call_UR7Cp0pbVpRyof8Dyq4kZUHm
Args:
a: 3
b: 4
================================= Tool Message =================================
Name: add
7
================================== Ai Message ==================================
Tool Calls:
multiply (call_OiwYtGUW13AY8CB3qY3Y3Vlt)
Call ID: call_OiwYtGUW13AY8CB3qY3Y3Vlt
Args:
a: 7
b: 2
================================= Tool Message =================================
Name: multiply
14
...
2.8
================================== Ai Message ==================================
The final result after adding 3 and 4, multiplying the result by 2, and then dividing by 5 is 2.8.Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tóm tắt chương
Tạm dừng một chút để cùng nhau ôn lại những gì chúng ta đã học được nhé!
Chúng ta bắt đầu chương này với cảm giác khá lo lắng – có lẽ bạn cũng từng nghĩ: "Cái LangGraph này nghe thật rối rắm và phức tạp", đúng không? Những khái niệm nghe có vẻ như dành riêng cho những người có siêu năng lực, phải có bằng tiến sĩ hay ít nhất là thạc sĩ mới hiểu nổi cách dùng nó!
Nhưng rồi khi đi đến cuối chương, ta nhận ra rằng ai cũng có thể xây dựng ứng dụng với LangGraph. Đằng sau những thuật ngữ nghe phức tạp đó thật ra lại là những khái niệm rất đơn giản. Và chúng ta đã thấy rằng bất kỳ ai cũng có thể tạo ra những agent thông minh, thậm chí là những ứng dụng có thể thay đổi cả thế giới.
Vậy cụ thể, ta đã làm gì?
-
Đầu tiên, chúng ta học các khái niệm cơ bản của một ứng dụng LangGraph: state là gì, schema của state là gì, node là gì, edge là gì, quá trình compile là gì...
-
Sau đó, ta xây dựng một app đơn giản dự đoán người dùng sẽ chọn Trà hay Coffee.
-
Ta học được quy trình 5 bước để xây dựng một ứng dụng LangGraph:
-
Định nghĩa state.
-
Thêm node và edge.
-
Biên dịch (compile).
-
Hiển thị sơ đồ (visualize).
-
Chạy ứng dụng.
-
Đơn giản đúng không nào?
-
Tiếp theo, ta xây dựng một chatbot sử dụng LangGraph, học về khái niệm reducer – một từ nghe "kêu" nhưng thực chất chỉ là cách để cập nhật lại state theo cách riêng của mình.
-
Ta sử dụng các module có sẵn như
message state, giúp giảm lượng code cần viết. -
Sau đó, ta nâng cấp chatbot bằng cách thêm tool và xây dựng hành vi agent, nơi mà ứng dụng quyết định dùng chatbot hay gọi tool để trả lời người dùng.
-
Ta học cách dùng
tool nodevàtool condition, tạo router để định tuyến theo điều kiện đầu vào.
Và cuối cùng, ta đã tạo ra agent đầu tiên của mình bằng cách cho phép tool phản hồi trở lại LLM – chính là mô hình ReAct: act (gọi tool), observe (quan sát kết quả), reason (suy luận xem làm gì tiếp theo).
Sắp tới là gì?
Trong chương tiếp theo, chúng ta sẽ khám phá một chủ đề cực kỳ quan trọng trong thế giới LangGraph: Memory (Bộ nhớ).
Dù trước giờ ta đã nói về state và một chút về memory, nhưng bạn sẽ thấy rằng, trong LangGraph, memory không đơn giản chỉ là lưu trữ thông tin – nó là cốt lõi để tạo ra những agent thông minh và có tính phản hồi cao.
Hãy chuẩn bị tinh thần để bước vào một chương siêu hấp dẫn nhé!
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Memory (Bộ nhớ)
Một trong những yếu tố quan trọng nhất để tạo nên sự khác biệt giữa một agent “bình thường” và một agent “đỉnh cao” sẵn sàng chạy trên môi trường thực tế (production).
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Giới Thiệu
Tiếp tục hành trình – Bước vào một chủ đề cực kỳ quan trọng: Memory (Bộ nhớ) trong LangGraph
Trong phần này, chúng ta sẽ đào sâu vào một chủ đề đóng vai trò sống còn khi xây dựng agent bằng LangGraph – đó chính là memory (bộ nhớ). Và không chỉ nói đến trí nhớ ngắn hạn(short term memory), mà cả trí nhớ dài hạn(long term memory) nữa!
Ngay từ đầu, bạn sẽ nhận ra: đây chính là một trong những yếu tố quan trọng nhất để tạo nên sự khác biệt giữa một agent “bình thường” và một agent “đỉnh cao” sẵn sàng chạy trên môi trường thực tế (production).
Nói đơn giản:
Ứng dụng của bạn có thật sự thông minh và đáng nhớ hay chỉ dừng lại ở mức “cho vui” – tất cả nằm ở cách bạn xử lý memory.
Vậy chúng ta sẽ học gì?
Chúng ta sẽ bắt đầu với phần dễ trước – trí nhớ ngắn hạn(short term memory). Đây là loại bộ nhớ gắn liền với cuộc trò chuyện hiện tại giữa người dùng và agent.
Nếu bạn muốn agent của mình hiểu được mạch hội thoại (biết bạn vừa nói gì, nhớ câu hỏi trước, không bị “mất trí nhớ ngắn hạn”), thì bạn cần phải kích hoạt trí nhớ dài hạn(long term memory) cho nó.
Và bạn sẽ thấy: Việc này cực kỳ đơn giản với LangGraph.
Có những thứ bạn cần nắm trước
Trong tài liệu chính thức của LangGraph, khi họ bắt đầu nói về memory, họ thường đưa ra rất nhiều khái niệm như:
-
cách định dạng schema của state,
-
dùng reducer tùy chỉnh (custom reducers),
-
hay sử dụng nhiều schema trạng thái trong một ứng dụng.
Thành thật mà nói, cách LangGraph viết tài liệu không phải lúc nào cũng dễ hiểu, thậm chí có thể gây rối nếu bạn mới bắt đầu.
Vì vậy, chúng ta sẽ làm rõ ba khái niệm đó trước – theo cách đơn giản, trực quan và đúng bản chất, giúp bạn hiểu sâu mà không bị rối bởi quá nhiều dòng code.
Mục tiêu của phần này là gì?
-
Giúp bạn hiểu rõ trí nhớ ngắn hạn(short term memory) hoạt động như thế nào trong LangGraph.
-
Làm quen với các khái niệm nâng cao:
state schema,custom reducer, vàmultiple schemas. -
Tập trung vào phần tư duy và logic, không sa đà vào chi tiết lập trình.
Hãy sẵn sàng! Trong những bài tiếp theo, chúng ta sẽ cùng nhau khám phá kỹ hơn về 4 khái niệm trên, với những ví dụ thực tế và trực quan nhất.
Bạn chỉ cần nhớ: đừng để tài liệu khó hiểu làm bạn nản lòng – chúng ta sẽ đi từng bước, và bạn chắc chắn sẽ làm được.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thêm Bộ Nhớ Ngắn Hạn vào Agent trong LangGraph
Trong bài học này, chúng ta sẽ tìm hiểu cách thêm bộ nhớ ngắn hạn (short-term memory) vào agent để nó có thể ghi nhớ ngữ cảnh của cuộc trò chuyện. Điều này giúp agent hiểu được các yêu cầu liên tiếp từ người dùng một cách chính xác hơn.
Vấn đề của Agent Không Có Bộ Nhớ
Trong bài tập trước, chúng ta đã xây dựng một agent đơn giản có thể thực hiện các phép tính toán học bằng cách di chuyển qua các node "assistant" và "tools". Tuy nhiên, agent này có một hạn chế lớn: nó không có bộ nhớ.
Ví dụ minh họa:
-
Người dùng yêu cầu:
"3 + 5."
→ Agent trả lời: "Tổng của 3 + 5 = 8" -
Người dùng tiếp tục:
"nhân kết quả với 2"
Nếu agent không có bộ nhớ, nó sẽ không hiểu "kết quả" ám chỉ kết quả trước đó và yêu cầu người dùng cung cấp lại số:
"Tôi cần một số cụ thể để nhân với hai. Bạn vui lòng cung cấp số bạn muốn nhân"
Điều này gây bất tiện vì người dùng phải lặp lại thông tin đã cung cấp trước đó.
Cách Thêm Bộ Nhớ Ngắn Hạn vào Agent
Trong LangGraph, việc thêm bộ nhớ ngắn hạn rất đơn giản bằng cách sử dụng module MemorySaver. Module này giúp lưu trữ thông tin tạm thời trong một phiên hội thoại cụ thể.
1. Sử dụng MemorySaver tại bước compile
Khi khởi tạo agent, chúng ta thêm bộ nhớ vào trong quá trình compile:
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
react_graph_memory = builder.compile(checkpointer=memory)2. Sử dụng thread_id để phân biệt các cuộc hội thoại
Để đảm bảo bộ nhớ chỉ áp dụng cho một phiên trò chuyện cụ thể, ta sử dụng thread_id khi gọi invoke:
config = {"configurable": {"thread_id": "1"}}
messages = [HumanMessage(content="Add 3 and 4.")]
messages = react_graph_memory.invoke({"messages": messages},config)
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thực hành bộ nhớ ngắn hạn
Trong bài học này, chúng ta sẽ học cách thêm bộ nhớ ngắn hạn vào agent của mình.
1. Cài đặt
Tại console:
* cd project_name
* pyenv local 3.11.4
* poetry install
* poetry shell
* jupyter lab2. Tạo file .env
* OPENAI_API_KEY=your_openai_api_key
* LANGCHAIN_TRACING_V2=true
* LANGCHAIN_ENDPOINT=https://api.smith.langchain.com
* LANGCHAIN_API_KEY=your_langchain_api_key
* LANGCHAIN_PROJECT=your_project_name3. Kết nối với tệp .env nằm trong cùng thư mục của notebook
#pip install python-dotenvimport os
from dotenv import load_dotenv, find_dotenv
_ = load_dotenv(find_dotenv())
openai_api_key = os.environ["OPENAI_API_KEY"]3. Cài đặt LangChain
#!pip install langchain
#!pip install langchain-openaifrom langchain_openai import ChatOpenAI
chatModel35 = ChatOpenAI(model="gpt-3.5-turbo-0125")
chatModel4o = ChatOpenAI(model="gpt-4o")4. LLM kết hợp với nhiều công cụ hỗ trợ
from langchain_openai import ChatOpenAI
from langchain.tools import tool
@tool
def multiply(a: int, b: int) -> int:
"""Multiply a and b.
Args:
a: first int
b: second int
"""
return a * b
@tool
def add(a: int, b: int) -> int:
"""Adds a and b.
Args:
a: first int
b: second int
"""
return a + b
@tool
def divide(a: int, b: int) -> float:
"""Divide a and b.
Args:
a: first int
b: second int
"""
return a / b
tools = [add, multiply, divide]
llm_with_tools = chatModel4o.bind_tools(tools, parallel_tool_calls=False)parallel_tool_calls=True
Đây là gọi công cụ song song (chạy nhiều công cụ cùng lúc).
-
Ý tưởng: Nếu mô hình cần gọi nhiều công cụ để trả lời người dùng, nó có thể gọi tất cả các công cụ cùng một lúc, không cần chờ từng cái chạy xong.
-
Ưu điểm: Nhanh hơn! Vì các công cụ chạy đồng thời.
-
Khi nào nên dùng: Khi các công cụ không phụ thuộc vào kết quả của nhau. Ví dụ: bạn hỏi đồng thời "thời tiết ở TP. Hồ Chí Minh?" và "giá Bitcoin hôm nay?" — hai việc này độc lập nhau.
parallel_tool_calls=False
Đây là gọi công cụ tuần tự (chạy lần lượt từng cái một).
-
Ý tưởng: Mỗi công cụ được gọi theo thứ tự, cái sau có thể dùng kết quả của cái trước.
-
Ưu điểm: Giữ đúng logic nếu cần kết quả từng bước.
-
Khi nào nên dùng: Khi các công cụ phụ thuộc lẫn nhau. Ví dụ:
-
Bước 1: Tính tổng
-
Bước 2: Dùng kết quả tổng để chia 2
→ Phải làm từng bước theo thứ tự.
-
Chi tiết tại
https://python.langchain.com/docs/how_to/tool_calling_parallel/
5. Xây dựng một ứng dụng (gọi là đồ thị trong langgraph) quyết định xem có nên trò chuyện bằng LLM hay sử dụng công cụ
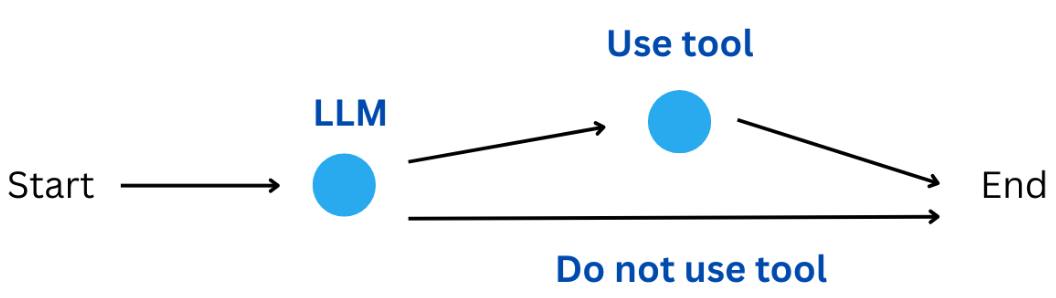
5.1 Định nghĩa State schema
from langgraph.graph import MessagesState
class MessagesState(MessagesState):
# Add any keys needed beyond messages, which is pre-built
pass5.2 Định nghĩa Node đầu tiên
from langgraph.graph import MessagesState
from langchain_core.messages import HumanMessage, SystemMessage
# Khai báo System message
sys_msg = SystemMessage(content="Bạn là trợ lý hữu ích có nhiệm vụ thực hiện phép tính số học trên một tập hợp dữ liệu đầu vào.")
# Định nghĩa Node
def assistant(state: MessagesState):
return {"messages": [llm_with_tools.invoke([sys_msg] + state["messages"])]}[sys_msg] + state["messages"]
- sys_msg là 1 SystemMessage định hướng vai trò AI, ví dụ: SystemMessage(content="Bạn là trợ lý toán học.")
state["messages"]: là các tin nhắn trước đó (giữa người dùng và AI).
5.3. Kết hợp các Node và Edge để xây dựng Graph
from langgraph.graph import START, StateGraph
from langgraph.prebuilt import tools_condition
from langgraph.prebuilt import ToolNode
from IPython.display import Image, display
# Build graph
builder = StateGraph(MessagesState)
builder.add_node("assistant", assistant)
builder.add_node("tools", ToolNode(tools))
# Add the logic of the graph
builder.add_edge(START, "assistant")
builder.add_conditional_edges(
"assistant",
# Nếu câu trả lời gần nhất của assistant là một lời gọi tới tool, Thì điều kiện tools_condition sẽ quyết định đi tiếp đến node tools
# Ngược lại, tools_condition sẽ quyết định chuyển sang node END (kết thúc luồng, trả kết quả ra ngoài).
tools_condition,
)
# PAY ATTENTION HERE: from the tools node, back to the assistant
builder.add_edge("tools", "assistant")
# PAY ATTENTION: No END edgge.
# Compile the graph
react_graph = builder.compile()
# Visualize the graph
display(Image(react_graph.get_graph(xray=True).draw_mermaid_png()))
5.4 Chạy ứng dụng
messages = [HumanMessage(content="Add 3 and 4.")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()================================ Human Message ================================= Add 3 and 4. ================================== Ai Message ================================== Tool Calls: add (call_AKxpCcslEcimrNFvBEWZ2Ru3) Call ID: call_AKxpCcslEcimrNFvBEWZ2Ru3 Args: a: 3 b: 4 ================================= Tool Message ================================= Name: add 7 ================================== Ai Message ================================== The sum of 3 and 4 is 7.
5.5 Tiếp tục hỏi Agent
messages = [HumanMessage(content="Multiply that by 2.")]
messages = react_graph.invoke({"messages": messages})
for m in messages['messages']:
m.pretty_print()================================ Human Message ================================= Multiply that by 2. ================================== Ai Message ================================== I need a specific number to multiply by 2. Could you please provide the number you want to multiply?
Như bạn thấy, Agent yêu cầu cung cấp một số cụ thể để thực hiện phép tính nhân, nó không nhớ được kết quả của phép tính cộng đã thực hiện ở trên
6. Thêm bộ nhớ
from langgraph.checkpoint.memory import MemorySaver
memory = MemorySaver()
react_graph_memory = builder.compile(checkpointer=memory)# PAY ATTENTION HERE: see how we specify a thread
config = {"configurable": {"thread_id": "1"}}
# Enter the input
messages = [HumanMessage(content="Add 3 and 4.")]
# PAY ATTENTION HERE: see how we add config to referr to the thread_id
messages = react_graph_memory.invoke({"messages": messages},config)
for m in messages['messages']:
m.pretty_print()Kết quả
================================ Human Message ================================= Add 3 and 4. ================================== Ai Message ================================== Tool Calls: add (call_7lH6zvBw4rMeTG3Zu66i53eW) Call ID: call_7lH6zvBw4rMeTG3Zu66i53eW Args: a: 3 b: 4 ================================= Tool Message ================================= Name: add 7 ================================== Ai Message ================================== The sum of 3 and 4 is 7.
Tiếp tục yêu cầu phép tính nhân
# PAY ATTENTION HERE: see how we check if the app has memory
messages = [HumanMessage(content="Multiply that by 2.")]
# Again, see how we use config here to referr to the thread_id
messages = react_graph_memory.invoke({"messages": messages}, config)
for m in messages['messages']:
m.pretty_print()================================ Human Message ================================= Multiply that by 2. ================================== Ai Message ================================== Tool Calls: multiply (call_x3tKpGBsTHUCbVwzBr3PiNn1) Call ID: call_x3tKpGBsTHUCbVwzBr3PiNn1 Args:
14 ================================== Ai Message ================================== The result of multiplying 7 by 2 is 14.
Agent đã nhớ được kết quả của phép tính cộng và thực hiện phép tính nhân
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Định dạng state schema trong LangGraph từ TypeDict sang Pydantic
Trong ba bài học tiếp theo, chúng tôi sẽ giới thiệu cho bạn về một số khái niệm thú vị mà bạn sẽ gặp trong tài liệu của LangGraph, đặc biệt là trong phần memo.
Tuy nhiên, ở thời điểm này, những khái niệm này có thể gây xao nhãng cho bạn. Vì vậy, chúng tôi không khuyến khích bạn đào sâu vào các chủ đề này ngay lúc này. Mục tiêu là giúp bạn hiểu khái niệm và biết nơi có thể tìm hiểu thêm khi cần thiết.
Chủ đề đầu tiên là các cách định dạng state schema trong LangGraph.
Nếu bạn còn nhớ, khi tạo state schema trong các bài tập trước, chúng ta luôn sử dụng loại TypeDict.
TypeDict là một cách rất đơn giản để xây dựng state schema.
Tuy nhiên, khi bạn làm việc với các ứng dụng ở cấp độ production, cách này có thể quá đơn giản và thiếu tính an toàn, đặc biệt trong việc phát hiện lỗi hoặc cảnh báo khi có điều gì đó sai trong ứng dụng của bạn.
Trong bài học này, chúng tôi sẽ giải thích nội dung mà tài liệu của LangGraph đề cập về các cách định dạng state schema:
Bao gồm:
-
Cách sử dụng
TypeDict(cơ bản nhất) -
Sử dụng
Literalđể làm choTypeDictmạnh mẽ hơn -
Sử dụng
dataclass(tiến bộ hơn) -
Cuối cùng và quan trọng nhất: sử dụng
Pydantic
I. TypeDict trong State Schema
TypeDict là một cách đơn giản và nhanh chóng để định nghĩa state schema – tức là cấu trúc trạng thái (state) mà LangGraph sẽ lưu trữ và truyền giữa các node (hoặc giữa LLM và công cụ).
Nó là một alias của TypedDict trong Python, được dùng để định nghĩa dictionary có kiểu rõ ràng cho từng key.
Khi nào nên dùng TypeDict?
-
Khi bạn muốn tạo state đơn giản
-
Phù hợp với các ứng dụng nhỏ hoặc giai đoạn thử nghiệm
-
Không yêu cầu xác thực đầu vào quá nghiêm ngặt
Cách định nghĩa State Schema với TypeDict
from typing import TypedDict
class MyState(TypedDict):
name: str
mood: str
count: intTrong ví dụ trên, MyState định nghĩa một state có 3 trường:
-
name: kiểustr -
mood: kiểustr -
count: kiểuint
Ví dụ trong LangGraph
from langgraph.graph import StateGraph
# Định nghĩa schema bằng TypeDict
class State(TypedDict):
name: str
mood: str
# Tạo Graph với state schema
builder = StateGraph(State)
# Add nodes, edges... (ví dụ đơn giản)
def greet(state: State) -> State:
print(f"Hello, {state['name']}! You seem {state['mood']} today.")
return state
builder.add_node("greet", greet)
builder.set_entry_point("greet")
app = builder.compile()
# Chạy thử
initial_state = {"name": "Alice", "mood": "happy"}
app.invoke(initial_state)Lưu ý khi dùng TypeDict
-
Không kiểm tra giá trị hợp lệ – ví dụ, nếu bạn muốn
moodchỉ nhận"happy"hoặc"sad", thì TypeDict không báo lỗi nếu bạn truyền"angry". -
Không hỗ trợ xác thực dữ liệu phức tạp
-
Nếu state sai kiểu (ví dụ
count="abc"), nó vẫn có thể chạy mà không báo lỗi rõ ràng
| Ưu điểm | Hạn chế |
|---|---|
| Dễ viết, nhanh chóng | Không xác thực dữ liệu |
| Phù hợp cho prototyping(giai đoạn thử nghiệm hoặc xây dựng bản mẫu) | Dễ gây lỗi trong ứng dụng lớn |
| Sử dụng chuẩn Python typing | Không cảnh báo khi sai dữ liệu |
II. Literal
Trong Python, Literal được cung cấp bởi thư viện typing và cho phép bạn ràng buộc giá trị của một biến chỉ được phép nằm trong một tập hợp cụ thể. Đây là một cách tuyệt vời để tăng tính an toàn cho state schema, đảm bảo rằng người dùng hoặc ứng dụng chỉ có thể nhập những giá trị hợp lệ.
Literal trong State Schema
Khi định nghĩa trạng thái (state) trong LangGraph, bạn có thể muốn giới hạn một trường nào đó chỉ nhận một số giá trị nhất định.
Ví dụ: trạng thái "mood" chỉ được là "happy" hoặc "sad" — không được là "angry", "confused", v.v.
Ví dụ 1
from typing import TypedDict, Literal
class MyState(TypedDict):
mood: Literal["happy", "sad"]Trong ví dụ trên:
-
Trường
moodchỉ được nhận một trong hai giá trị:"happy"hoặc"sad". -
Nếu bạn cố gắng gán giá trị khác như
"excited"hoặc"angry", thì trình phân tích tĩnh (hoặc các công cụ nhưpydantic) sẽ cảnh báo lỗi.
Ví dụ 2
from typing import TypedDict, Literal
class UserState(TypedDict):
name: str
mood: Literal["happy", "sad"]Giá trị hợp lệ:
state: UserState = {
"name": "Alice",
"mood": "happy"
}Giá trị không hợp lệ (trình kiểm tra type sẽ cảnh báo):
state: UserState = {
"name": "Alice",
"mood": "angry" # ❌ Không nằm trong Literal["happy", "sad"]
}Trong LangGraph, bạn có thể sử dụng Literal để đảm bảo rằng luồng logic của bạn hoạt động đúng như mong đợi.
Ví dụ:
class WorkflowState(TypedDict):
step: Literal["start", "processing", "done"]
Với định nghĩa này, bạn có thể đảm bảo:
-
Chỉ các bước
"start","processing", hoặc"done"mới được sử dụng. -
Tránh lỗi do nhập sai chuỗi hoặc thiếu kiểm tra logic.
III. dataclass để tạo state schema
Nhắc lại dataclass trong python
dataclasses giúp bạn tự động tạo ra các phương thức như:
-
__init__()– hàm khởi tạo -
__repr__()– biểu diễn đối tượng -
__eq__()– so sánh bằng -
__hash__()– dùng cho tập hợp, từ điển -
__lt__(),__le__()... nếu bạn bậtorder=True
Ví dụ
from dataclasses import dataclass
@dataclass
class Person:
name: str
age: intPython sẽ tự động sinh ra:
def __init__(self, name: str, age: int):
self.name = name
self.age = agedataclass để tạo state schema(Chi tiết về dataclass tại đây)
from dataclasses import dataclass
@dataclass
class ConversationState:
name: str
mood: str
count: int = 0 # Giá trị mặc định
__post_init__: logic sau khi khởi tạo
@dataclass
class State:
name: str
mood: str
def __post_init__(self):
if self.mood not in ["happy", "sad"]:
raise ValueError("Mood must be 'happy' or 'sad'")
Hợp lệ
state = State(name="Lan", mood="happy")
print(state)
# Output: ConversationState(name='Lan', mood='happy')Không hợp lệ
state = State(name="Lan", mood="angry")
# Output: ValueError: Mood must be 'happy' or 'sad'
IV. Dùng Pydantic làm State Schema trong LangGraph
Trong LangGraph, State Schema định nghĩa cấu trúc dữ liệu sẽ được truyền và cập nhật giữa các node trong graph.
Pydantic là một thư viện mạnh mẽ giúp xác thực dữ liệu, kiểm tra lỗi đầu vào và định kiểu rõ ràng, rất phù hợp cho các ứng dụng thực tế (production-level).
Ưu điểm khi dùng Pydantic cho State Schema
-
Tự động kiểm tra và xác thực dữ liệu đầu vào
-
Xác định kiểu dữ liệu rõ ràng, dễ đọc
-
Hiển thị lỗi rõ ràng và chi tiết khi dữ liệu không đúng định dạng
-
Dễ mở rộng, dễ bảo trì khi project phức tạp hơn
Cách định nghĩa State Schema bằng Pydantic
Bạn sẽ tạo một lớp kế thừa từ pydantic.BaseModel.
Mỗi thuộc tính của lớp đại diện cho một phần trong trạng thái.
1. Cài đặt pydantic
pip install pydantic2. Tạo State
from pydantic import BaseModel
from typing import Literal
class MyState(BaseModel):
name: str
age: int
mood: Literal["happy", "sad"]
-
name: bắt buộc phải là chuỗi (str) -
age: là số nguyên -
mood: chỉ chấp nhận"happy"hoặc"sad"→ nếu giá trị khác sẽ báo lỗi
Ví dụ sử dụng trong LangGraph:
from langgraph.graph import StateGraph, END
from langgraph.checkpoint import MemorySaver
# Định nghĩa schema với Pydantic
class State(BaseModel):
name: str
mood: Literal["happy", "sad"]
# Node đơn giản: in trạng thái hiện tại
def print_state(state: State):
print(f"👤 {state.name} đang cảm thấy {state.mood}")
return state
# Tạo graph
builder = StateGraph(State)
builder.add_node("printer", print_state)
builder.set_entry_point("printer")
builder.set_finish_point("printer")
# Chạy
graph = builder.compile()
graph.invoke({"name": "An", "mood": "happy"}) # ✅ OK
graph.invoke({"name": "An", "mood": "angry"}) # ❌ Gây lỗi ValidationError
Khi có lỗi, bạn sẽ thấy:
ValidationError: 1 validation error for State
mood
unexpected value; permitted: 'happy', 'sad' (type=value_error.const; given=angry; permitted=('happy', 'sad'))
Mở rộng với mặc định và tùy chỉnh:
from pydantic import Field
class State(BaseModel):
name: str = Field(..., description="Tên người dùng")
mood: Literal["happy", "sad"] = "happy" # mặc định là happy
-
Đây là cách bạn tạo một State Schema trong LangGraph bằng
Pydantic. -
BaseModellà lớp cơ sở của Pydantic dùng để định nghĩa và kiểm tra kiểu dữ liệu.
name: str = Field(..., description="Tên người dùng")
-
namelà một thuộc tính bắt buộc phải là chuỗi (str). -
Field(...)với dấu ba chấm...có nghĩa là giá trị này bắt buộc phải được truyền vào. -
description="Tên người dùng"chỉ là mô tả – không bắt buộc, nhưng hữu ích khi dùng để sinh docs hoặc debug.
Nếu bạn không truyền name, bạn sẽ nhận được lỗi:
ValidationError: 1 validation error for State
name
field required (type=value_error.missing)mood: Literal["happy", "sad"] = "happy"
-
moodlà một thuộc tính tùy chọn với giá trị mặc định là"happy". -
Literal["happy", "sad"]có nghĩa là: chỉ được phép là"happy"hoặc"sad". Bất kỳ giá trị nào khác đều bị từ chối. -
= "happy"nghĩa là nếu người dùng không truyền giá trịmood, thì mặc định sẽ là"happy".
State(name="An") # OK, mood mặc định là "happy"
State(name="An", mood="sad") # OK
State(name="An", mood="angry") # ❌ Lỗi vì "angry" không nằm trong ["happy", "sad"]
Tổng kết:
| Thành phần | Giải thích |
|---|---|
Field(...) |
Đánh dấu giá trị là bắt buộc |
description |
Ghi chú mô tả, dùng cho docs |
Literal[...] |
Ràng buộc giá trị chỉ được nằm trong một tập hợp cố định |
= "giá trị" |
Thiết lập giá trị mặc định nếu không truyền vào |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Cách Tùy Chỉnh Cập Nhật Trạng Thái bằng Reducers
Trong LangGraph, Reducers là những hàm đặc biệt được sử dụng để tổng hợp dữ liệu hoặc kết hợp trạng thái khi có nhiều luồng song song (parallel branches) trả về kết quả khác nhau.
Nói cách khác:
Khi bạn chạy nhiều node cùng lúc (parallel), và muốn gom kết quả từ chúng lại để đưa vào bước tiếp theo – thì bạn cần một Reducer.
Bạn cần dùng Reducer khi:
-
Bạn có các nhánh song song trong graph.
-
Mỗi nhánh thực hiện công việc riêng và trả về một phần kết quả.
-
Bạn cần gom các kết quả đó về một trạng thái chung trước khi đi tiếp.
| Mục đích | Chi tiết |
|---|---|
| Kết hợp dữ liệu | Khi có nhiều nhánh chạy song song |
| Nhận đầu vào | Một danh sách các trạng thái (dict) |
| Trả đầu ra | Một trạng thái duy nhất đã được tổng hợp |
| Ứng dụng | Tổng hợp kết quả LLM, kết hợp thông tin từ nhiều nguồn |
Giả sử bạn có 3 nhánh song song:
-
Node A xử lý phần tên.
-
Node B xử lý địa chỉ.
-
Node C xử lý số điện thoại.
Sau khi 3 node này chạy xong, bạn cần gộp kết quả lại thành:
{
"name": "VHTSoft",
"address": "TP. Hồ Chí Minh",
"phone": "0123456789"
}Reducer sẽ gom và hợp nhất những giá trị này thành một trạng thái chung.
Định nghĩa Reducer
Reducer là một hàm nhận vào nhiều trạng thái (dưới dạng danh sách) và trả về một trạng thái duy nhất.
def my_reducer(states: list[dict]) -> dict:
result = {}
for state in states:
result.update(state) # Gộp tất cả dict lại
return result
Cách sử dụng trong LangGraph
Khi bạn xây dựng graph với StateGraph, bạn có thể chỉ định reducer cho một node nhất định như sau:
from langgraph.graph import StateGraph
builder = StateGraph(dict)
# Các node song song được thêm ở đây...
# Thêm reducer cho node tổng hợp
builder.add_reducer("merge_node", my_reducer)
Ví dụ thực tế
1. Khai báo các node
def node_1(state): return {"name": "VHTSoft"}
def node_2(state): return {"address": "TP.Hồ Chí Minh"}
def node_3(state): return {"phone": "0123456789"}
2. Tạo graph
builder = StateGraph(dict)
builder.add_node("node_1", node_1)
builder.add_node("node_2", node_2)
builder.add_node("node_3", node_3)
builder.add_node("merge_node", lambda x: x) # Dummy node
# Thêm reducer
def my_reducer(states): # states là list các dict
result = {}
for s in states:
result.update(s)
return result
builder.add_reducer("merge_node", my_reducer)
# Chạy 3 node song song → gộp về merge_node
builder.add_edge("node_1", "merge_node")
builder.add_edge("node_2", "merge_node")
builder.add_edge("node_3", "merge_node")
builder.set_entry_point("node_1") # node_1 là điểm vào chính
graph = builder.compile()Các hàm hữu ích về Reducers trong LangGraph
1. Custom Logic trong Reducer
Bạn không bị giới hạn bởi việc chỉ dùng dict.update(). Bạn có thể áp dụng bất kỳ logic tùy chỉnh nào để gộp dữ liệu:
Ví dụ: Lọc trạng thái hợp lệ
def filtered_reducer(states: list[dict]) -> dict:
final_state = {}
for state in states:
# Bỏ qua những trạng thái thiếu dữ liệu cần thiết
if "score" in state and state["score"] >= 0.8:
final_state.update(state)
return final_state
Dùng khi:
-
Bạn chỉ muốn lấy kết quả “đủ tốt” từ các nhánh.
-
Bạn có các nhánh xử lý có thể bị lỗi, hoặc chất lượng không đồng đều.
Trong ví dụ này, ta sẽ có 3 nhánh song song trả về thông tin khác nhau cùng với một chỉ số độ tin cậy (score). Sau đó, ta sẽ dùng một reducer để chỉ giữ lại những kết quả có score >= 0.8.
Giả sử bạn có một graph với 3 agent xử lý một nhiệm vụ phân tích cảm xúc từ một đoạn văn. Mỗi agent trả về:
-
sentiment: happy/sad/neutral -
score: độ tin cậy (confidence score)
Bạn chỉ muốn giữ lại kết quả của các agent có độ tin cậy cao (score ≥ 0.8).
Bước 1: Tạo các node trả về kết quả
from langgraph.graph import StateGraph, END
from typing import TypedDict
class State(TypedDict):
sentiment: str
score: float
# Mỗi node trả về một kết quả khác nhau
def analyzer_1(state):
return {"sentiment": "happy", "score": 0.9}
def analyzer_2(state):
return {"sentiment": "sad", "score": 0.7} # Không đạt
def analyzer_3(state):
return {"sentiment": "neutral", "score": 0.85}
Bước 2: Tạo filtered_reducer
def filtered_reducer(states: list[dict]) -> dict:
for state in states:
if state.get("score", 0) >= 0.8:
return state # Trả về state đầu tiên đạt yêu cầu
return {"sentiment": "unknown", "score": 0.0}Bước 3: Dựng graph và chạy thử
graph = StateGraph(State)
graph.add_node("analyzer_1", analyzer_1)
graph.add_node("analyzer_2", analyzer_2)
graph.add_node("analyzer_3", analyzer_3)
graph.add_edge("analyzer_1", END)
graph.add_edge("analyzer_2", END)
graph.add_edge("analyzer_3", END)
graph.set_entry_point(["analyzer_1", "analyzer_2", "analyzer_3"])
graph.set_finish_point(END, filtered_reducer)
app = graph.compile()
result = app.invoke({})
print(result)Kết quả mong đợi:
{'sentiment': 'happy', 'score': 0.9}Vì analyzer_1 là node đầu tiên đạt yêu cầu score >= 0.8, nên nó được giữ lại. Các kết quả khác bị bỏ qua.
Biến thể nâng cao: Trả về danh sách tất cả các kết quả tốt
def filtered_reducer(states: list[dict]) -> dict:
good_results = [s for s in states if s.get("score", 0) >= 0.8]
return {"results": good_results}Kết quả:
{
'results': [
{'sentiment': 'happy', 'score': 0.9},
{'sentiment': 'neutral', 'score': 0.85}
]
}
2. Merging trạng thái phức tạp (nested)
Giả sử mỗi nhánh trả về trạng thái dạng lồng nhau (nested):
{
"agent": {
"name": "Alice",
"tasks": ["translate"]
}
}Bạn có thể merge có điều kiện, thậm chí hợp nhất danh sách:
def deep_merge_reducer(states: list[dict]) -> dict:
merged = {"agent": {"name": "", "tasks": []}}
for state in states:
agent = state.get("agent", {})
if "name" in agent:
merged["agent"]["name"] = agent["name"]
if "tasks" in agent:
merged["agent"]["tasks"] += agent["tasks"]
return mergedGiả sử bạn có một hệ thống thu thập thông tin sản phẩm từ nhiều nguồn. Mỗi node (agent) sẽ trả về thông tin chi tiết khác nhau về sản phẩm, như:
-
name -
price -
reviews
Mỗi thông tin nằm trong một cấu trúc nested dictionary:
{
"product": {
"name": ...,
"price": ...,
"reviews": [...],
}
}Chúng ta sẽ merge lại tất cả thành một state hoàn chỉnh.
1. Định nghĩa state phức tạp
from typing import TypedDict, Optional
from langgraph.graph import StateGraph, END
class ProductInfo(TypedDict, total=False):
name: Optional[str]
price: Optional[float]
reviews: list[str]
class State(TypedDict, total=False):
product: ProductInfo2. Các node thu thập thông tin khác nhau
def fetch_name(state):
return {
"product": {
"name": "Smartphone X"
}
}
def fetch_price(state):
return {
"product": {
"price": 799.99
}
}
def fetch_reviews(state):
return {
"product": {
"reviews": ["Good value", "Excellent battery", "Fast delivery"]
}
}3. Merge state phức tạp bằng custom reducer
LangGraph sẽ merge các dicts theo mặc định, nhưng với dict lồng nhau, bạn cần viết custom reducer.
def nested_merge_reducer(states: list[dict]) -> dict:
merged = {"product": {}}
for state in states:
product = state.get("product", {})
for key, value in product.items():
if key == "reviews":
merged["product"].setdefault("reviews", []).extend(value)
else:
merged["product"][key] = value
return merged4. Tạo Graph
graph = StateGraph(State)
graph.add_node("name", fetch_name)
graph.add_node("price", fetch_price)
graph.add_node("reviews", fetch_reviews)
graph.add_edge("name", END)
graph.add_edge("price", END)
graph.add_edge("reviews", END)
graph.set_entry_point(["name", "price", "reviews"])
graph.set_finish_point(END, nested_merge_reducer)
app = graph.compile()
result = app.invoke({})
print(result)
Kết quả mong đợi:
{
"product": {
"name": "Smartphone X",
"price": 799.99,
"reviews": [
"Good value",
"Excellent battery",
"Fast delivery"
]
}
}
Ghi chú:
-
Nếu bạn không viết
reducer, các dict lồng nhau sẽ bị ghi đè. -
nested_merge_reducergiúp kết hợp thông minh các phần tử trongproduct.
3. Giữ thứ tự hoặc gán vai trò
Trong một số trường hợp, bạn muốn biết được nhánh nào trả về cái gì, thay vì merge chung.
def role_based_reducer(states: list[dict]) -> dict:
return {
"summarizer_result": states[0]["output"],
"validator_result": states[1]["output"],
"rewriter_result": states[2]["output"],
}Ví Dụ
Bạn đang xây dựng một ứng dụng hội thoại với nhiều agent khác nhau tham gia đối thoại. Mỗi agent đóng một vai trò (ví dụ: Customer, Support, Bot), và bạn muốn giữ thứ tự lời thoại cùng với vai trò rõ ràng.
1. Định nghĩa State
from typing import TypedDict
from langgraph.graph import StateGraph, END
class Message(TypedDict):
role: str
content: str
class ChatState(TypedDict, total=False):
messages: list[Message]2. Các node đóng vai khác nhau
def customer_node(state):
return {
"messages": [
{"role": "customer", "content": "Tôi muốn kiểm tra đơn hàng của mình."}
]
}
def support_node(state):
return {
"messages": [
{"role": "support", "content": "Chào anh/chị, vui lòng cung cấp mã đơn hàng ạ."}
]
}
def bot_node(state):
return {
"messages": [
{"role": "bot", "content": "Tôi có thể hỗ trợ những câu hỏi thường gặp. Bạn muốn hỏi gì?"}
]
}
3. Custom reducer giữ thứ tự lời thoại
def ordered_reducer(states: list[dict]) -> dict:
all_messages = []
for state in states:
msgs = state.get("messages", [])
all_messages.extend(msgs)
return {"messages": all_messages}
Lưu ý: extend giúp nối danh sách lời thoại từ các node theo đúng thứ tự gọi.
4. Xây dựng LangGraph
graph = StateGraph(ChatState)
graph.add_node("customer", customer_node)
graph.add_node("support", support_node)
graph.add_node("bot", bot_node)
graph.add_edge("customer", "support")
graph.add_edge("support", "bot")
graph.add_edge("bot", END)
graph.set_entry_point("customer")
graph.set_finish_point(END, reducer=ordered_reducer)
app = graph.compile()
result = app.invoke({})
from pprint import pprint
pprint(result)
Kết quả mong đợi:
{
'messages': [
{'role': 'customer', 'content': 'Tôi muốn kiểm tra đơn hàng của mình.'},
{'role': 'support', 'content': 'Chào anh/chị, vui lòng cung cấp mã đơn hàng ạ.'},
{'role': 'bot', 'content': 'Tôi có thể hỗ trợ những câu hỏi thường gặp. Bạn muốn hỏi gì?'}
]
}
4. Gộp theo trọng số(Weighted merge )
Khi bạn có nhiều nguồn dữ liệu và muốn ưu tiên nguồn nào đó, bạn có thể merge có trọng số.
def weighted_merge_reducer(states: list[dict]) -> dict:
scores = [0.5, 0.3, 0.2] # trọng số cho từng nhánh
merged_output = ""
for state, score in zip(states, scores):
merged_output += f"{score:.1f} * {state['text']}\n"
return {"combined_output": merged_output}
Ví dụ
Giả sử có 3 agent khác nhau đề xuất một câu trả lời cho cùng một câu hỏi, nhưng mỗi agent có độ tin cậy khác nhau. Bạn muốn:
-
Gộp kết quả trả về của họ,
-
Nhưng kết quả nào đáng tin hơn thì nên ảnh hưởng nhiều hơn đến kết quả cuối cùng.
1. Khai báo State
from typing import TypedDict
class State(TypedDict, total=False):
suggestions: list[dict] # Mỗi đề xuất có 'text' và 'score'2. Tạo các node với "đề xuất" khác nhau
def agent_1(state):
return {"suggestions": [{"text": "Trả lời từ agent 1", "score": 0.8}]}
def agent_2(state):
return {"suggestions": [{"text": "Trả lời từ agent 2", "score": 0.6}]}
def agent_3(state):
return {"suggestions": [{"text": "Trả lời từ agent 3", "score": 0.9}]}3. Gộp theo trọng số(Weighted merge )
def weighted_merge(states: list[dict]) -> dict:
from collections import defaultdict
scores = defaultdict(float)
for state in states:
for suggestion in state.get("suggestions", []):
text = suggestion["text"]
score = suggestion.get("score", 1.0)
scores[text] += score # Cộng điểm nếu có trùng câu trả lời
# Chọn text có tổng điểm cao nhất
best_text = max(scores.items(), key=lambda x: x[1])[0]
return {"final_answer": best_text}defaultdict: xem chi tiết tại https://docs.vhterp.com/books/ky-thuat-lap-trinh-python/page/defaultdict
4. Xây dựng đồ thị
from langgraph.graph import StateGraph, END
graph = StateGraph(State)
graph.add_node("agent_1", agent_1)
graph.add_node("agent_2", agent_2)
graph.add_node("agent_3", agent_3)
graph.add_edge("agent_1", END)
graph.add_edge("agent_2", END)
graph.add_edge("agent_3", END)
graph.set_entry_point("agent_1")
graph.set_finish_point(END, reducer=weighted_merge)
app = graph.compile()
result = app.invoke({})
print(result)
Kết quả:
{'final_answer': 'Trả lời từ agent 3'}5. Reducers + Pydantic = An toàn tuyệt đối
Khi reducer trả về một dict, bạn có thể dùng Pydantic để đảm bảo kết quả hợp lệ và chặt chẽ:
from pydantic import BaseModel
class FinalState(BaseModel):
name: str
summary: str
mood: str
def reducer_with_validation(states):
merged = {}
for s in states:
merged.update(s)
return FinalState(**merged).dict()
Tình huống thực tế:
Giả sử bạn đang xây dựng một hệ thống trợ lý AI cho chăm sóc khách hàng. Bạn có nhiều "nhánh" (agents) cùng phân tích yêu cầu của người dùng để trích xuất thông tin: name, email, issue.
Mỗi agent có thể phát hiện một phần thông tin. Bạn muốn:
-
Gộp kết quả lại,
-
Và đảm bảo kết quả cuối cùng đúng định dạng, đầy đủ, an toàn.
1. Định nghĩa State với Pydantic
from pydantic import BaseModel, EmailStr
from typing import Optional
class UserRequest(BaseModel):
name: Optional[str]
email: Optional[EmailStr]
issue: Optional[str]
2. Tạo các Agent
def extract_name(state):
return {"name": "Nguyễn Văn A"}
def extract_email(state):
return {"email": "nguyenvana@example.com"}
def extract_issue(state):
return {"issue": "Không đăng nhập được vào tài khoản"}
3. Tạo Reducer sử dụng Pydantic để kiểm tra tính hợp lệ
def safe_merge(states: list[dict]) -> dict:
merged = {}
for state in states:
merged.update(state)
# Kiểm tra hợp lệ bằng Pydantic
validated = UserRequest(**merged)
return validated.dict()
4. Xây dựng Graph
from langgraph.graph import StateGraph, END
graph = StateGraph(UserRequest)
graph.add_node("name", extract_name)
graph.add_node("email", extract_email)
graph.add_node("issue", extract_issue)
# Cho các node chạy song song
graph.add_edge("name", END)
graph.add_edge("email", END)
graph.add_edge("issue", END)
graph.set_entry_point("name")
graph.set_finish_point(END, reducer=safe_merge)
app = graph.compile()
result = app.invoke({})
print(result)
Kết quả
{
'name': 'Nguyễn Văn A',
'email': 'nguyenvana@example.com',
'issue': 'Không đăng nhập được vào tài khoản'
}
6. Kết hợp với ToolCall
Nếu các nhánh là các công cụ (tools), bạn có thể dùng reducer để phân tích kết quả từ từng công cụ:
def tool_result_reducer(states):
results = {}
for state in states:
tool_name = state["tool"]
result = state["result"]
results[tool_name] = result
return {"tools_result": results}
Tình huống thực tế:
Bạn có một hệ thống AI assistant, khi người dùng hỏi:
"Tôi tên là Minh, email của tôi là minh@example.com, tôi cần hỗ trợ về hóa đơn."
Bạn dùng LLM để tách thông tin đó, nhưng thay vì chỉ tách thủ công, bạn dùng ToolCall để giao cho từng tool xử lý riêng một phần.
1. Định nghĩa Tool và State với Pydantic
from pydantic import BaseModel, EmailStr
from typing import Optional
from langchain_core.tools import tool
class UserInfo(BaseModel):
name: Optional[str]
email: Optional[EmailStr]
issue: Optional[str]
2. Định nghĩa các Tool dùng ToolCall
@tool
def extract_name_tool(text: str) -> dict:
if "tên là" in text:
return {"name": "Minh"}
return {}
@tool
def extract_email_tool(text: str) -> dict:
if "email" in text:
return {"email": "minh@example.com"}
return {}
@tool
def extract_issue_tool(text: str) -> dict:
return {"issue": "hỗ trợ về hóa đơn"}
3. Dùng LangGraph gọi các Tool + Gộp lại bằng Reducer
from langgraph.graph import StateGraph, END
from langgraph.graph.message import ToolMessage
from langgraph.prebuilt.tool_node import ToolNode
# Khởi tạo ToolNode
tool_node = ToolNode(tools=[extract_name_tool, extract_email_tool, extract_issue_tool])
# Reducer sử dụng Pydantic để validate kết quả
def merge_tool_results(states: list[dict]) -> dict:
merged = {}
for state in states:
merged.update(state)
return UserInfo(**merged).dict()
4. Tạo Graph
graph = StateGraph(UserInfo)
# Tạo một node để gọi tool dựa vào user input
def prepare_tool_call(state):
return ToolMessage(
tool_name="extract_name_tool", # Không cần quá cụ thể vì ToolNode sẽ tự chọn tool phù hợp
tool_input={"text": "Tôi tên là Minh, email của tôi là minh@example.com, tôi cần hỗ trợ về hóa đơn."}
)
graph.add_node("call_tool", prepare_tool_call)
graph.add_node("tool_node", tool_node)
graph.add_edge("call_tool", "tool_node")
graph.add_edge("tool_node", END)
graph.set_entry_point("call_tool")
graph.set_finish_point(END, reducer=merge_tool_results)
app = graph.compile()
result = app.invoke({})
print(result)
Kết quả
{
"name": "Minh",
"email": "minh@example.com",
"issue": "hỗ trợ về hóa đơn"
}
Lợi ích của việc dùng ToolCall:
| Tính năng | Lợi ích |
|---|---|
| Tách vai trò | Mỗi Tool xử lý một phần dữ liệu |
| Kết hợp logic | Dễ dàng mở rộng thêm Tool mà không phải viết lại toàn bộ |
| An toàn dữ liệu | Pydantic đảm bảo kết quả hợp lệ, đúng định dạng |
| Tự động | ToolNode sẽ chọn tool phù hợp dựa vào tên tool và input |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Public State, Private State và Multiple State Schemas trong LangGraph
Ví Dụ Minh Họa: Cửa Hàng Sửa Máy Tính
1. Public State - Giao Tiếp Đơn Giản Với Khách Hàng
-
Kịch bản: Bạn mang máy tính bị hỏng đến cửa hàng sửa chữa.
-
Cuộc trò chuyện:
-
Bạn: "Máy tính của tôi không hoạt động nữa, tôi không biết lý do."
-
Nhân viên: "Chúng tôi sẽ kiểm tra và báo lại cho bạn sau."
-
-
Đặc điểm:
-
Thông tin đơn giản, dễ hiểu.
-
Không đi vào chi tiết kỹ thuật.
-
→ Đây chính là public state trong Landgraaf: trạng thái mà người dùng cuối (khách hàng) tương tác trực tiếp.
2. Private State - Giao Tiếp Nội Bộ Kỹ Thuật
-
Kịch bản: Nhân viên chuyển máy tính cho đội kỹ thuật.
-
Cuộc trò chuyện:
-
Kỹ thuật viên 1: "Kiểm tra nguồn điện, có thể do adapter."
-
Kỹ thuật viên 2: "Test RAM và ổ cứng, có thể bị bad sector."
-
-
Đặc điểm:
-
Thông tin kỹ thuật phức tạp, chỉ dành cho nội bộ.
-
Khách hàng không cần biết chi tiết này.
-
→ Đây là private state: trạng thái nội bộ để xử lý logic phức tạp.
3. Kết Quả Cuối Cùng - Quay Lại Public State
-
Kỹ thuật viên tổng hợp kết quả và báo lại cho nhân viên:
-
"Máy bị lỗi ổ cứng, cần thay thế với chi phí 3 triệu đồng."
-
-
Nhân viên thông báo lại cho khách hàng:
-
"Máy của bạn bị hỏng ổ cứng, chúng tôi sẽ sửa trong 2 ngày."
-
→ Thông tin được đơn giản hóa từ private state trở lại public state.
Áp Dụng Vào LangGraph
1. Public State Schema
-
Vai trò: Giao diện tương tác với người dùng.
-
Đặc điểm:
-
Dữ liệu đầu vào/đầu ra đơn giản.
-
Ví dụ: Form đăng ký, kết quả tìm kiếm.
-
2. Private State Schema
-
Vai trò: Xử lý logic nghiệp vụ phức tạp.
-
Đặc điểm:
-
Chứa các biến và thuật toán kỹ thuật.
-
Ví dụ: Xử lý dữ liệu từ database, tính toán AI.
-
3. Chuyển Đổi Giữa Các Trạng Thái
-
Node 1 (Nhận Public State → Tạo Private State):
-
Nhận thông tin đơn giản từ người dùng.
-
"Tăng độ phức tạp lên 1000 lần" để xử lý nội bộ.
-
-
Node 2 (Nhận Private State → Trả Public State):
-
Tổng hợp kết quả phức tạp.
-
"Giảm độ phức tạp 999 lần" để trả về người dùng.
-
Tại Sao Điều Này Quan Trọng?
-
Bảo Mật: Private state giúp che giấu logic nhạy cảm khỏi người dùng.
-
Hiệu Suất: Tách biệt xử lý phức tạp khỏi giao diện người dùng.
-
Dễ Bảo Trì: Thay đổi logic kỹ thuật mà không ảnh hưởng đến trải nghiệm người dùng.
Lời Khuyên Khi Áp Dụng
-
Ghi nhớ khái niệm: Hiểu rõ sự khác biệt giữa public/private state.
-
Đừng sa lầy vào chi tiết ngay: Tập trung vào bài học thực hành trước.
-
Quay lại khi cần: Khi xây dựng ứng dụng phức tạp, hãy tra cứu lại tài liệu này.
"LandGraph không chỉ dành cho siêu anh hùng - nó đơn giản nếu bạn hiểu cách tổ chức trạng thái!"
Kết Luận
Việc phân chia public/private state giống như cách một cửa hàng sửa chữa hoạt động:
-
Public state = Giao tiếp với khách hàng.
-
Private state = Thảo luận nội bộ kỹ thuật.
Hiểu được điều này sẽ giúp bạn thiết kế ứng dụng LangGraph mạnh mẽ và dễ bảo trì!
Multiple State Schemas Qua Ví Dụ Cửa Hàng Sửa Máy Tính
1. Multiple State Schemas Là Gì?
Trong LangGraph, Multiple State Schemas (Đa lược đồ trạng thái) là cách phân chia trạng thái ứng dụng thành nhiều "lớp" khác nhau, mỗi lớp có:
-
Mục đích riêng (giao tiếp với người dùng vs xử lý nội bộ)
-
Độ phức tạp riêng (đơn giản vs kỹ thuật)
-
Phạm vi truy cập riêng (public vs private)
Giống như một cửa hàng có khu vực bán hàng (public) và xưởng sửa chữa (private).
2. Áp Dụng Vào Ví Dụ Cửa Hàng Sửa Máy Tính
Schema 1: Public State Schema
(Khu vực tiếp tân)
-
Đặc điểm:
-
Ngôn ngữ: Đơn giản, không chuyên môn
-
Dữ liệu: Chỉ thông tin cần thiết cho khách hàng
-
-
Ví dụ:
-
// Public State Schema { customerName: "Nguyễn Văn A", device: "Laptop Dell XPS", problem: "Không khởi động được", status: "Đang chẩn đoán" }
Schema 2: Private State Schema
(Xưởng kỹ thuật)
-
Đặc điểm:
-
Ngôn ngữ: Kỹ thuật, chi tiết
-
Dữ liệu: Đầy đủ thông tin để sửa chữa
-
-
Ví dụ:
-
// Private State Schema { deviceId: "DELL-XPS-2023-SN-12345", diagnosticLogs: [ { test: "Power Supply", result: "12V rail unstable" }, { test: "HDD S.M.A.R.T", result: "Reallocated sectors: 512" } ], repairPlan: [ { action: "Replace PSU", part: "PSU-DELL-120W" }, { action: "Clone HDD to SSD", tools: ["Acronis", "USB-SATA adapter"] } ] }
3. Cách Chuyển Đổi Giữa Các State Schema
Quy Trình Xử Lý
-
Public → Private (Node 1)
-
Nhận yêu cầu đơn giản từ khách
-
"Mở rộng" thành thông số kỹ thuật
-
def public_to_private(public_state): private_state = { 'deviceId': lookup_device_id(public_state['device']), 'diagnosticLogs': run_hardware_tests(), 'repairPlan': generate_repair_options() } return private_state
-
-
Private → Public (Node 2)
-
Tổng hợp kết quả kỹ thuật
-
"Rút gọn" thành thông báo dễ hiểu
-
def private_to_public(private_state): public_state_update = { 'status': "Đã xác định lỗi", 'solution': f"Thay {private_state['repairPlan'][0]['part']}", 'cost': calculate_cost(private_state) } return public_state_update
-
4. Lợi Ích Của Multiple State Schemas
| Tiêu Chí | Public State | Private State |
|---|---|---|
| Đối tượng | Khách hàng | Kỹ thuật viên |
| Độ phức tạp | 1x (dễ hiểu) | 1000x (chi tiết) |
| Bảo mật | Ai cũng thấy | Nội bộ |
| Ví dụ thực tế | App Mobile | Database + Microservices |
Ưu điểm:
-
Giảm tải thông tin cho người dùng cuối
-
Dễ dàng thay đổi logic nghiệp vụ mà không ảnh hưởng giao diện
-
Bảo mật thông tin nhạy cảm (giá vốn, lỗi hệ thống...)
5. Sai Lầm Cần Tránh
-
Nhồi nhét private state vào public
→ Làm người dùng bối rối với thông báo kiểu:
"Lỗi 0x7F do sector 512 bị bad, cần remap cluster" -
Thiếu chuyển đổi giữa các schema
→ Dẫn đến mất mát thông tin khi giao tiếp giữa các thành phần -
Dùng chung schema cho mục đích khác nhau
→ Như bắt kỹ thuật viên dùng form đơn giản của khách để ghi chép
Câu Hỏi Thực Hành
Hãy thử thiết kế Multiple State Schemas cho các tình huống sau:
-
Ứng dụng ngân hàng
-
Public: Số dư tài khoản
-
Private: Lịch sử giao dịch chi tiết + thuật toán chống gian lận
-
-
Trợ lý ảo y tế
-
Public: Triệu chứng đơn giản ("Đau đầu 3 ngày")
-
Private: Dữ liệu EHR + mô hình chẩn đoán AI
-
💡 Mẹo: Luôn tự hỏi "Thông tin này có CẦN THIẾT cho người dùng cuối không?" khi thiết kế schema.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thực hành Public State and Private State
1. Cài Đặt LangGraph
pip install langgraph2. Triển Khai Code
from langgraph.graph import Graph
from typing import Dict, Any
# ======================================
# ĐỊNH NGHĨA SCHEMAS
# ======================================
# Public State Schema (Dành cho khách hàng)
PublicState = Dict[str, Any] # Ví dụ: {'customer_name': 'John', 'problem': 'Không khởi động'}
# Private State Schema (Dành cho kỹ thuật viên)
PrivateState = Dict[str, Any] # Ví dụ: {'diagnostics': ['lỗi ổ cứng', 'pin hỏng'], 'repair_cost': 200}
# ======================================
# ĐỊNH NGHĨA CÁC NODE
# ======================================
def receive_complaint(state: PublicState) -> Dict[str, Any]:
"""Node 1: Tiếp nhận yêu cầu từ khách hàng (Public State)"""
print(f"🎤 Nhân viên nhận máy từ khách hàng: {state['customer_name']}")
print(f"🔧 Vấn đề mô tả: {state['problem']}")
return {"internal_note": f"Khách hàng {state['customer_name']} báo: {state['problem']}"}
def diagnose_problem(state: Dict[str, Any]) -> PrivateState:
"""Node 2: Chuyển sang Private State để chẩn đoán"""
print("\n🔎 Kỹ thuật viên đang kiểm tra...")
diagnostics = [
"Test nguồn: OK",
"Ổ cứng bị bad sector (LBA 1024-2048)",
"Mainboard lỗi khe RAM"
]
return {
'diagnostics': diagnostics,
'repair_cost': 350,
'technician_notes': "Cần thay ổ cứng SSD 256GB + vệ sinh khe RAM"
}
def summarize_report(state: PrivateState) -> PublicState:
"""Node 3: Chuyển kết quả về Public State cho khách hàng"""
print("\n📝 Tổng hợp báo cáo đơn giản...")
return {
'customer_name': state['internal_note'].split()[2], # Lấy tên từ internal_note
'solution': "Thay ổ cứng SSD + bảo dưỡng",
'cost': f"${state['repair_cost']}",
'time_estimate': "2 ngày"
}
# ======================================
# XÂY DỰNG GRAPH
# ======================================
workflow = Graph()
# Thêm các node vào graph
workflow.add_node("receive_complaint", receive_complaint)
workflow.add_node("diagnose_problem", diagnose_problem)
workflow.add_node("summarize_report", summarize_report)
# Kết nối các node
workflow.add_edge("receive_complaint", "diagnose_problem")
workflow.add_edge("diagnose_problem", "summarize_report")
# Biên dịch graph
chain = workflow.compile()
# ======================================
# CHẠY VÍ DỤ
# ======================================
# Khởi tạo Public State ban đầu
initial_state = {
'customer_name': 'Nguyễn Văn A',
'problem': 'Máy tính không lên nguồn',
'status': 'received'
}
# Thực thi workflow
final_state = chain.invoke(initial_state)
# ======================================
# KẾT QUẢ
# ======================================
print("\n📢 Kết quả cuối cùng (Public State):")
print(final_state)3. Giải Thích Hoạt Động
Luồng Dữ Liệu

Kết Quả Khi Chạy
🎤 Nhân viên nhận máy từ khách hàng: Nguyễn Văn A
🔧 Vấn đề mô tả: Máy tính không lên nguồn
🔎 Kỹ thuật viên đang kiểm tra...
📝 Tổng hợp báo cáo đơn giản...
📢 Kết quả cuối cùng (Public State):
{
'customer_name': 'Nguyễn',
'solution': 'Thay ổ cứng SSD + bảo dưỡng',
'cost': '$350',
'time_estimate': '2 ngày'
}4. Ghi nhớ
-
Public State → Private State
-
Node 1 nhận thông tin đơn giản, Node 2 mở rộng thành dữ liệu kỹ thuật.
-
-
Private State → Public State
-
Node 3 lọc bỏ chi tiết không cần thiết, chỉ giữ lại thông tin khách hàng cần biết.
-
-
Ưu Điểm LangGraph
-
Dễ dàng mở rộng thêm node (vd: thêm node "Xác nhận thanh toán")
-
Tách biệt rõ ràng giữa các tầng logic.
-
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Hiệu quả bộ nhớ và khả năng lưu trữ bộ nhớ trong Agent LangGraph
Trong quá trình xây dựng tác nhân AI với LangGraph, việc quản lý bộ nhớ hiệu quả và duy trì bộ nhớ lâu dài là hai yếu tố then chốt để đảm bảo ứng dụng vừa tiết kiệm chi phí vừa vận hành ổn định. Hiệu quả bộ nhớ giúp giảm lượng token tiêu thụ, tối ưu tốc độ phản hồi và chi phí sử dụng mô hình AI. Trong khi đó, khả năng lưu trữ bộ nhớ lâu dài (memory persistence) cho phép tác nhân ghi nhớ thông tin quan trọng giữa các phiên làm việc, tạo ra trải nghiệm thông minh và cá nhân hóa hơn cho người dùng. Bài viết này sẽ giới thiệu những kỹ thuật cơ bản và những lưu ý cần thiết khi triển khai hai yếu tố quan trọng này trong LangGraph.
Giới thiệu
Trong phần này, chúng ta sẽ khám phá ba kỹ thuật rất thú vị.
Tuy nhiên, điều quan trọng nhất tôi muốn bạn ghi nhớ: Đừng để mình bị phân tâm.
Mục tiêu của tôi là bạn nắm chắc ý tưởng và khái niệm cốt lõi đằng sau mỗi kỹ thuật hoặc bài học này. Bạn không cần dành quá nhiều thời gian thực hành hoặc áp dụng ngay lập tức, bởi vì:
-
Những kỹ thuật này sẽ rất hữu ích khi bạn bắt đầu xây dựng ứng dụng thực tế nghiêm túc.
-
Khi đó, bạn sẽ nhớ rằng: "À, trước đây mình đã học về những kỹ thuật này", và đó chính là thời điểm thích hợp để bắt đầu thử nghiệm và ứng dụng.
Đây cũng là một lời khuyên quan trọng mà bạn có thể áp dụng nhiều lần khi học hoặc nghiên cứu tài liệu kỹ thuật — ví dụ như tài liệu của LangGraph.
Cẩn Thận Với Những "Sự Phân Tâm" Khi Học Tài Liệu LangGraph
Khi bạn đọc tài liệu của LangGraph, sẽ có rất nhiều kỹ thuật nhỏ, thủ thuật đặc biệt hiện ra và thu hút sự chú ý.
Nếu không cẩn thận, bạn có thể dễ dàng:
-
Bị cuốn vào các chi tiết kỹ thuật phụ
-
Mất động lực học các phần quan trọng hơn
-
Chán nản và bỏ dở quá trình học
Điều quan trọng là:
- Hãy ghi nhận sự tồn tại của các kỹ thuật đó, hiểu sơ qua, nhưng đừng để chúng làm bạn chệch hướng.
- Tiếp tục tập trung vào mục tiêu lớn: học cách xây dựng ứng dụng mạnh mẽ, thú vị và ấn tượng với LangGraph.
Nội dung bạn sẽ học ở phần này
Chúng ta sẽ tìm hiểu những kỹ thuật liên quan đến quản lý bộ nhớ trong ứng dụng LangGraph, cụ thể:
1. Tối ưu hóa chi phí sử dụng LLM
Bạn sẽ học một vài phương pháp để:
-
Giảm lượng token tiêu tốn trong các lần gọi LLM
-
Giúp ứng dụng hoạt động hiệu quả hơn và kinh tế hơn.
2. Giới thiệu về bộ nhớ dài hạn (Long-term Memory)
Chúng ta sẽ bắt đầu thảo luận về cách:
-
Lưu trữ bộ nhớ (memory) của ứng dụng vào các cơ sở dữ liệu bên ngoài
-
Ghi nhớ lâu dài những thông tin quan trọng thay vì chỉ lưu trong phiên làm việc ngắn hạn.
Một lời nhắc quan trọng
Như tôi đã nhấn mạnh:
-
Đây là những bài học rất thú vị và hữu ích.
-
Nhưng, xin bạn không dành quá nhiều thời gian thực hành lúc này.
-
Hiểu khái niệm, nắm bắt nguyên lý, và tiếp tục tiến lên.
-
Khi bắt tay vào xây dựng những ứng dụng thực sự, bạn sẽ có dịp quay lại và khai thác những kỹ thuật này đúng thời điểm.
Hãy nhớ rằng: việc xây dựng một ứng dụng mạnh mẽ, thú vị và chuyên nghiệp đòi hỏi bạn phải biết chọn lọc thông tin để tập trung.
Đừng để những chi tiết phụ đánh lạc hướng bạn khỏi mục tiêu lớn hơn!
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tối Ưu Chi Phí và Quản Lý Bộ Nhớ Khi Xây Dựng Ứng Dụng AI Với OpenAI
Nếu bạn từng đọc các chương trước của chúng tôi, bạn sẽ biết rằng việc thực hành các bài tập sử dụng OpenAI API không hề tốn kém.
Thông thường, bạn chỉ tốn khoảng 5 đô la cho toàn bộ bootcamp trước, và con số này sẽ tương tự trong bootcamp này.
Tại sao chi phí lại thấp?
Vì chúng ta đang xây dựng các ứng dụng nhỏ gọn, số lượng người dùng hạn chế, tiêu thụ tài nguyên và token ở mức tối thiểu.
Tuy nhiên, khi bạn chuyển sang giai đoạn sản xuất thực tế với nhiều người dùng và ứng dụng lớn, chi phí có thể tăng đáng kể.
Bài học hôm nay sẽ giúp bạn:
-
Hiểu vì sao phải kiểm soát chi phí khi xây dựng AI agent.
-
Biết cách quản lý bộ nhớ ngắn hạn (short-term memory) để tiết kiệm token.
-
Học hai kỹ thuật chính giúp giảm chi phí vận hành chatbot.
Chi Phí Và Bộ Nhớ Trong Ứng Dụng AI
Khi vận hành AI agent:
-
Chi phí thường gắn liền với quản lý bộ nhớ.
-
Bộ nhớ càng lớn → Tốn nhiều token hơn → Chi phí cao hơn.
Ví dụ:
-
Nếu cuộc hội thoại có 100 tin nhắn, mỗi lần bạn gửi yêu cầu mới, bạn cũng phải gửi lại cả 100 tin nhắn trước đó.
-
Điều này giống như việc bạn đeo một ba lô đầy tin nhắn trong suốt cuộc trò chuyện.
Ba lô càng nặng → Chi phí càng cao.
OpenAI hay Open-Source?
Bạn có thể tự hỏi:
-
"Tại sao không dùng mô hình mã nguồn mở để giảm chi phí?"
Bạn có thể làm vậy, đặc biệt ở giai đoạn thử nghiệm (beta, demo).
❌ Nhưng khi làm việc ở cấp độ chuyên nghiệp, OpenAI vẫn đang là tiêu chuẩn hiện tại (~99% doanh nghiệp dùng OpenAI).
Vì vậy, chúng tôi khuyên bạn nên thành thạo với OpenAI models.
Làm Thế Nào Để Giảm Chi Phí Bộ Nhớ?
Chúng ta sẽ học 2 kỹ thuật chính để giảm dung lượng "ba lô" của chatbot:
Kỹ thuật 1: Giới hạn số lượng tin nhắn lưu trong bộ nhớ
-
Thay vì lưu toàn bộ cuộc hội thoại, chỉ lưu khoảng 10 tin nhắn gần nhất.
-
Ví dụ:
-
Cuộc trò chuyện có 100 tin nhắn.
-
Chỉ lưu 10 tin nhắn mới nhất để gửi kèm với mỗi câu hỏi mới.
-
Ưu điểm: Giảm mạnh chi phí token.
Nhược điểm: Độ chính xác của chatbot có thể giảm nhẹ.
Kỹ thuật 2: Sử dụng bản tóm tắt thay cho toàn bộ tin nhắn
(Sẽ được học ở bài tiếp theo)
-
Tóm tắt cuộc hội thoại thành 1 đoạn văn ngắn.
-
Gửi đoạn tóm tắt thay vì gửi toàn bộ nội dung tin nhắn.
Ưu điểm: Bộ nhớ cực nhẹ, tiết kiệm chi phí.
Nhược điểm: Chatbot có thể không nhớ chi tiết đầy đủ.
Cách Thực Hiện Kỹ Thuật 1 Trong Thực Tế
Trong bài tập hôm nay, bạn sẽ thực hành:
-
Tạo một danh sách mô phỏng các tin nhắn trước đó.
# Giả lập bộ nhớ tin nhắn messages = [ {"role": "user", "content": "Xin chào!"}, {"role": "assistant", "content": "Chào bạn! Tôi có thể giúp gì?"}, {"role": "user", "content": "Bạn có thể giải thích LangGraph không?"}, {"role": "assistant", "content": "LangGraph là một framework xây dựng AI workflows."}, {"role": "user", "content": "Làm sao để quản lý bộ nhớ trong LangGraph?"} ] -
Dùng Python function để xóa tất cả tin nhắn cũ, chỉ giữ lại 2 tin nhắn mới nhất trong bộ nhớ.
def keep_last_two_messages(messages): """ Hàm xóa tin nhắn cũ, chỉ giữ lại 2 tin nhắn mới nhất. """ return messages[-2:] # Cắt danh sách, lấy 2 phần tử cuối -
Khi gửi yêu cầu tới ChatGPT, chỉ kèm 2 tin nhắn cuối cùng.
import openai # Cập nhật danh sách tin nhắn, chỉ giữ lại 2 tin mới nhất messages_to_send = keep_last_two_messages(messages) # Gửi request tới ChatGPT response = openai.ChatCompletion.create( model="gpt-4", messages=messages_to_send ) print(response['choices'][0]['message']['content'])
Kết quả:
Bộ nhớ (backpack) nhẹ hơn → Chi phí token thấp hơn.
Lưu Ý Khi Áp Dụng
-
Những kỹ thuật giảm bộ nhớ này rất hữu ích ở giai đoạn:
-
Thử nghiệm (beta).
-
Demo với khách hàng.
-
-
Khi vào sản xuất thực tế (production), bạn cần cân nhắc kỹ giữa:
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tối ưu hóa bộ nhớ ngắn hạn bằng cách tóm tắt hội thoại
Trong bài học trước, bạn đã học cách giảm số lượng tin nhắn trong bộ nhớ ngắn hạn để tiết kiệm token khi làm việc với mô hình ngôn ngữ.
Trong bài học này, chúng ta sẽ tìm hiểu một phương pháp thay thế: Tạo bản tóm tắt hội thoại thay vì lưu toàn bộ danh sách tin nhắn.
Tóm tắt hội thoại: Ý tưởng chính
-
Thay vì lưu trữ toàn bộ tin nhắn, chúng ta sẽ tóm tắt nội dung cuộc trò chuyện.
-
Bộ nhớ ngắn hạn ("ba lô" mà chatbot mang theo) sẽ chỉ chứa bản tóm tắt, thay vì toàn bộ các tin nhắn.
Ưu điểm:
-
Bản tóm tắt nhỏ gọn hơn nhiều so với danh sách tất cả các tin nhắn → tiết kiệm token.
Nhược điểm:
-
Mức độ chính xác của phản hồi sẽ giảm nhẹ, vì thông tin chi tiết có thể bị mất trong quá trình tóm tắt.
Khi nào nên dùng tóm tắt hội thoại?
-
Giai đoạn phát triển / demo / beta: Ưu tiên tiết kiệm chi phí và token → Dùng tóm tắt.
-
Giai đoạn sản phẩm chính thức (production): Ưu tiên hiệu suất và độ chính xác → Có thể dùng toàn bộ tin nhắn.
Ghi nhớ:
Hiệu suất và chi phí luôn cần cân bằng tùy vào mục tiêu dự án của bạn.
Cách triển khai
a. Cấu trúc State mới
Trong state của ứng dụng, ngoài khóa mặc định messages, bạn sẽ thêm một khóa mới:
state = {
"messages": [...],
"summary": "..."
}
-
messages: Lưu danh sách tin nhắn. -
summary: Lưu bản tóm tắt nội dung cuộc trò chuyện.
b. Logic hoạt động
-
Bắt đầu cuộc trò chuyện như bình thường.
-
Khi số lượng tin nhắn trong bộ nhớ vượt quá ngưỡng (ví dụ: 6 tin nhắn), tạo hoặc cập nhật bản tóm tắt.
-
Nếu chưa vượt ngưỡng, tiếp tục hội thoại bình thường.
Điều kiện:
Nếu len(messages) > 6 → tạo / cập nhật bản tóm tắt.
c. Các thành phần cần lập trình
-
Conditional Edge: Kiểm tra số lượng tin nhắn để quyết định có cần tóm tắt hay không.
-
Function để tóm tắt hội thoại: Lấy danh sách tin nhắn, tạo ra một bản tóm tắt.
-
Function gửi yêu cầu tới ChatGPT:
-
Nếu đã có
summary→ dùng tóm tắt làm context. -
Nếu chưa có
summary→ dùng danh sách tin nhắn.
-
Lưu ý khi thực thi
-
Mỗi hội thoại / user / session phải gắn với một thread ID riêng.
-
Khi gửi request, bạn cần truyền
thread_idđể phân biệt từng cuộc trò chuyện khác nhau.
Tổng kết
-
Đây là cách thứ hai để giảm lượng token tiêu thụ.
-
Khác với cách giảm số lượng tin nhắn, ở đây ta chuyển đổi toàn bộ nội dung thành một bản tóm tắt.
-
Bạn có thể quay lại tài liệu chi tiết và ví dụ khi cần áp dụng kỹ thuật này vào những ứng dụng thực tế.
Ghi nhớ
"Hiệu suất vs Chi phí luôn cần cân bằng. Hiểu kỹ các kỹ thuật ngay từ giai đoạn phát triển sẽ giúp bạn xây dựng các ứng dụng AI tối ưu và chuyên nghiệp hơn."
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Giới thiệu về Bộ nhớ Ngoài (Persistent Memory) với LangGraph
-
Trong chương trình đến hiện tại, chúng ta mới chỉ làm việc với bộ nhớ ngắn hạn (short-term memory).
-
Ứng dụng có thể ghi nhớ cuộc hội thoại đang diễn ra, nhưng khi đóng ứng dụng và mở lại, mọi thông tin sẽ mất.
-
Hôm nay, chúng ta sẽ khám phá một khái niệm mới: Bộ nhớ dài hạn (Long-Term Memory) hay còn gọi là Bộ nhớ ngoài (Persistent Memory).
Tầm quan trọng của Bộ nhớ Ngoài
-
Bộ nhớ ngoài giúp ứng dụng AI:
-
Ghi nhớ người dùng qua nhiều phiên làm việc.
-
Lưu trữ sở thích, dữ liệu, lịch sử người dùng.
-
-
Đây là một bước tiến rất quan trọng trong việc xây dựng các ứng dụng AI thông minh hơn.
⚡️ Ghi nhớ: Hôm nay chỉ là giới thiệu ban đầu, chi tiết sâu hơn sẽ học trong các bài học tới.
Mục tiêu bài học
Bạn sẽ học cách:
-
Tạo một ứng dụng AI có bộ nhớ ngoài.
-
Lưu trữ bộ nhớ trong một cơ sở dữ liệu SQLite thay vì chỉ lưu trong RAM.
Các bước thực hiện
1. Cài đặt SQLite
-
Xác nhận đã cài đặt SQLite 3 trên máy.
-
Nếu chưa có, làm theo hướng dẫn để cài đặt.
2. Tạo cơ sở dữ liệu bên ngoài
-
Dùng lệnh terminal trong notebook (bằng
!) để:-
Tạo thư mục
state_db/. -
Tạo cơ sở dữ liệu
external_memory.dbtrong thư mục này.
-
Lưu ý: Dấu ! trong notebook có nghĩa là chạy lệnh Terminal ngay trong notebook.
3. Kết nối với cơ sở dữ liệu
-
Sử dụng đối tượng connection (
conn) để kết nối tới database. -
Đường dẫn tới database sẽ là:
state_db/external_memory.db.
4. Thiết lập LangGraph với SQLite
-
Trước đây ta dùng
MemorySavercho bộ nhớ ngắn hạn. -
Giờ ta sử dụng SQLiteSaver để:
-
Ghi nhớ cuộc hội thoại.
-
Lưu vào cơ sở dữ liệu ngoài (external memory).
from langgraph.checkpoints.sqlite import SQLiteSaver checkpoint = SQLiteSaver(conn=conn)checkpointsẽ lưu giữ bộ nhớ trong file SQLite đã tạo.
-
Ứng dụng thực tế
-
Ứng dụng chatbot trước đây sẽ được chỉnh sửa:
-
Không lưu tạm trên RAM nữa.
-
Mà lưu luôn trên cơ sở dữ liệu.
-
-
Nếu bạn tắt và mở lại notebook, chatbot vẫn nhớ cuộc trò chuyện trước đó!
Ghi chú quan trọng
-
KHÔNG cần luyện tập sâu với bài này ngay bây giờ.
-
Ghi nhớ ý tưởng: ứng dụng có thể lưu bộ nhớ vào database.
-
Khi xây dựng ứng dụng nâng cao sau này, bạn sẽ cần dùng kỹ thuật này nhiều hơn.
Tổng kết nhanh
-
Bộ nhớ ngoài = Lưu trữ cuộc trò chuyện lâu dài.
-
SQLite = Công cụ lưu trữ dữ liệu nhẹ, dễ dùng.
-
LangGraph = Cung cấp module
SQLiteSaverđể kết nối và lưu dữ liệu dễ dàng.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tóm tắt chương
Hãy nhớ những gì tôi đã nói trong tài liệu về LangGraph, bạn sẽ gặp rất nhiều thứ mà chúng ta có thể gọi là "cạm bẫy".
Những cạm bẫy cần tránh khi học LangGraph
Chúng tôi gọi chúng là cạm bẫy vì chúng thực sự là những yếu tố gây xao nhãng lớn. Mục tiêu của bạn khi học LangGraph là để tạo ra những agent AI ấn tượng, mạnh mẽ và thú vị. Tuy nhiên, khi đọc tài liệu LangGraph, bạn sẽ gặp rất nhiều yếu tố gây xao nhãng trước khi đạt được mục tiêu đó.
Theo chúng tôi, điều này có thể gây bất lợi vì:
-
Nếu dành quá nhiều thời gian cho những yếu tố phụ này, động lực học tập của bạn có thể giảm sút
-
Bạn sẽ chỉ tập trung vào những thứ thứ yếu thay vì xây dựng ứng dụng thực tế
-
Bạn không có cơ hội hoàn thiện ứng dụng bằng các kỹ thuật nâng cao
Lời khuyên học tập hiệu quả
Khi tiếp cận tài liệu LangGraph, bạn sẽ gặp rất nhiều cạm bẫy như vậy. Do đó, lời khuyên của chúng tôi là:
-
Đừng để bị xao nhãng
-
Nắm vững các khái niệm chính trước
-
Có thể quay lại nghiên cứu sâu các kỹ thuật sau khi đã xây dựng ứng dụng cơ bản
Ví dụ: Khi làm ứng dụng nâng cao, bạn có thể:
-
Áp dụng kỹ thuật tiết kiệm chi phí đã học
-
Sử dụng bộ nhớ ngoài với database
-
Tối ưu hóa hệ thống
Các kỹ thuật đã học
-
3 kỹ thuật đơn giản giảm token usage:
-
Giảm số message lưu trong bộ nhớ ngắn hạn
-
Giảm số token sử dụng
-
Sử dụng các hàm reducer trong Python
-
-
Phương pháp thay thế:
-
Lưu bản tóm tắt conversation thay vì toàn bộ message
-
Có thể đặt điều kiện (vd: tạo summary khi có >6 messages)
-
-
Bộ nhớ ngoài/lâu dài:
-
Ví dụ đơn giản với SQLite database
-
Các kỹ thuật persistent memory
-
Lưu ý quan trọng: Đừng dừng lại quá lâu ở các kỹ thuật này! Hãy tiếp tục tiến lên và chỉ quay lại khi bạn thực sự cần áp dụng chúng để cải thiện ứng dụng cụ thể.
Chủ đề quan trọng sắp tới: Human-in-the-loop
Trong phần tiếp theo, chúng ta sẽ học về khái niệm cực kỳ quan trọng trong LangGraph: Human-in-the-loop. Bạn sẽ thấy:
-
Agent AI và ứng dụng LLM có thể cải thiện vượt bậc nhờ feedback từ người dùng
-
Trong nhiều trường hợp, ứng dụng có thể tự học mà không cần bạn can thiệp nhiều
-
Đây là bước tiến quan trọng trong quá trình học tập
Lời nhắc: Hãy tập trung cao độ cho phần tiếp theo này vì nó sẽ thực sự nâng tầm khả năng phát triển agent AI của bạn!LangGraph thực sự là framework mạnh mẽ nhưng để học hiệu quả, bạn cần:
-
Xác định rõ mục tiêu (build agent cụ thể nào)
-
Học theo cách "top-down": dùng trước, tối ưu sau
-
Đừng sa đà vào micro-optimization quá sớm
-
Tập trung vào các pattern quan trọng: agent collaboration, human feedback, memory management
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Phản hồi từ người dùng(Human Feedback)
Human Feedback, giúp bạn cải thiện agent theo thời gian, học từ hành vi và đánh giá của con người.
Giới thiệu
Phần này chúng ta sẽ học những khái niệm cực kỳ quan trọng, nhưng xin lưu ý ngay từ đầu:
Lời khuyên học tập quan trọng
⚠️ Đây vẫn là phần kiến thức nền tảng trước khi xây dựng ứng dụng hoàn chỉnh. Tôi khuyên bạn không nên dành quá nhiều thời gian thực hành các bài tập trong phần này ngay lúc này, vì:
-
Dễ bị xao nhãng khỏi mục tiêu chính
-
Hiện tại quan trọng nhất là nắm vững khái niệm cốt lõi
-
Các kỹ thuật này sẽ trở nên thực sự hữu ích khi bạn bắt đầu phát triển agent AI hoàn chỉnh với LangGraph
Khi đó bạn sẽ tự nhiên cảm thấy:
-
Mong muốn áp dụng các kỹ thuật này
-
Hứng thú thử nghiệm để cải thiện agent của mình
-
Hiểu sâu hơn về cách vận hành thực tế
Vấn đề phổ biến khi học framework mới
Hầu hết tài liệu kỹ thuật (bao gồm cả LangGraph) đều chứa đầy "cạm bẫy" khiến bạn:
-
Dễ bị phân tâm
-
Bối rối không biết bắt đầu từ đâu
-
Nhanh chán nản và bỏ cuộc
Khác biệt của cách tiếp cận này:
-
Đơn giản hóa tài liệu gốc
-
Định hướng lộ trình học đúng đắn
-
Tập trung vào ứng dụng thực tế thay vì lý thuyết suông
2 điểm trọng tâm của phần này
1. Chuyển từ .invoke() sang .stream()
-
Giống như trong khóa học về LangChain trước đây
-
Bước chuyển đổi này mở ra rất nhiều khả năng mới
-
Là một trong những điểm quan trọng nhất của phần này
Ví dụ so sánh:
# Cách cũ
result = agent.invoke({"input": "Hello"})
# Cách mới
for chunk in agent.stream({"input": "Hello"}):
# Xử lý từng phần
print(chunk)
2. Xử lý stream data cho Human-in-the-loop
Bí mật lớn: Ứng dụng AI hiện nay vẫn chưa thực sự "thông minh" hoàn toàn. Chúng cần con người để đạt hiệu suất tối đa (thường tăng thêm 5-20% chất lượng).
3 hướng tác động chính của Human-in-the-loop:
-
Phê duyệt/ từ chối các bước tiếp theo của ứng dụng
-
Điều chỉnh trạng thái hệ thống
-
Gỡ lỗi ứng dụng trong thời gian thực
Ví dụ thực tế:
for chunk in agent.stream(conversation):
if needs_human_review(chunk):
human_feedback = get_human_input()
agent.adjust_based_on_feedback(human_feedback)
Bổ sung quan trọng từ tôi
LangGraph thực sự tỏa sáng khi kết hợp:
-
Khả năng xử lý luồng dữ liệu (.stream())
-
Cơ chế phản hồi của con người
-
Kiến trúc có trạng thái (stateful)
Lời khuyên:
-
Tập trung hiểu cơ chế stream
-
Ghi chú các trường hợp cần human feedback
-
Đừng sa đà vào tối ưu hóa chi tiết
-
Chuẩn bị tinh thần cho phần human-in-the-loop sắp tới
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Streaming và Human-in-the-loop trong LangGraph
Streaming = "Truyền liên tục", nghĩa là agent hoặc LLM sẽ trả về kết quả dần dần, theo dòng, chứ không phải chờ tính toán xong mới gửi hết.
-
Streaming Values: bạn nhận kết quả từng bước nhỏ (thường là dạng text hoặc dữ liệu).
-
Streaming Update: bạn vừa nhận được giá trị ban đầu, vừa có thể nhận bản cập nhật mới hơn về sau (khi tác vụ tiến triển).
| Thuật ngữ | Ý nghĩa | Ví dụ thực tế |
|---|---|---|
| Streaming Values | Nhận các giá trị từng phần | Từng đoạn text của câu trả lời |
| Streaming Updates | Các bản cập nhật của 1 giá trị ban đầu | Đang xử lý... Đã hoàn thành |
Ví dụ đơn giản:
Giả sử bạn có một AI Agent thực hiện tóm tắt 1 tài liệu lớn.
-
Ban đầu, nó đọc tài liệu và trả về "Đang đọc chương 1..." (streaming value)
-
Khi đọc thêm, nó cập nhật thành "Đã đọc chương 1, đang đọc chương 2..." (streaming update)
Bạn nhận được dòng text đầu tiên nhanh chóng, sau đó nhiều bản cập nhật liên tiếp.
Ví dụ cụ thể bằng Python (giả lập):
import time
# Streaming giá trị ban đầu
def stream_value():
print("📥 Loading document...")
time.sleep(1)
yield "✅ Step 1: Read Chapter 1"
time.sleep(2)
yield "✅ Step 2: Read Chapter 2"
time.sleep(1)
yield "✅ Step 3: Summarizing Chapters"
# Xử lý streaming
for value in stream_value():
print(f"📡 Received update: {value}")
Kết quả
Loading document...
Received update: ✅ Step 1: Read Chapter 1
Received update: ✅ Step 2: Read Chapter 2
Received update: ✅ Step 3: Summarizing ChaptersVí dụ đơn giản về cách streaming câu trả lời trong chatbot
Tình huống:
Người dùng hỏi: "Tóm tắt tác phẩm Dế Mèn Phiêu Lưu Ký"
Ta sẽ cho chatbot trả lời dần dần (streaming) theo từng câu hoặc từng đoạn văn bản.
Ví dụ Python (giả lập):
import time
def chatbot_streaming_response():
yield "Dế Mèn Phiêu Lưu Ký là tác phẩm nổi tiếng của nhà văn Tô Hoài."
time.sleep(1)
yield "Tác phẩm kể về hành trình phiêu lưu của chú dế Mèn thông minh, gan dạ và thích khám phá."
time.sleep(1)
yield "Trong hành trình đó, dế Mèn đã học được nhiều bài học quý giá về tình bạn, lòng dũng cảm và sự trưởng thành."
time.sleep(1)
yield "Tác phẩm không chỉ hấp dẫn thiếu nhi mà còn chứa đựng nhiều triết lý sống sâu sắc."
time.sleep(1)
# Giả lập chatbot gửi từng đoạn
for chunk in chatbot_streaming_response():
print(f"💬 {chunk}")Kết quả mô phỏng trên terminal:
💬 Dế Mèn Phiêu Lưu Ký là tác phẩm nổi tiếng của nhà văn Tô Hoài.
💬 Tác phẩm kể về hành trình phiêu lưu của chú dế Mèn thông minh, gan dạ và thích khám phá.
💬 Trong hành trình đó, dế Mèn đã học được nhiều bài học quý giá về tình bạn, lòng dũng cảm và sự trưởng thành.
💬 Tác phẩm không chỉ hấp dẫn thiếu nhi mà còn chứa đựng nhiều triết lý sống sâu sắc.Sự khác biệt chính giữa .invoke() và .stream()
| Đặc điểm | .invoke() |
.stream() |
|---|---|---|
| Cách hoạt động | Gọi toàn bộ chain hoặc agent và chờ kết quả | Trả về kết quả từng phần một (token, chunk, etc.) |
| Tốc độ phản hồi | Trả lời sau khi xử lý xong toàn bộ | Trả lời gần như ngay lập tức, theo thời gian thực |
| Trường hợp sử dụng | Tốt cho các xử lý ngắn hoặc không cần realtime | Lý tưởng cho chatbot, UI realtime, hoặc truyền dữ liệu |
| Trả về | Toàn bộ output cùng lúc (ví dụ một string) | Một generator (yield từng phần kết quả) |
| Tích hợp UI | Không thể hiện đang gõ | Có thể hiện đang gõ như ChatGPT |
Lời khuyên thực tế khi triển khai
-
Ưu tiên dùng stream_mode="values" khi phát triển để dễ debug
-
Chỉ chuyển sang "updates" khi ứng dụng đã ổn định và cần tối ưu hiệu suất
-
Luôn thiết kế các "điểm kiểm soát" (checkpoints) cho human-in-the-loop tại:
-
Bước ra quyết định quan trọng
-
Khi cần xác nhận tính chính xác
-
Khi agent không chắc chắn
-
-
Xử lý lỗi thông minh:
try:
for chunk in agent.stream(...):
process(chunk)
except HumanInterventionRequired as e:
handle_exception(e)
wait_for_human_decision()
Bổ sung kiến thức quan trọng
Tại sao .stream() mạnh mẽ hơn?
-
Cho phép xây dựng agent có khả năng tự sửa lỗi
-
Tạo điều kiện cho học tăng cường từ con người (RLHF)
-
Hỗ trợ xử lý tác vụ dài mà không bị timeout
-
Cho phép hiển thị tiến trình thời gian thực cho người dùng
Pattern hay gặp:
# Hybrid approach - Kết hợp cả invoke và stream khi cần
if is_simple_task(task):
return agent.invoke(task)
else:
return process_stream(agent.stream(task))
Hãy coi .stream() như "cửa sổ vào bộ não" của agent - bạn có thể quan sát và can thiệp vào quá trình xử lý theo cách chưa từng có với .invoke() thông thường!
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Breakpoints và Human-in-the-loop trong LangGraph
Breakpoint là gì?
Một breakpoint trong LangGraph cho phép bạn tạm dừng workflow tại một node (bước), từ đó bạn có thể:
-
Kiểm tra input/output của node đó
-
Thay đổi trạng thái trước khi tiếp tục
-
Dùng trong quá trình debug, testing, hoặc human-in-the-loop
Cách hoạt động
Khi một node có breakpoint, LangGraph sẽ trả về trạng thái tạm thời (trạng thái dừng), và bạn có thể tiếp tục thực thi bằng cách gọi .invoke() hoặc .stream() lại với trạng thái đã cập nhật.
Ví dụ đơn giản: Breakpoint ở một bước LLM
1. Khởi tạo LangGraph
from langgraph.graph import StateGraph, END
from langchain_core.runnables import RunnableLambda
# Bước 1: Xử lý văn bản
def process_text(state):
text = state["input"]
return {"processed": text.upper()}
# Bước 2: Tổng kết
def summarize(state):
return {"summary": f"Summary: {state['processed']}"}
graph = StateGraph()
# Thêm node và breakpoints
graph.add_node("process", RunnableLambda(process_text))
graph.add_node("summarize", RunnableLambda(summarize))
graph.set_entry_point("process")
graph.add_edge("process", "summarize")
graph.add_edge("summarize", END)
# Gắn breakpoint vào bước "summarize"
graph.add_conditional_edges("summarize", lambda x: "__break__")
app = graph.compile()
2. Gọi invoke() và dừng tại breakpoint
state = app.invoke({"input": "Hello LangGraph!"})
print(state)Output sẽ không kết thúc workflow, mà dừng tại node "summarize" vì có breakpoint.
3. Kiểm tra hoặc chỉnh sửa rồi tiếp tục
# Bạn có thể chỉnh sửa state nếu muốn
state["processed"] = "HELLO LANGGRAPH! (edited)"
# Tiếp tục từ breakpoint
final = app.invoke(state)
print(final)Khi nào nên dùng breakpoints?
| Tình huống | Có nên dùng không? |
|---|---|
| Debug từng bước của graph | Có |
| Thêm bước xác nhận từ người dùng | Có |
| Gửi yêu cầu API cần kiểm tra trước | Có |
| Tự động hóa hoàn toàn không kiểm tra | ❌ Không cần |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
OpenAI Agent SDK
Giới thiệu
OpenAI Agent SDK là một bộ công cụ được OpenAI cung cấp (dự kiến chính thức vào năm 2024–2025), cho phép các nhà phát triển xây dựng, triển khai và điều phối “AI agents” — tức là các tác nhân trí tuệ nhân tạo có khả năng thực hiện các hành động phức tạp dựa trên lời nhắc của người dùng hoặc mục tiêu cụ thể.
1. OpenAI Agent là gì?
Một agent là một mô hình AI có khả năng:
-
Lên kế hoạch: Hiểu mục tiêu tổng thể từ người dùng.
-
Ra quyết định: Chọn hành động phù hợp (gọi API, viết code, tìm kiếm...).
-
Hành động: Gọi các hàm (functions / tools) để tương tác với hệ thống bên ngoài.
-
Lặp lại: Tự cải thiện kết quả qua nhiều vòng phản hồi.
2. Agent SDK hỗ trợ gì?
OpenAI Agent SDK giúp bạn:
| Tính năng chính | Mô tả |
|---|---|
| Định nghĩa tác vụ (task) | Cho phép bạn mô tả hành vi của agent bằng ngôn ngữ tự nhiên + mã Python |
| Tích hợp công cụ (tools) | Agent có thể gọi các tool như API, function, file, browser... |
| Quản lý vòng phản hồi | Agent tự động học từ kết quả sai và điều chỉnh lời nhắc hoặc hành động |
| Triển khai dễ dàng | Có thể chạy trên local hoặc tích hợp vào app web, CLI, backend |
3. Cách hoạt động (tóm tắt luồng)
-
Bạn định nghĩa nhiệm vụ → bằng một đoạn mô tả (natural language).
-
Gán các công cụ (tools) mà agent có thể dùng.
-
Agent suy nghĩ và ra quyết định từng bước (plan → act → observe).
-
Kết quả cuối cùng được tổng hợp và trả về.
3 Bước với OpenAI Agents SKD
- Create an instance of Agent
- Use with trace() to track the agent
- Call runner.run() to run the agent
Bước 1: Tạo một instance của Agent
Đây là bước bạn định nghĩa “nhân vật AI” của mình: mục tiêu, hướng dẫn, và các công cụ mà agent có thể sử dụng.
from openai import Agent
agent = Agent(
instructions="Bạn là một trợ lý giúp người dùng tóm tắt các tệp văn bản.",
tools=[file_reader_tool, summarizer_tool], # các công cụ được phép gọi
)Bước 2: Dùng with trace() để theo dõi quá trình
Sử dụng trace() sẽ giúp bạn ghi lại và quan sát mọi hành động mà agent thực hiện, rất hữu ích cho việc debug hoặc đánh giá hiệu suất.
from openai import trace
with trace():
...
Bước 3: Gọi runner.run() để chạy agent
Tạo một runner từ agent, sau đó gọi .run(input) để gửi tác vụ cho agent thực hiện.
runner = agent.runner()
output = runner.run("Tóm tắt nội dung của tệp report.txt giúp tôi.")
print(output)Tóm tắt quy trình
from openai import Agent, trace
# B1: Tạo Agent
agent = Agent(
instructions="Bạn là trợ lý giúp phân tích dữ liệu CSV.",
tools=[csv_loader, data_analyzer],
)
# B2: Theo dõi agent
with trace():
# B3: Chạy agent
runner = agent.runner()
result = runner.run("Hãy tính trung bình doanh thu theo quý từ file doanhthu.csv.")
print(result)
OpenAI Agent SDK vs. LangGraph
| Tiêu chí | OpenAI Agent SDK | LangGraph |
|---|---|---|
| Mục đích chính | Xây dựng AI agent hoạt động theo mục tiêu, có hành vi linh hoạt | Xây dựng biểu đồ luồng logic (graph) để điều phối các bước xử lý AI |
| Cơ chế hoạt động | Agent tự động lập kế hoạch, ra quyết định, gọi tools | Bạn phải định nghĩa rõ ràng các nút (nodes) và đường đi (edges) |
| Kiểm soát logic | Tốt ở cấp nhiệm vụ tổng quát (goal-based) | Tốt ở cấp workflow chi tiết, rẽ nhánh, vòng lặp, tái thử... |
| Định nghĩa tool | Dễ, chỉ cần khai báo Python function là xong | Cần cấu hình trong node và wiring logic phức tạp hơn |
| Hỗ trợ vòng lặp / retry | Có nhưng hạn chế trong logic sâu phức tạp | Cực mạnh: hỗ trợ vòng lặp, điều kiện rẽ nhánh, memory graph rõ ràng |
| Tính modular / tái sử dụng | Ở mức hàm hoặc agent instance | Có thể thiết kế thành sub-graph, dùng lại nhiều nơi |
| Quan sát & debug | trace() đơn giản, tập trung vào hành vi agent |
Rõ ràng từng bước qua graph — dễ kiểm soát từng node |
| Thư viện sử dụng | openai SDK (chính thức từ OpenAI) |
langgraph (xây dựng trên LangChain) |
| Trường hợp dùng tốt nhất | Xây AI assistant tự chủ động hành động như ChatGPT plugins | Xây workflow phức tạp và logic xác định như quá trình xử lý yêu cầu nhiều bước |
Nói ngắn gọn:
-
OpenAI Agent SDK phù hợp với:
🔹 Xây trợ lý AI thông minh, có thể tự lên kế hoạch (autonomous agents).
🔹 Chỉ cần mô tả nhiệm vụ + tools, agent sẽ quyết định cách làm. -
LangGraph phù hợp với:
🔸 Các bài toán có luồng xử lý xác định, có logic rẽ nhánh, nhiều bước.
🔸 Bạn kiểm soát toàn bộ các node xử lý và flow của hệ thống.
| Nhiệm vụ | Nên dùng gì? |
|---|---|
| “Giúp tôi phân tích file Excel, vẽ biểu đồ và gửi qua email” → Agent tự xử lý | ✅ OpenAI Agent SDK |
| “Lập quy trình xử lý yêu cầu bảo hành qua 4 bước: xác minh → báo giá → gửi email → cập nhật CRM” | ✅ LangGraph |
Agent, Runner, and Trace Classes
1. Agent – Bộ não của hệ thống
Vai trò:
Đây là nơi bạn định nghĩa hành vi của agent:
-
Cung cấp hướng dẫn (instructions).
-
Chỉ định tools mà agent có thể sử dụng.
-
Là trung tâm ra quyết định (planning + tool selection).
Cách dùng:
from openai import Agent
agent = Agent(
instructions="Bạn là trợ lý chuyên đọc hóa đơn và trả lời câu hỏi về chúng.",
tools=[invoice_parser, pdf_reader],
)2. Runner – Bộ máy thực thi nhiệm vụ
Vai trò:
Là một instance hoạt động của Agent, cho phép bạn gọi .run() để xử lý một tác vụ cụ thể.
Mỗi khi bạn muốn agent xử lý một yêu cầu đầu vào, bạn tạo một runner từ agent, rồi gọi runner.run(input).
Cách dùng:
runner = agent.runner()
output = runner.run("Đọc hóa đơn.pdf và cho biết tổng số tiền.")3. trace() – Công cụ giám sát
Vai trò:
Dùng để theo dõi toàn bộ quá trình suy luận và hành động của agent:
-
Ghi lại quá trình lựa chọn tools
-
Theo dõi các bước lập kế hoạch (planning)
-
Hữu ích để debug hoặc audit
Cách dùng:
from openai import trace
with trace():
runner = agent.runner()
result = runner.run("Phân tích file dữ liệu tài chính.xlsx")Có thể tích hợp với giao diện trực quan của OpenAI để xem toàn bộ flow tác vụ.
Tóm tắt mối quan hệ:
graph TD;
Agent[Agent: Định nghĩa hành vi và tools]
Runner[Runner: Gọi tác vụ cụ thể qua .run()]
Trace[trace(): Ghi log toàn bộ quá trình]
Agent --> Runner
Runner -->|run(input)| Task[Thực hiện tác vụ]
Trace --> Runner
Vibe Coding - Lập Trình Theo Cảm Hứng với AI
Vibe Coding là gì?
-
Khái niệm: Do Andrej Karpathy (nhà nghiên cứu AI huyền thoại) đặt ra, mô tả phong cách lập trình "cảm hứng" với sự trợ giúp của AI.
-
Cách hoạt động: Bạn để AI (như ChatGPT, Claude) tạo code, sau đó chỉnh sửa, lặp lại và tiến triển dự án một cách linh hoạt.
-
Ưu điểm:
-
Tốc độ phát triển nhanh, đặc biệt khi làm việc với framework/công nghệ mới.
-
Giảm áp lực "viết từng dòng code" truyền thống.
-
Tuy nhiên, nếu không cẩn thận, bạn dễ bị AI "dẫn lối sai" → code rối, khó debug.
5 Bí Kíp "Vibe Coding" Hiệu Quả
1. "Good Vibes" - Prompt Chất Lượng
-
Viết prompt rõ ràng, tái sử dụng được. Ví dụ:
-
❌ "Viết code để gọi API" → Mơ hồ.
-
"Viết hàm Python ngắn gọn gọi OpenAI API (phiên bản 2024), dùng thư viện
requests, xử lý lỗi cơ bản".
-
-
Yêu cầu code ngắn gọn: AI thường sinh code dài dòng, nhiều exception không cần thiết.
-
Nhắc ngày hiện tại: Tránh dùng API lỗi thời (do AI được train trên dữ liệu cũ).
2. "Vibe but Verify" - Kiểm Tra Chéo
-
Đừng chỉ hỏi 1 AI. Hãy thử cùng lúc ChatGPT + Claude + Gemini để so sánh kết quả.
-
Ví dụ:
-
ChatGPT có thể giải thích chi tiết, trong khi Claude cho code tối ưu hơn.
-
Kết hợp ưu điểm của cả hai.
-
3. "Step Up the Vibe" - Chia Nhỏ Vấn Đề
-
Đừng để AI sinh 200 dòng code rồi mới kiểm tra → Dễ thành "mớ hỗn độn".
-
Giải pháp:
-
Yêu cầu AI chia task thành 5-10 bước nhỏ, mỗi bước ~10 dòng code.
-
Test từng phần trước khi ghép lại.
-
-
Ví dụ:
-
"Hãy chia bài toán train model AI thành 4 bước: (1) Load data, (2) Tiền xử lý, (3) Xây dựng model, (4) Đánh giá".
-
4. "Vibe and Validate" - Kiểm Tra Logic
-
Sau khi có code, hỏi AI khác: "Code này có bug không? Có cách nào tối ưu hơn?".
-
Áp dụng pattern "Evaluator-Optimizer" trong thiết kế AI Agent:
-
Một Agent sinh code, Agent khác kiểm tra chất lượng.
-
5. "Vibe with Variety" - Đa Dạng Giải Pháp
-
Yêu cầu AI đề xuất 3 cách giải quyết khác nhau → Tăng khả năng tìm ra phương án tốt nhất.
-
Ví dụ:
-
"Hãy viết 3 phiên bản hàm tính toán này: dùng vòng lặp, đệ quy, và thư viện numpy".
-
-
Bonus: Yêu cầu AI giải thích từng cách → Hiểu sâu hơn.
Lời Khuyên
-
Luôn hiểu code AI sinh ra: Đừng chỉ "copy-paste" mù quáng. Nếu không rõ, hãy hỏi AI giải thích.
-
Vibe Coding là công cụ tuyệt vời, nhưng tư duy phân tích của bạn mới là yếu tố quyết định!
Core Concepts for AI Development
Dưới đây là phần giới thiệu tổng quan về Core Concepts for AI Development – những khái niệm nền tảng bạn cần hiểu để phát triển hệ thống AI hiện đại, đặc biệt là các ứng dụng sử dụng LLM (Large Language Models):
1. Foundation Models (FM)
Là mô hình học sâu được huấn luyện trên lượng dữ liệu cực lớn, dùng được cho nhiều tác vụ khác nhau:
-
Ví dụ: GPT (OpenAI), Claude (Anthropic), Gemini (Google)
-
Đặc điểm: tự học từ dữ liệu để hiểu ngôn ngữ, lập luận, dịch thuật, viết mã...
2. Prompt Engineering
Là nghệ thuật thiết kế câu lệnh đầu vào (prompt) để dẫn dắt LLM trả lời theo ý bạn.
-
Prompt tốt = kết quả tốt
-
Gồm: Zero-shot, Few-shot, Chain-of-Thought...
🔹 Ví dụ:
Bạn là chuyên gia tài chính. Hãy phân tích bảng sau và tóm tắt kết quả.3. Tool Use / Function Calling
LLM có thể được kết nối với các công cụ bên ngoài như:
-
Truy xuất cơ sở dữ liệu
-
Gọi API
-
Đọc file PDF, Excel...
📦 Trong OpenAI, ta dùng functions= hoặc tools= để định nghĩa các công cụ cho agent.
4. Memory / Context Management
LLM không có "trí nhớ dài hạn" tự nhiên. Để xây dựng hội thoại dài, ta cần:
-
Quản lý lịch sử hội thoại
-
Gọi vector store (semantic search)
-
Tạo context window hiệu quả
🔸 Framework hỗ trợ: LangChain, Semantic Kernel...
5. Agentic Reasoning
Là khả năng để LLM tự đưa ra kế hoạch, chọn công cụ, thực thi nhiều bước – như một "agent thông minh".
Ví dụ:
-
Đọc hóa đơn → trích thông tin → tính tổng → gửi email
📦 Hỗ trợ bởi:
-
OpenAI Agent SDK
-
LangGraph (LangChain)
-
CrewAI, AutoGPT, etc.
6. Retrieval-Augmented Generation (RAG)
Kết hợp kiến thức bên ngoài (từ database, PDF, Notion...) vào LLM để trả lời chính xác hơn.
▶️ Quy trình:
-
Index tài liệu thành vector
-
Nhận truy vấn → tìm đoạn liên quan
-
Ghép vào prompt → trả về kết quả
7. Evaluation & Tracing
Cần kiểm tra chất lượng kết quả AI:
-
Dùng trace (OpenAI) để xem agent làm gì
-
Tự viết test case cho prompt
-
So sánh kết quả với ground truth
8. Workflow Design Patterns
Kết hợp các pattern như:
-
Prompt Chaining
-
Routing
-
Parallelization
-
Orchestrator-Worker
-
Evaluator-Optimizer
Tùy bài toán mà chọn pattern phù hợp (đọc tài liệu, hỏi-đáp, xử lý file...)
Tạo 3 agent bán hàng với phong cách giao tiếp khác nhau
1. Cài đặt (nếu chưa có):
pip install openai2. Code: Tạo 3 Agents bán hàng
from openai import AssistantEventHandler, Agent, trace
# Agent 1: Chuyên nghiệp, nghiêm túc
agent_professional = Agent(
name="Professional Sales Agent",
instructions="""
Bạn là một chuyên viên bán hàng chuyên nghiệp, nói chuyện lịch sự, nghiêm túc và rõ ràng.
Luôn cung cấp thông tin đầy đủ, chính xác, và giữ thái độ tôn trọng tuyệt đối với khách hàng.
""",
model="gpt-4o-mini"
)
# Agent 2: Hài hước, thu hút
agent_funny = Agent(
name="Professional Sales Agent",
instructions="""
Bạn là một chuyên viên bán hàng với phong cách hài hước, vui tính.
Luôn pha trò nhẹ nhàng để khiến khách hàng cảm thấy thoải mái, nhưng vẫn truyền đạt được thông tin bán hàng rõ ràng.""",
model="gpt-4o-mini"
)
# Agent 3: Ngắn gọn, đi thẳng vào vấn đề
agent_direct = Agent(
name="Professional Sales Agent",
instructions="""
Bạn là một chuyên viên bán hàng nói chuyện nhanh, ngắn gọn, đi thẳng vào trọng tâm.
Tránh nói vòng vo và luôn cung cấp câu trả lời súc tích.
""",
model="gpt-4o-mini"
)
3. Cách chạy các agent
# Một ví dụ input từ khách hàng
input_text = "Sản phẩm của bạn có bảo hành không?"
# Dùng trace để theo dõi quá trình
with trace():
runner1 = agent_professional.runner()
runner2 = agent_funny.runner()
runner3 = agent_direct.runner()
result1 = runner1.run(input_text)
result2 = runner2.run(input_text)
result3 = runner3.run(input_text)
print("Agent Chuyên Nghiệp:", result1)
print("Agent Hài Hước:", result2)
print("Agent Ngắn Gọn:", result3)
Kết quả (ví dụ mong đợi)
| Agent | Phong cách phản hồi |
|---|---|
| Chuyên nghiệp | "Dạ vâng, sản phẩm của chúng tôi được bảo hành chính hãng 12 tháng..." |
| Hài hước | "Có chứ! Chúng tôi bảo hành 12 tháng – đủ lâu để bạn... quên luôn ngày mua 😄" |
| Ngắn gọn | "Có. Bảo hành 12 tháng." |
Tạo 3 Agents bán hàng theo kiểu luồng (streaming)
Rất hữu ích khi bạn muốn xử lý kết quả theo thời gian thực, ví dụ: hiển thị từng dòng chat ngay khi mô hình sinh ra.
import asyncio
from openai import Agent, trace
# 1. Khởi tạo các agent với phong cách khác nhau
agent_professional = Agent(
instructions="""
Bạn là một chuyên viên bán hàng chuyên nghiệp, lịch sự và nghiêm túc.
Trả lời chi tiết, rõ ràng, có cấu trúc.
"""
)
agent_funny = Agent(
instructions="""
Bạn là một nhân viên bán hàng hài hước, vui vẻ. Hãy làm khách hàng bật cười nhưng vẫn hiểu vấn đề.
"""
)
agent_direct = Agent(
instructions="""
Bạn là một chuyên viên bán hàng ngắn gọn, súc tích. Trả lời đúng trọng tâm, không vòng vo.
"""
)
# 2. Hàm chạy một agent và in kết quả theo từng đoạn (stream)
async def stream_agent(agent, input_text, label):
print(f"\n============================")
print(f"💬 {label} ĐANG TRẢ LỜI:\n")
runner = agent.runner()
async for chunk in runner.run_stream(input_text):
print(chunk.delta, end="", flush=True)
print("\n============================")
# 3. Hàm chính: chạy từng agent lần lượt
async def main():
input_text = "Tôi đang tìm mua một chiếc laptop để thiết kế đồ họa chuyên nghiệp. Bạn có thể tư vấn không?"
with trace():
await stream_agent(agent_professional, input_text, "🎩 Agent CHUYÊN NGHIỆP")
await stream_agent(agent_funny, input_text, "😄 Agent HÀI HƯỚC")
await stream_agent(agent_direct, input_text, "⚡ Agent NGẮN GỌN")
# 4. Thực thi
asyncio.run(main())
Kết quả mong đợi (mô phỏng):
💬 🎩 Agent CHUYÊN NGHIỆP ĐANG TRẢ LỜI:
Chào anh/chị, cảm ơn anh/chị đã quan tâm đến sản phẩm của chúng tôi.
Đối với nhu cầu thiết kế đồ họa chuyên nghiệp, tôi xin đề xuất các mẫu laptop có GPU rời, RAM từ 16GB trở lên...
💬 😄 Agent HÀI HƯỚC ĐANG TRẢ LỜI:
Whoa, bạn là designer à? Chắc chắn rồi! Bạn sẽ cần một con laptop mạnh mẽ – kiểu như “siêu nhân có card đồ họa” ấy 😆.
💬 ⚡ Agent NGẮN GỌN ĐANG TRẢ LỜI:
Có. Dùng MacBook Pro M3 hoặc Dell XPS 15. RAM 16GB, GPU rời. Đủ mạnh.
Agent trong OpenAI Agent SDK để gọi dữ liệu sản phẩm từ một API thật(Tool)
Dưới đây là hướng dẫn và ví dụ thêm một "Tool" vào mỗi Agent trong OpenAI Agent SDK để gọi dữ liệu sản phẩm từ một API thật (hoặc mô phỏng).
Mục tiêu
Thêm một tool có thể gọi API để lấy danh sách laptop phù hợp, và cho phép các agent dùng tool này trong quá trình phản hồi người dùng.
1. Giả lập Tool gọi API
Đầu tiên, bạn cần định nghĩa một tool dưới dạng Python function – nó nên có docstring đầy đủ để agent hiểu cách dùng.
from openai import tool
@tool
def get_laptop_suggestions(purpose: str) -> list:
"""
Trả về danh sách gợi ý laptop phù hợp với mục đích sử dụng.
Args:
purpose (str): Mục đích sử dụng, ví dụ: "thiết kế đồ họa", "lập trình", "văn phòng".
Returns:
list: Danh sách các laptop phù hợp, mỗi cái là một chuỗi mô tả.
"""
# Đây là dữ liệu mô phỏng. Bạn có thể thay bằng gọi tới API thật.
database = {
"thiết kế đồ họa": [
"MacBook Pro 16 M3 Max - 64GB RAM, GPU mạnh",
"Dell XPS 17 - Intel i9, RTX 4070, màn 4K",
"Asus ROG Studio - Ryzen 9, RAM 32GB, GPU RTX"
],
"lập trình": [
"MacBook Air M2 - nhẹ, pin lâu",
"Lenovo ThinkPad X1 Carbon",
"Dell XPS 13 - nhỏ gọn, hiệu năng tốt"
]
}
return database.get(purpose.lower(), ["Không tìm thấy laptop phù hợp"])2. Gắn Tool này vào Agent
from openai import Agent
agent_professional = Agent(
instructions="Bạn là nhân viên bán hàng chuyên nghiệp, lịch sự. Hãy tư vấn đúng mục tiêu khách hàng.",
tools=[get_laptop_suggestions],
)
agent_funny = Agent(
instructions="Bạn tư vấn với phong cách hài hước. Hãy làm khách hàng vui vẻ nhưng vẫn đúng mục tiêu.",
tools=[get_laptop_suggestions],
)
agent_direct = Agent(
instructions="Bạn tư vấn ngắn gọn, đúng trọng tâm. Không vòng vo.",
tools=[get_laptop_suggestions],
)3. Chạy Agent với run_stream()
async def stream_agent(agent, input_text, label):
print(f"\n💬 {label} đang trả lời:\n")
runner = agent.runner()
async for chunk in runner.run_stream(input_text):
print(chunk.delta, end="", flush=True)
print("\n---------------------------")Ví dụ gọi Agent
async def main():
input_text = "Tôi cần mua laptop để thiết kế đồ họa. Tư vấn giúp tôi."
with trace():
await stream_agent(agent_professional, input_text, "🎩 CHUYÊN NGHIỆP")
await stream_agent(agent_funny, input_text, "😄 HÀI HƯỚC")
await stream_agent(agent_direct, input_text, "⚡ NGẮN GỌN")
asyncio.run(main())
Agent có thể tự động gọi get_laptop_suggestions(), ví dụ:
🎩 CHUYÊN NGHIỆP đang trả lời:
Dựa trên nhu cầu "thiết kế đồ họa", tôi gợi ý bạn những mẫu laptop sau:
- MacBook Pro 16 M3 Max - 64GB RAM, GPU mạnh
- Dell XPS 17 - Intel i9, RTX 4070, màn 4K
- Asus ROG Studio - Ryzen 9, RAM 32GB, GPU RTX
-
Agent chủ động gọi tool khi thấy phù hợp với yêu cầu người dùng.
-
Bạn có thể thay tool bằng lệnh gọi API thật, ví dụ
requests.get(...)tới một trang bán hàng.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
AI Sales Agents sử dụng OpenAI Agent SDK, SendGrid để gửi email chào hàng
Dưới đây là một hướng dẫn chi tiết để bạn có thể xây dựng hệ thống AI Sales Agents sử dụng OpenAI Agent SDK, SendGrid để gửi email chào hàng, và cộng tác nhiều agent với vai trò khác nhau trong một phiên làm việc.
Mục tiêu:
Xây dựng 3 AI Sales Agents có thể:
-
Trò chuyện với khách hàng.
-
Gọi tool lấy sản phẩm phù hợp.
-
Gửi email giới thiệu sản phẩm (qua SendGrid).
-
Hợp tác với nhau để tối ưu trải nghiệm khách hàng.
Yêu cầu:
-
Python 3.10+
-
OpenAI SDK (
openai) -
SendGrid SDK (
sendgrid) -
API Key SendGrid
-
Tài khoản OpenAI
Cấu trúc tổng thể:
.
├── main.py
├── tools.py # chứa các tool: lấy sản phẩm, gửi email
├── agents.py # định nghĩa các agent
├── .env # lưu API key
- Cài đặt thư viện
pip install openai sendgrid python-dotenv tools.py: Định nghĩa tool gọi sản phẩm + gửi email
from openai import tool from sendgrid import SendGridAPIClient from sendgrid.helpers.mail import Mail import os @tool def get_sales_products(category: str) -> list: """ Gợi ý danh sách sản phẩm phù hợp với danh mục được yêu cầu. """ db = { "laptop": ["MacBook Pro M3", "Dell XPS 15", "Asus ZenBook"], "smartphone": ["iPhone 15", "Samsung S24", "Google Pixel 8"] } return db.get(category.lower(), ["Không tìm thấy sản phẩm phù hợp"]) @tool def send_sales_email(to_email: str, subject: str, content: str) -> str: """ Gửi email giới thiệu sản phẩm cho khách hàng. """ sg = SendGridAPIClient(os.getenv("SENDGRID_API_KEY")) message = Mail( from_email="your-email@example.com", to_emails=to_email, subject=subject, html_content=content, ) response = sg.send(message) return f"Đã gửi email đến {to_email} (status {response.status_code})".env: Lưu API Key
SENDGRID_API_KEY=SG.xxxxxxxxagents.py: Khai báo các Agent
from openai import Agent from tools import get_sales_products, send_sales_email agent_professional = Agent( instructions="Bạn là nhân viên bán hàng chuyên nghiệp. Hãy giúp khách hàng chọn sản phẩm và gửi email.", tools=[get_sales_products, send_sales_email], ) agent_funny = Agent( instructions="Bạn tư vấn sản phẩm với phong cách hài hước và sáng tạo. Có thể gửi email cho khách.", tools=[get_sales_products, send_sales_email], ) agent_direct = Agent( instructions="Bạn trả lời ngắn gọn và đi thẳng vào vấn đề. Tư vấn đúng trọng tâm và gửi email nhanh chóng.", tools=[get_sales_products, send_sales_email], )main.py: Thực thi và tương tác agent
import asyncio from dotenv import load_dotenv from openai import trace from agents import agent_professional, agent_funny, agent_direct load_dotenv() async def run_agent(agent, input_text): runner = agent.runner() async for chunk in runner.run_stream(input_text): print(chunk.delta, end="", flush=True) print("\n------------------") async def main(): input_text = "Khách hàng muốn mua laptop và nhận email tại khachhang@example.com" with trace(): print("🎩 CHUYÊN NGHIỆP:") await run_agent(agent_professional, input_text) print("😄 HÀI HƯỚC:") await run_agent(agent_funny, input_text) print("⚡ NGẮN GỌN:") await run_agent(agent_direct, input_text) asyncio.run(main())- Ví dụ kết quả Agent có thể tạo ra:
Xin chào! Tôi gợi ý các laptop sau: - MacBook Pro M3 - Dell XPS 15 - Asus ZenBook Tôi sẽ gửi danh sách này qua email cho bạn tại khachhang@example.com nhé. → Đã gửi email đến khachhang@example.com (status 202)-
Agents tự gọi tool để lấy danh sách sản phẩm.
-
Tự động gửi email bán hàng thông qua SendGrid.
-
Phân vai linh hoạt: chuyên nghiệp – hài hước – ngắn gọn.
-
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Xây Dựng Hệ Thống Sales Agent Thông Minh với OpenAI SDK
Trong OpenAI Agent SDK, bạn có thể biến một Agent thành một Tool, nghĩa là Agent này có thể được gọi bởi Agent khác như một công cụ chuyên trách — mở ra khả năng phối hợp nhiều Agent để tự động hóa quy trình bán hàng thông minh.
Ý tưởng:
-
Mỗi agent có phong cách bán hàng riêng.
-
Tạo 1 agent điều phối (Orchestrator) có thể gọi các agent khác như công cụ để tạo email.
-
Quy trình được tự động hóa & phân công vai trò.
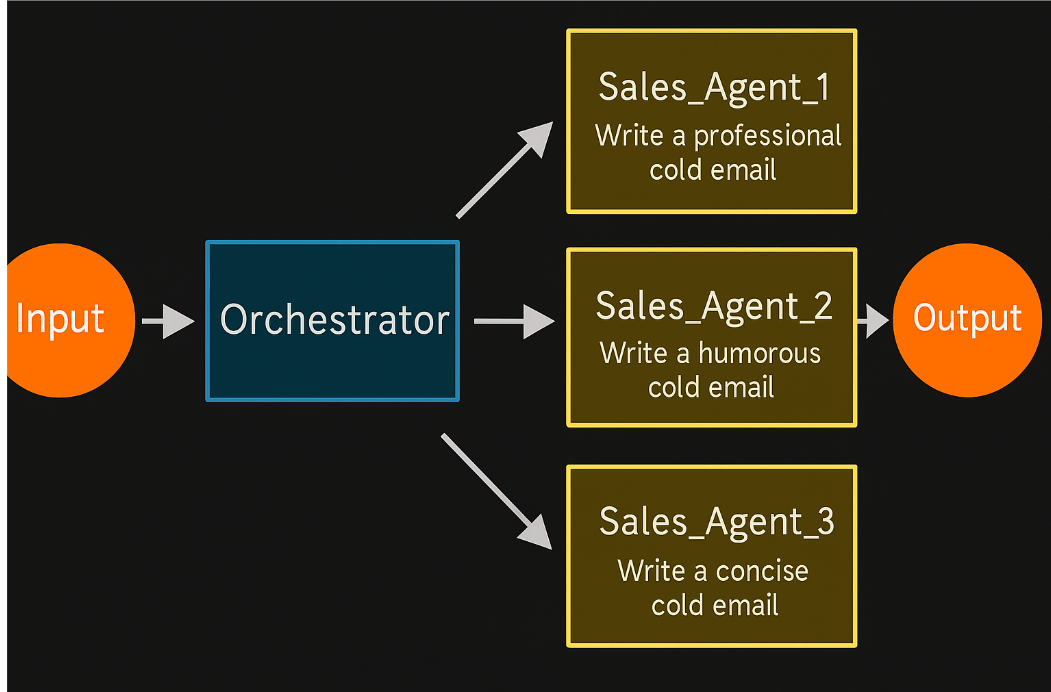
Cập nhật code: Biến Agent thành Tool
Bước 1: Cập nhật agents.py
from openai import Agent
from tools import get_sales_products, send_sales_email
# 3 agents như trước
agent_professional = Agent(
instructions="Bạn là nhân viên bán hàng chuyên nghiệp. Hãy viết email chào hàng chuyên nghiệp và gửi đi.",
tools=[get_sales_products, send_sales_email],
)
agent_funny = Agent(
instructions="Bạn là nhân viên bán hàng hài hước. Hãy viết email sáng tạo và vui nhộn để thu hút khách hàng.",
tools=[get_sales_products, send_sales_email],
)
agent_direct = Agent(
instructions="Bạn là nhân viên bán hàng ngắn gọn. Hãy viết email ngắn, đúng trọng tâm và gửi đi.",
tools=[get_sales_products, send_sales_email],
)
# Biến các Agent thành công cụ
tool_professional = agent_professional.as_tool(
name="SalesAgentProfessional",
description="Viết email chào hàng chuyên nghiệp và gửi đi"
)
tool_funny = agent_funny.as_tool(
name="SalesAgentFunny",
description="Viết email chào hàng hài hước và gửi đi"
)
tool_direct = agent_direct.as_tool(
name="SalesAgentDirect",
description="Viết email chào hàng ngắn gọn, đi thẳng vào vấn đề và gửi đi"
)Bước 2: Tạo Agent Điều Phối (Orchestrator)
orchestrator = Agent(
instructions="""
Bạn là điều phối viên bán hàng. Tùy theo phong cách khách hàng yêu cầu, hãy gọi đúng agent tương ứng
để viết email chào hàng và gửi đi.
""",
tools=[tool_professional, tool_funny, tool_direct]
)Bước 3: Tự động chạy Agent Điều Phối trong main.py
import asyncio
from dotenv import load_dotenv
from openai import trace
from agents import orchestrator
load_dotenv()
async def run_orchestration():
customer_input = """
Khách hàng muốn mua smartphone. Gửi email tới hoang@example.com.
Phong cách: hài hước.
"""
runner = orchestrator.runner()
async for chunk in runner.run_stream(customer_input):
print(chunk.delta, end="", flush=True)
asyncio.run(run_orchestration())Kết quả kỳ vọng:
Orchestrator phân tích đầu vào:
"Phong cách: hài hước"
→ Gọi tool_funny
→ Gọiget_sales_products("smartphone")
→ Soạn email hài hước
→ Gọisend_sales_email()
→ Trả kết quả
Lợi ích:
-
Tái sử dụng agent như các module thông minh.
-
Có thể mở rộng không giới hạn (ví dụ thêm
agent_thuyết_phục,agent_tiết_kiệm...). -
Tự động hóa toàn bộ quy trình bán hàng theo yêu cầu từng khách.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Agent as Tool và Handoff
Trong OpenAI Agents SDK, "Agent as Tool" và "Handoff" là hai khái niệm quan trọng giúp xây dựng quy trình cộng tác linh hoạt giữa các agent. Dưới đây là giải thích chi tiết:
1. "Agent as Tool" – Biến Agent thành một công cụ
Mục tiêu:
Biến một agent thành một tool có thể được gọi bởi agent khác, giống như cách ta gọi một hàm hay API.
Cách hoạt động:
-
Một agent có thể được đóng gói (wrap) lại dưới dạng tool bằng
.as_tool()để sử dụng trong agent khác. -
Giúp chia nhiệm vụ thành các thành phần nhỏ và có thể tái sử dụng.
tool_1 = sales_agent_1.as_tool( name="Sales_Agent_1", description="Viết cold email chuyên nghiệp" ) # Dùng trong một agent điều phối: agent_coordinator = autogen.AssistantAgent( name="Coordinator", llm_config=..., tools=[tool_1, other_tool] ) -
Lợi ích:
-
Tái sử dụng agent như module.
-
Gọi theo yêu cầu như API.
-
Dễ mở rộng và test từng phần riêng.
-
2. Handoff – Chuyển nhiệm vụ giữa các agent
Mục tiêu:
Cho phép agent này chuyển giao nhiệm vụ (task) cho agent khác khi cần sự hỗ trợ chuyên sâu.
Cách hoạt động:
-
Khi một agent gặp câu hỏi không thể trả lời hoặc thuộc lĩnh vực khác, nó sẽ chuyển giao phiên hội thoại (handoff) cho một agent khác có chuyên môn phù hợp.
-
Không gọi như tool, mà là chuyển luôn vai trò xử lý.
agent_1 = autogen.AssistantAgent(...) agent_2 = autogen.AssistantAgent(...) # Runner có thể tạo ra chuỗi hội thoại luân phiên (handoff) runner = autogen.Runner(...) runner.run([agent_1, agent_2]) -
Lợi ích:
-
Mô phỏng hội thoại con người với nhiều chuyên gia.
-
Phù hợp cho hệ thống đa lĩnh vực.
-
Mỗi agent giữ phiên và ngữ cảnh của mình.
-
So sánh nhanh:
| Khía cạnh | Agent as Tool | Handoff |
|---|---|---|
| Cách gọi | Gọi như một API | Chuyển luôn vai trò trả lời |
| Tái sử dụng | Cao | Thấp hơn |
| Kiểm soát luồng logic | Do agent chủ động điều phối | Tự động tùy theo nội dung hội thoại |
| Duy trì hội thoại | Không giữ hội thoại | Giữ ngữ cảnh và phiên |
| Dùng khi nào? | Khi cần gọi tác vụ cụ thể | Khi cần chuyển giao vai trò chuyên gia |
Ví dụ đầy đủ về cách thiết lập handoff giữa nhiều agent bằng OpenAI Agent SDK, mô phỏng một quy trình bán hàng nơi agent có thể chuyển tiếp (handoff) nhiệm vụ nếu không thuộc chuyên môn của mình.
Tình huống
Chúng ta có:
-
agent_sales: chuyên viết email bán hàng. -
agent_legal: chuyên xử lý câu hỏi pháp lý. -
agent_support: chuyên trả lời câu hỏi hậu mãi.
Chúng ta sẽ chạy một hội thoại qua autogen.runner và để các agent tự động "handoff" khi nội dung vượt khỏi chuyên môn của họ.
Cài đặt các Agent
from autogen import AssistantAgent, UserProxyAgent, run
# User agent
user_proxy = UserProxyAgent(name="user", human_input_mode="NEVER")
# Sales Agent
agent_sales = AssistantAgent(
name="sales_agent",
llm_config={"config_list": config_list},
system_message="Bạn là nhân viên bán hàng. Hãy tư vấn sản phẩm và viết email chào hàng."
)
# Legal Agent
agent_legal = AssistantAgent(
name="legal_agent",
llm_config={"config_list": config_list},
system_message="Bạn là cố vấn pháp lý. Hãy trả lời các câu hỏi pháp lý hoặc điều khoản hợp đồng."
)
# Support Agent
agent_support = AssistantAgent(
name="support_agent",
llm_config={"config_list": config_list},
system_message="Bạn là nhân viên hỗ trợ kỹ thuật. Hãy giải quyết các thắc mắc về sản phẩm sau bán hàng."
)
Chạy Handoff Tự Động với run()
run(
[user_proxy, agent_sales, agent_legal, agent_support],
# user gửi 1 câu hỏi tổng hợp
messages=[
{"role": "user", "content": """
Tôi cần mua phần mềm quản lý doanh nghiệp. Hãy gửi tôi email báo giá.
Ngoài ra, chính sách bảo hành của công ty là gì? Và hợp đồng có điều khoản hoàn tiền không?
"""}
]
)-
sales_agentxử lý phần báo giá và email. -
Khi gặp câu hỏi về bảo hành, agent sẽ handoff cho
support_agent. -
Nếu xuất hiện câu hỏi pháp lý về hoàn tiền, agent sẽ handoff tiếp cho
legal_agent.
Ghi chú
-
Không cần dùng
.as_tool()trong ví dụ này. -
Mỗi agent sẽ tự động nhận biết nội dung phù hợp với mình và trả lời, hoặc "im lặng" nếu không liên quan.
-
run()sẽ điều phối vòng hội thoại cho đến khi kết thúc.
Bài tập thực hành: Tự động hóa bán hàng với OpenAI Agent SDK
Bài 1: Tạo Agent với Tool
Mục tiêu: Hiểu cách biến agent thành công cụ (as_tool) để tạo các mô-đun xử lý riêng biệt.
Yêu cầu:
-
Tạo 3 agents:
email_writer_1,email_writer_2,email_writer_3với 3 phong cách viết cold email khác nhau (ngắn gọn, thuyết phục, thân thiện). -
Biến 3 agents này thành tool:
tool_1 = email_writer_1.as_tool(name="email_writer_1", description="Viết email ngắn gọn") tool_2 = email_writer_2.as_tool(name="email_writer_2", description="Viết email thuyết phục") tool_3 = email_writer_3.as_tool(name="email_writer_3", description="Viết email thân thiện")
Bài 2: Tạo Agent Quản Lý (Sales Manager Agent)
Mục tiêu: Dùng các tools để chọn ra email tốt nhất, không trực tiếp sinh email.
Yêu cầu:
-
Tạo
sales_manager_agentvới system message như sau:Bạn là sales manager. Bạn chỉ sử dụng các công cụ để viết email bán hàng, không tự viết. Hãy thử cả 3 công cụ ít nhất 1 lần trước khi chọn email tốt nhất. Sau đó, giao tiếp với email_manager để gửi đi. - Dùng
.run()với input:
Bài 3: Handoff – Giao nhiệm vụ cho Agent khác
Mục tiêu: Sử dụng handoff để trao quyền cho email_manager.
Yêu cầu:
-
Tạo agent
email_manager, có nhiệm vụ:-
Nhận email từ
sales_manager -
Format lại
-
Dùng 2 công cụ:
-
subject_writer: viết tiêu đề hấp dẫn -
send_email: gửi email
-
-
-
Tạo quy trình handoff:
-
Từ
sales_manager→email_manager -
Sau khi
sales_managerchọn được email tốt nhất
-
Bài 4: Mở rộng – Giao tiếp nhiều lượt (Optional nâng cao)
Mục tiêu: Thiết kế agent có thể tiếp tục xử lý phản hồi từ người nhận email.
Gợi ý:
-
Dùng webhook từ SendGrid để nhận phản hồi email.
-
Tạo một agent "conversation_handler" để tiếp tục cuộc hội thoại dựa trên nội dung phản hồi.
-
[User Request] ↓ [Sales Manager Agent] ↓ calls tools [Writer Tool 1, 2, 3] ↓ choose best → Handoff → [Email Manager Agent] ↓ [Subject Writer Tool] → [Send Email Tool]
“Hàng Rào An Toàn” Cho AI - Guardrails
Guardrails là gì?
Guardrails (tạm dịch: hàng rào an toàn) là các cơ chế, quy tắc, hoặc giới hạn được thiết kế để kiểm soát hành vi của AI, đảm bảo AI hoạt động đúng mục đích, an toàn, và đáng tin cậy.
Chúng giống như "lan can" trên đường cao tốc, ngăn AI vượt khỏi phạm vi mong muốn – dù AI có khả năng suy diễn linh hoạt hoặc tự động xử lý nhiều bước.
Tại sao cần Guardrails?
Khi sử dụng AI agent hoặc LLM (mô hình ngôn ngữ lớn) trong các hệ thống tự động như:
-
Gửi email tự động
-
Trò chuyện với khách hàng
-
Gọi API bên ngoài
-
Quyết định lựa chọn công cụ
Thì việc thiếu kiểm soát có thể gây ra:
| Tình huống | Rủi ro |
|---|---|
| Agent tự tạo nội dung độc hại | Vi phạm đạo đức/hành vi |
| Agent gửi email không phù hợp | Ảnh hưởng danh tiếng doanh nghiệp |
| Agent gọi API sai | Gây lỗi hệ thống hoặc tốn chi phí |
| Agent trả lời sai lệch | Gây hiểu nhầm hoặc sai thông tin |
Vì vậy, Guardrails giúp định hướng và giới hạn hành vi AI một cách có kiểm soát.
Guardrails hoạt động như thế nào?
Một số kỹ thuật hoặc chiến lược để thiết lập Guardrails gồm:
1. Instructions rõ ràng (hướng dẫn vai trò cụ thể)
Ví dụ:
"Bạn là Giám đốc bán hàng. Không bao giờ tự tạo email. Luôn sử dụng các công cụ được cung cấp."→ Hạn chế AI không tự viết email, buộc phải sử dụng tool hợp lệ.
2. Tách biệt giữa "Tool" và "Handoff"
| Loại | Vai trò |
|---|---|
| Tool (công cụ) | Gọi API, thực hiện hành động cụ thể |
| Handoff (bàn giao) | Chuyển quyền điều khiển sang agent khác |
Giúp đảm bảo rõ ràng từng phần trong quy trình được kiểm soát và có thể audit.
Trace & quan sát (theo dõi agent)
Sử dụng tính năng trace để theo dõi:
-
Agent nào đã làm gì?
-
Dùng công cụ nào?
-
Thời điểm bàn giao ra sao?
Điều này giúp kiểm tra và khôi phục lại hành vi nếu có sai sót.
Các kiểu Guardrails phổ biến
| Loại Guardrails | Mô tả |
|---|---|
| Ràng buộc logic | Nếu không hài lòng với kết quả, thử lại bằng công cụ khác |
| Luật đạo đức / an toàn | Không thảo luận về chủ đề nhạy cảm hoặc cá nhân hóa quá mức |
| Giới hạn hành động | Chỉ được phép gửi email sau khi kiểm tra toàn bộ tools |
| Theo dõi chi tiết (trace) | Kiểm tra lại toàn bộ hành trình trước khi gửi |
Bài học thực tế từ Sales Automation
Trong ví dụ "From Function Calls to Agent Autonomy":
-
AI sales manager được hướng dẫn cụ thể không tự tạo email.
-
AI phải dùng đủ 3 công cụ tạo email trước khi chọn cái tốt nhất.
-
Sau đó handoff sang Email Manager để gửi.
-
Mọi hành động đều được trace và kiểm soát.
→ Đây là mô hình agent có Guardrails rõ ràng.
Thực hành đề xuất
Bài tập 1: Xác định Guardrails trong đoạn sau
“"Bạn là Giám đốc bán hàng. Không bao giờ tự tạo email. Luôn sử dụng các công cụ được cung cấp."”
Câu hỏi:
-
Guardrails nào đang được áp dụng?
-
Mục tiêu của guardrails đó là gì?
Bài tập 2: Viết Guardrails cho Agent Tuyển dụng
Hãy viết các hướng dẫn guardrails cho một AI agent tuyển dụng, với các quy tắc như:
-
Luôn hỏi ứng viên 3 câu hỏi trước khi gửi thông tin cho quản lý
-
Không tự quyết định nhận ứng viên
Bài tập 3: Quan sát hành vi agent qua Trace
Dựa trên dữ liệu trace của ví dụ trên:
-
Agent nào thực hiện những bước nào?
-
Handoff xảy ra ở đâu?
-
Guardrails đã giúp kiểm soát hành vi nào?
Guardrails là linh hồn của hệ thống AI có trách nhiệm. Chúng:
Giữ AI hoạt động đúng vai trò
Tránh sai lệch, vi phạm đạo đức hoặc kỹ thuật
Tạo cơ sở để mở rộng agent một cách an toàn
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thực hành Xây dựng AI Agent “Sales Manager” với Guardrails
Mục tiêu:
-
Tạo một agent gửi email chào hàng tự động.
-
Ngăn chặn đầu vào chứa thông tin nhạy cảm như tên người thật (input guardrail).
-
Đảm bảo đầu ra không chứa cụm từ lỗi thời (output guardrail).
I. Cài đặt Môi trường
pip install langchain langchain-core openai guardrails-aiII. Cấu hình Guardrails
a. Input Guardrail – Kiểm tra Tên Riêng
Tạo file input_guardrail.xml:
<guardrail>
<input>
<validation name="no_personal_name" on_fail="exception">
<regex pattern="\b(Alice|Bob|Charlie|David)\b" match="false"/>
</validation>
</input>
</guardrail>Regex ở đây sẽ từ chối đầu vào có chứa các tên người thường gặp.
b. Output Guardrail – Chặn Từ Lỗi Thời
Tạo file output_guardrail.xml:
<guardrail>
<output>
<validation name="no_copyright" on_fail="exception">
<regex pattern="copyright 2023" match="false"/>
</validation>
</output>
</guardrail>III. Code Agent “Sales Manager”
Tạo file sales_manager.py:
from guardrails import Guard
from langchain.chat_models import ChatOpenAI
from langchain.schema import HumanMessage
# Load Guardrails
input_guard = Guard.from_rail("input_guardrail.xml")
output_guard = Guard.from_rail("output_guardrail.xml")
# Model
llm = ChatOpenAI(model="gpt-3.5-turbo")
def run_sales_email(prompt):
# Kiểm tra input
input_guard.validate(prompt)
# Sinh email
messages = [HumanMessage(content=prompt)]
response = llm(messages).content
# Kiểm tra output
output_guard.validate(response)
return response
# TEST 1 – Gây lỗi (Tên người thật)
try:
print("▶ Test 1 – Có tên thật")
prompt = "Viết email chào hàng gửi CEO từ Alice"
print(run_sales_email(prompt))
except Exception as e:
print("⛔ Guardrail kích hoạt:", e)
# TEST 2 – Thành công
try:
print("\n▶ Test 2 – Không có PII")
prompt = "Viết email chào hàng gửi CEO từ Trưởng phòng Kinh doanh"
print(run_sales_email(prompt))
except Exception as e:
print("⛔ Guardrail kích hoạt:", e)IV. Kết quả mong đợi
-
Test 1 sẽ bị từ chối, vì có tên thật “Alice” → input guardrail phát hiện.
-
Test 2 sẽ thành công, tạo ra email phù hợp → output guardrail không bị kích hoạt.
V. Mở rộng
-
Structured output (đầu ra có cấu trúc) là cách giúp mô hình AI trả về dữ liệu ở dạng JSON thay vì chỉ là một đoạn văn bản thuần túy. Điều này cực kỳ hữu ích trong các ứng dụng thực tế vì:
-
Bạn dễ dàng xử lý dữ liệu bằng code (Python, JS, v.v.).
-
Có thể hiển thị nội dung lên giao diện một cách có tổ chức.
-
Dễ dàng lưu vào cơ sở dữ liệu.
-
Mục tiêu
Tạo một AI Agent dạng Sales Manager, khi được yêu cầu viết email chào hàng, sẽ trả về dữ liệu JSON có cấu trúc như sau:
{
"subject": "Let's Talk About Increasing Your ROI",
"body": "Dear CEO, I hope this message finds you well...",
"signature": "Head of Business Development"
}
Cách làm: Dùng Pydantic + Output Parser
Langchain hỗ trợ xuất ra JSON theo schema định nghĩa bởi Pydantic.
Bước 1: Cài thư viện cần thiết
pip install langchain openai pydanticBước 2: Tạo Schema bằng Pydantic
from pydantic import BaseModel
class SalesEmail(BaseModel):
subject: str
body: str
signature: str
Bước 3: Dùng OutputFixingParser để ép LLM xuất JSON
from langchain.chat_models import ChatOpenAI
from langchain.output_parsers import PydanticOutputParser
from langchain.prompts import PromptTemplate
llm = ChatOpenAI(model="gpt-3.5-turbo", temperature=0)
# Khai báo parser
parser = PydanticOutputParser(pydantic_object=SalesEmail)
# Tạo prompt
prompt = PromptTemplate(
template="""Bạn là một chuyên gia viết email chào hàng. Viết một email theo định dạng JSON sau:
{format_instructions}
Thông tin:
- Gửi cho: CEO
- Người gửi: Trưởng phòng Kinh doanh
- Sản phẩm: Giải pháp tăng hiệu quả bán hàng
Bắt đầu viết email.
""",
input_variables=[],
partial_variables={"format_instructions": parser.get_format_instructions()}
)
# Gọi LLM
formatted_prompt = prompt.format()
output = llm.predict(formatted_prompt)
# Parse kết quả
email = parser.parse(output)
# In ra
print(email.json(indent=2))Kết quả mong đợi
{
"subject": "Giải pháp giúp CEO tăng hiệu quả bán hàng",
"body": "Kính gửi CEO, Chúng tôi xin giới thiệu...",
"signature": "Trưởng phòng Kinh doanh"
}
Giới Thiệu Dịch vụ web-search
web-search là một công cụ được OpenAI host sẵn (hosted tool), cho phép các AI Agent (assistant) tra cứu thông tin mới nhất từ internet trong thời gian thực. Nó giống như việc bạn tìm kiếm Google, nhưng do AI thực hiện thay bạn — và nó chỉ trả về phần thông tin cần thiết, được trích lọc và tóm tắt gọn gàng.
Cách hoạt động
-
Bạn (người dùng) nhập câu hỏi như:
→ "Tình hình kinh tế Việt Nam đầu năm 2025 như thế nào?" -
AI dùng công cụ
web-searchđể tìm kiếm thông tin mới nhất trên các trang báo, website uy tín. -
AI đọc, tóm tắt, tổng hợp và trả lời bạn như một chuyên gia.
Lợi ích của web-search
| Lợi ích | Mô tả |
|---|---|
| Cập nhật thời gian thực | Truy cập được thông tin mới nhất trên web (không bị giới hạn bởi kiến thức trước tháng 4/2023 như GPT-4 thường) |
| Tìm đúng nội dung cần thiết | Không phải đọc cả chục bài, AI sẽ trích phần liên quan và tóm tắt cho bạn |
| Tiết kiệm thời gian | Dùng AI thay thế việc bạn phải tìm đọc từng trang |
| Kết hợp tư duy AI | Không chỉ tìm, AI còn phân tích, so sánh, đánh giá nội dung giúp bạn hiểu sâu hơn |
| Tích hợp dễ dàng với Agent | Bạn không cần lập trình crawling, không cần API Google Search – chỉ cần khai báo "type": "web-search" là xong |
Ai nên dùng?
-
Nhà báo / Content writer: viết bài dựa trên thông tin mới
-
Sinh viên / học giả: nghiên cứu tài liệu gần đây
-
Doanh nghiệp: phân tích thị trường, theo dõi đối thủ
-
Developer: xây dựng các agent có năng lực tìm kiếm thông tin thực tế
Chi phí sử dụng
-
Mỗi lần AI gọi
web-searchsẽ tính phí khoảng 0.025 USD/lần tìm kiếm (tức khoảng 600đ) -
Bạn nên dùng khi cần thông tin cập nhật, tránh dùng cho kiến thức cơ bản đã có sẵn trong GPT
| Công cụ | Chức năng chính | Lợi ích khi sử dụng |
|---|---|---|
web-search |
Tìm kiếm thông tin từ Internet | Cập nhật thông tin mới nhất, thay thế Google Search |
code interpreter (tên mới: python) |
Chạy Python trực tiếp trong môi trường an toàn | Phân tích dữ liệu, xử lý file CSV, vẽ biểu đồ, giải toán, v.v. |
image generation (image_gen) |
Tạo hình ảnh từ mô tả văn bản (text-to-image) hoặc chỉnh sửa ảnh | Dùng cho thiết kế, ý tưởng sáng tạo, bản vẽ kỹ thuật, hình minh họa |
file upload (trực tiếp với GPT) |
Tải lên file (PDF, CSV, DOCX...) để AI đọc và phân tích | Trích xuất nội dung, so sánh tài liệu, tóm tắt nội dung file |
code editor (Canmore canvas) |
Chỉnh sửa mã nguồn hoặc văn bản dài với giao diện song song | Lập trình, sửa lỗi, viết tài liệu hoặc văn bản dài dễ dàng hơn |
browser (trước đây) |
Phiên bản cũ của web-search, nay đã thay thế bằng web-search |
❌ Không còn được dùng trực tiếp |
DALL·E Editor |
Vẽ hoặc sửa ảnh trực tiếp bằng AI với giao diện vùng chọn | Tạo ảnh nghệ thuật, mockup, biểu tượng, avatar |
Tạo Ứng Dụng Agent Tự Nghiên Cứu
Hôm nay, chúng ta sẽ xây dựng dự án lớn đầu tiên – một Deep Research Agent.
Đây là một trong những ứng dụng kinh điển của Agentic AI – nơi agent sẽ:
-
Tự động tìm kiếm thông tin trên Internet
-
Đọc các nguồn liên quan
-
Tổng hợp và tóm tắt thông tin
Mục tiêu của dự án
Tạo một AI Agent có khả năng:
-
Nhận một từ khóa nghiên cứu
-
Tìm kiếm trên web thông qua công cụ
web-searchđược OpenAI cung cấp -
Tổng hợp nội dung từ các nguồn
-
Trả về bản tóm tắt ngắn gọn (2–3 đoạn)
Công cụ cần chuẩn bị
-
Python 3.10+
-
Jupyter Notebook hoặc VSCode + extension Cursor
-
Tài khoản OpenAI có truy cập GPT-4 và hosted tools (web-search)
-
Thư viện
openai(v1.3+)
Cấu trúc dự án gợi ý
deep_research_agent/
├── .env
├── deep_research.ipynb
└── requirements.txt
1. Cài đặt môi trường
Tạo thư mục và cài thư viện
mkdir deep_research_agent
cd deep_research_agent
python -m venv venv
source venv/bin/activate # hoặc .\venv\Scripts\activate trên Windows
pip install openai python-dotenv jupyter
Tạo file requirements.txt
openai
python-dotenv
jupyter
2. Tạo file .env
Tạo file .env chứa API key của bạn:
OPENAI_API_KEY=sk-...3. Tạo Notebook deep_research.ipynb
Bạn có thể tạo một file notebook mới trong VSCode hoặc Jupyter. Dưới đây là nội dung gợi ý từng bước bạn cần triển khai:
4. Nội dung notebook (deep_research.ipynb)
🔹 Bước 1: Khởi tạo môi trường
import os
from dotenv import load_dotenv
import openai
load_dotenv()
openai.api_key = os.getenv("OPENAI_API_KEY")
🔹 Bước 2: Định nghĩa công cụ hosted (web search)
from openai import OpenAI
from openai.types.beta.threads import ToolAssistant
from openai.types.beta.tools import ToolChoice
client = OpenAI()
# Mô tả Search Agent
instructions = """
You are a research assistant.
Given a search term, you search the web for that term.
You produce a concise summary in 2–3 paragraphs, capturing the main points.
Write succinctly. No need for good grammar.
"""
tools = [{"type": "web-search"}] # Tool được OpenAI host
🔹 Bước 3: Tạo Assistant (Agent)
assistant = client.beta.assistants.create(
name="Search Agent",
instructions=instructions,
tools=tools,
model="gpt-4-turbo"
)
Bước 4: Tạo Thread, gửi yêu cầu tìm kiếm
thread = client.beta.threads.create()
user_input = "Latest AI agent frameworks in 2025"
# Thêm message
client.beta.threads.messages.create(
thread_id=thread.id,
role="user",
content=user_input
)
# Run với yêu cầu bắt buộc dùng web-search
run = client.beta.threads.runs.create(
thread_id=thread.id,
assistant_id=assistant.id,
tool_choice={"type": "required"},
model="gpt-4-turbo"
)
# Chờ chạy xong
import time
while True:
run_status = client.beta.threads.runs.retrieve(thread_id=thread.id, run_id=run.id)
if run_status.status in ["completed", "failed"]:
break
time.sleep(1)
# Lấy kết quả
messages = client.beta.threads.messages.list(thread_id=thread.id)
for msg in messages:
print(f"{msg.role}: {msg.content[0].text.value}")
Lưu ý về chi phí
-
Mỗi lần gọi
web-searchtool tốn 2.5 cent/lần -
Có thể giảm chi phí bằng cách chọn
search_context="low"nếu API hỗ trợ (đang thay đổi liên tục)
Xây dựng "Planner Agent" – Trợ lý lập kế hoạch tìm kiếm thông minh
Mục tiêu
Tạo một agent có khả năng phân tích câu hỏi đầu vào và đề xuất 3 truy vấn tìm kiếm web hợp lý để nghiên cứu sâu về chủ đề đó. Agent này sẽ không tìm kiếm mà chỉ đưa ra kế hoạch tìm kiếm.
Bước 1: Cài đặt thư viện cần thiết
pip install openai pydanticBước 2: Định nghĩa cấu trúc đầu ra
Sử dụng Pydantic để định nghĩa schema cho dữ liệu mà mô hình sẽ trả về.
from pydantic import BaseModel, Field
from typing import List
class WebSearchItem(BaseModel):
reason: str = Field(..., description="Lý do tại sao nên thực hiện truy vấn này.")
query: str = Field(..., description="Cụm từ khóa cần tìm kiếm trên internet.")
class WebSearchPlan(BaseModel):
searches: List[WebSearchItem] = Field(..., description="Danh sách các tìm kiếm để trả lời câu hỏi.")
Bước 3: Tạo prompt hướng dẫn hệ thống
SYSTEM_PROMPT = """
Bạn là một trợ lý nghiên cứu hữu ích.
Dựa trên một câu hỏi đầu vào, hãy đề xuất 3 truy vấn tìm kiếm trên web tốt nhất để trả lời câu hỏi đó.
Mỗi truy vấn cần bao gồm:
1. Lý do thực hiện truy vấn đó.
2. Cụm từ khóa cụ thể cần tìm kiếm.
Trả lời dưới dạng một đối tượng JSON có dạng:
{
"searches": [
{"reason": "...", "query": "..."},
{"reason": "...", "query": "..."},
{"reason": "...", "query": "..."}
]
}
"""
Bước 4: Gọi mô hình GPT để lập kế hoạch tìm kiếm
import openai
import json
openai.api_key = "YOUR_OPENAI_API_KEY" # Thay bằng API key của bạn
def generate_search_plan(question: str):
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Câu hỏi: {question}"}
],
temperature=0.7
)
content = response["choices"][0]["message"]["content"]
try:
# Chuyển JSON thành đối tượng WebSearchPlan
data = json.loads(content)
return WebSearchPlan(**data)
except Exception as e:
print("Lỗi khi phân tích phản hồi:", e)
print("Phản hồi thô:", content)
# Thử nghiệm
plan = generate_search_plan("Các framework AI phổ biến trong năm 2025 là gì?")
if plan:
for idx, item in enumerate(plan.searches, start=1):
print(f"\n🔍 Tìm kiếm #{idx}")
print(f"Lý do : {item.reason}")
print(f"Truy vấn: {item.query}")
Kết quả mong đợi
{
"searches": [
{
"reason": "Tìm hiểu các framework AI mới được giới thiệu năm 2025",
"query": "framework AI mới năm 2025"
},
{
"reason": "Phân tích các xu hướng ứng dụng AI trong ngành công nghiệp",
"query": "ứng dụng AI trong công nghiệp 2025"
},
{
"reason": "Tìm các công bố tại hội nghị AI hàng đầu năm 2025",
"query": "hội nghị AI công bố framework 2025"
}
]
}
Ghi nhớ
-
Đầu ra có cấu trúc giúp mô hình lập luận rõ ràng hơn (chain of thought).
-
Khi yêu cầu mô hình giải thích "lý do" trước khi trả lời, bạn sẽ nhận được câu trả lời chất lượng hơn.
-
Tất cả đầu ra thực chất là JSON, không có gì "ma thuật" cả.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Bài Thực Hành: "Trợ Lý Lập Kế Hoạch Marketing"
Mục tiêu
Xây dựng một agent AI có khả năng hiểu mục tiêu Marketing (ví dụ: ra mắt sản phẩm mới, tăng lượt đăng ký, nâng cao nhận diện thương hiệu, v.v...) và tự động đề xuất 3 hành động cụ thể mà team nên thực hiện, kèm lý do chiến lược cho từng hành động.
Tình huống
Team Marketing đưa vào một mục tiêu chiến dịch. AI agent sẽ trả về:
-
3 hành động gợi ý (ví dụ: viết bài blog, chạy quảng cáo TikTok, hợp tác với KOL, tổ chức webinar, v.v.)
-
Lý do vì sao nên làm hành động đó
-
Kênh thực hiện phù hợp
Bước 1: Định nghĩa cấu trúc dữ liệu
from pydantic import BaseModel, Field
from typing import List
class MarketingAction(BaseModel):
action: str = Field(..., description="Hành động cụ thể cần làm trong chiến dịch.")
reason: str = Field(..., description="Lý do chiến lược để thực hiện hành động này.")
channel: str = Field(..., description="Kênh thực hiện phù hợp (Facebook, TikTok, Blog, Email, v.v.)")
class MarketingPlan(BaseModel):
objective: str = Field(..., description="Mục tiêu chiến dịch marketing.")
actions: List[MarketingAction]
Bước 2: Prompt hệ thống
SYSTEM_PROMPT = """
Bạn là một chuyên gia Marketing.
Dựa trên một mục tiêu chiến dịch cụ thể, hãy gợi ý 3 hành động nên thực hiện trong chiến dịch marketing đó.
Với mỗi hành động, hãy chỉ rõ:
1. Hành động gì?
2. Lý do chiến lược.
3. Kênh thực hiện phù hợp.
Trả về dưới dạng JSON có cấu trúc như sau:
{
"objective": "...",
"actions": [
{"action": "...", "reason": "...", "channel": "..."},
{"action": "...", "reason": "...", "channel": "..."},
{"action": "...", "reason": "...", "channel": "..."}
]
}
"""
Bước 3: Hàm gọi GPT
import openai
import json
openai.api_key = "YOUR_OPENAI_API_KEY"
def generate_marketing_plan(objective: str):
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": f"Mục tiêu: {objective}"}
],
temperature=0.7
)
content = response["choices"][0]["message"]["content"]
try:
data = json.loads(content)
return MarketingPlan(**data)
except Exception as e:
print("Lỗi khi phân tích phản hồi:", e)
print("Phản hồi thô:", content)
Bước 4: Thử nghiệm
objective = "Tăng nhận diện thương hiệu cho sản phẩm chăm sóc da mới dành cho Gen Z"
plan = generate_marketing_plan(objective)
if plan:
print(f"\n🎯 Mục tiêu chiến dịch: {plan.objective}")
for idx, action in enumerate(plan.actions, start=1):
print(f"\n👉 Hành động #{idx}")
print(f"- Hành động : {action.action}")
print(f"- Lý do : {action.reason}")
print(f"- Kênh : {action.channel}")
Kết quả mong đợi (ví dụ)
{
"objective": "Tăng nhận diện thương hiệu cho sản phẩm chăm sóc da mới dành cho Gen Z",
"actions": [
{
"action": "Hợp tác với các beauty TikTokers nổi tiếng",
"reason": "Gen Z dành nhiều thời gian trên TikTok và bị ảnh hưởng bởi review chân thực từ KOL",
"channel": "TikTok"
},
{
"action": "Tổ chức mini game giveaway trên Instagram",
"reason": "Tạo hiệu ứng lan truyền và thu hút người dùng theo dõi fanpage",
"channel": "Instagram"
},
{
"action": "Viết bài blog chia sẻ bí quyết chăm sóc da tuổi teen",
"reason": "Nâng cao niềm tin và cung cấp giá trị hữu ích để thu hút khách hàng tiềm năng qua Google Search",
"channel": "Blog/SEO"
}
]
}
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
BÀI THỰC HÀNH: Xây dựng Deep Research Agent và gửi kết quả qua Email
Mục tiêu
Xây dựng một hệ thống gồm nhiều agents có thể thực hiện song song các tìm kiếm sâu (deep research), tổng hợp kết quả, và gửi email HTML chứa bản báo cáo chuyên sâu.
Công nghệ sử dụng
-
Python 3.10+
-
asyncio(chạy agents song song) -
OpenAI API (hoặc giả lập)
-
SMTP (gửi email)
-
rich(in log ra console đẹp) -
(Tuỳ chọn) LangChain / Guidance framework
Các thành phần
| Thành phần | Mô tả |
|---|---|
| Planner Agent | Nhận đầu vào là chủ đề nghiên cứu và chia thành nhiều truy vấn nhỏ |
| Search Agents (n) | Thực hiện các tìm kiếm song song theo truy vấn được giao |
| Writer Agent | Tổng hợp kết quả từ các search agents và viết báo cáo HTML |
| Email Agent | Gửi báo cáo qua email HTML đến người nhận |
Bước 1: Cài đặt cấu trúc project
deep_research_agent/
├── agents/
│ ├── planner.py
│ ├── search_agent.py
│ ├── writer.py
│ └── email_agent.py
├── main.py
├── utils.py
├── .env
└── requirements.txt
Bước 2: Cấu hình file .env
OPENAI_API_KEY=sk-...
EMAIL_HOST=smtp.gmail.com
EMAIL_PORT=587
EMAIL_HOST_USER=your_email@gmail.com
EMAIL_HOST_PASSWORD=your_app_password
RECEIVER_EMAIL=receiver@example.com
Bước 3: Viết từng agent
planner.py
async def planner(topic: str, num_tasks: int = 5) -> list[str]:
return [f"{topic} - góc nhìn {i+1}" for i in range(num_tasks)]
search_agent.py
import asyncio
async def search(query: str) -> str:
await asyncio.sleep(1) # giả lập thời gian tìm kiếm
return f"Kết quả cho: {query}"
writer.py
def write_report(results: list[str], topic: str) -> str:
html = f"<h1>Báo cáo về: {topic}</h1><ul>"
for r in results:
html += f"<li>{r}</li>"
html += "</ul><p><strong>Kết luận:</strong> Báo cáo này dựa trên {len(results)} truy vấn.</p>"
return html
email_agent.py
import smtplib
from email.mime.multipart import MIMEMultipart
from email.mime.text import MIMEText
import os
def send_email(subject: str, html: str):
msg = MIMEMultipart()
msg['From'] = os.getenv("EMAIL_HOST_USER")
msg['To'] = os.getenv("RECEIVER_EMAIL")
msg['Subject'] = subject
msg.attach(MIMEText(html, 'html'))
server = smtplib.SMTP(os.getenv("EMAIL_HOST"), int(os.getenv("EMAIL_PORT")))
server.starttls()
server.login(os.getenv("EMAIL_HOST_USER"), os.getenv("EMAIL_HOST_PASSWORD"))
server.send_message(msg)
server.quit()
Bước 4: main.py
import asyncio
from agents.planner import planner
from agents.search_agent import search
from agents.writer import write_report
from agents.email_agent import send_email
async def main():
topic = "Ứng dụng AI trong marketing"
queries = await planner(topic, num_tasks=10)
tasks = [search(q) for q in queries]
results = await asyncio.gather(*tasks)
report_html = write_report(results, topic)
send_email(subject=f"[Báo cáo] {topic}", html=report_html)
print("✅ Email đã được gửi!")
if __name__ == "__main__":
asyncio.run(main())
Mục tiêu học viên đạt được
-
Hiểu cách tổ chức một hệ thống nhiều agents (planner → search → writer → email)
-
Thực hành
asyncio.gather()để chạy nhiều agents song song -
Tạo báo cáo HTML tự động
-
Gửi email chuyên sâu theo mô hình tự động
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft