RAG - AI THỰC CHIẾN: TỪ LÝ THUYẾT ĐẾN HỆ THỐNG THÔNG MINH
Không phải AI thay thế bạn—mà là người dùng AI sẽ thay thế người không dùng AI."
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
- Giới thiệu
- Cơ sở của Hệ thống Truy xuất(Retrieval system)
- Giới thiệu
- Truy vấn Thông tin (Information Retrieval - IR) - Nền tảng của Hệ thống Tìm kiếm và AI
- Từ dừng(Stopwords) và Rút gọn từ về gốc(stemming)
- RAG (Retrieval-Augmented Generation)
- Tokenization (Tách Từ) - Nền Tảng Xử Lý Ngôn Ngữ Tự Nhiên (NLP)
- Hiểu cách hoạt động của Vector Space Model (VSM)
- Tầm quan trọng của TF-IDF trong xử lý ngôn ngữ tự nhiên (NLP)
- Mô Hình Truy Xuất Thông Tin Boolean (Boolean Retrieval Model)
- Thực hành Python: Mô hình Boolean Retrieval
- Mô hình truy xuất xác suất(Probabilistic Retrieval Model)
- LongRAG và LightRAG
- Bài Thực Hành LongRAG: Truy Vấn Thông Minh Trên Tài Liệu Dài
- OpenAI API
- Giới thiệu
- OpenAI API for Text
- Tùy chỉnh đầu ra bằng các tham số trong OpenAI API
- Sử Dụng OpenAI API Để Hiểu, Phân Tích Và Mô Tả Hình Ảnh
- LongRAG và LightRAG – Hai bước tiến mới trong hệ thống RAG
- Tự động hóa thực đơn với AI
- RAG với các Models OpenAI GPT
- Giới thiệu
- Case Study – Ứng dụng RAG vào Sách Dạy Nấu Ăn
- Hướng dẫn Xây dựng Hệ Thống RAG sử dụng OpenAI với PDF
- RAG với dữ liệu phi cấu trúc
- Khai phá dữ liệu phi cấu trúc với Retrieval-Augmented Generation (RAG)
- Giới thiệu về Thư viện LangChain – Chìa khóa để xử lý dữ liệu phi cấu trúc
- Xử lý File Excel Không Cấu Trúc với LangChain
- Thiết lập môi trường xử lý dữ liệu không có cấu trúc với LangChain
- Đọc và xử lý dữ liệu Excel với LangChain
- Xây dựng Hệ thống Truy xuất Thông tin với LangChain + OpenAI
- Xây dựng hệ thống RAG với LangChain và OpenAI
- Fine-Tuning
- Fine-Tuning là gì
- Transformers
- Fine-Tuning trong hệ thống RAG
- Dự án RAG Retriever + Generator Fine-Tuning
- Flan-T5
- Flan-T5 với RAG
- Các công cụ
- LangSmith, Promptfoo, và TruLens
- Hugging Face Transformers, PEFT, LoRA, và QLoRA
- Thực hành LangSmith
- Bài thực hành Promptfoo cơ bản
- Bài Thực Hành: Đánh Giá Hệ Thống RAG với TruLens và LangChain
- Bài thực hành PEFT: Phân loại phản hồi khách hàng (Feedback)
- Unit Test
Giới thiệu
AI không phải phép thuật—mà là công cụ mạnh mẽ. Dùng đúng cách, nó sẽ thúc đẩy doanh nghiệp của bạn và mở khóa tiềm năng tăng trưởng.
Bạn đã nghe đủ những lời hoa mỹ về AI? Đã đến lúc tiếp cận Retrieval-Augmented Generation (RAG) một cách thực tế—không hoa mỹ, chỉ có kiến thức ứng dụng ngay. Cuốn sách này sẽ giúp bạn:
Biến AI thành đối tác làm việc thực thụ
-
Tự động hóa + Tăng cường: Kết hợp sức mạnh truy vấn thông minh (Retrieval) và khả năng sáng tạo của GenAI (Generation) để xây dựng hệ thống AI linh hoạt, chính xác và gần gũi với con người.
-
Học qua thực hành: Bài tập , case study thực tế, và capstone project giúp bạn vừa học vừa làm, tự tin ứng dụng ngay.
NỘI DUNG NỔI BẬT
1. Làm chủ nền tảng Retrieval
-
Hiểu sâu về Information Retrieval (IR) và cách triển khai các mô hình truy xuất dữ liệu.
2. Xây dựng mô hình Text Generation đỉnh cao
-
Kiến trúc Deep Learning, Transformer & cơ chế Attention - nền tảng của ChatGPT hay Gemini.
3. Tích hợp OpenAI API vào RAG
-
Khai thác API cho text/image generation, embedding, và thiết kế hệ thống retrieval với metadata.
4. Phát triển & tối ưu hệ thống RAG
-
Kết hợp retrieval và generative models để AI của bạn thông minh hơn, ít "ảo giác" hơn.
5. Xử lý đa dạng dữ liệu
-
PDF, DOCX, PPT, EPUB - biến AI thành "chuyên gia" đọc hiểu mọi định dạng.
6. Thiết kế Agentic RAG tương tác
-
Tạo AI agent có memory, state, và khả năng giao tiếp như một trợ lý ảo.
7. Case study ứng dụng thực tế
-
Phân tích phản hồi khách hàng, báo cáo tài chính (ví dụ: Starbucks), và hệ thống hỗ trợ ra quyết định.
8. Cập nhật nghiên cứu khoa học mới nhất
-
Những breakthrough trong RAG và xu hướng AI toàn cầu.
9. Capstone Project
-
Xây dựng GenAI cho chiến dịch marketing hoặc hệ thống Business Intelligence đa phương tiện.
AI đang định hình lại mọi ngành nghề—đừng bị bỏ lại phía sau!
Cuốn sách này giúp bạn:
-
Tư duy khác biệt: Dám thử nghiệm
Dành cho:
-
Kỹ sư AI/ML muốn master RAG.
-
Product Manager tìm giải pháp AI cho doanh nghiệp.
-
Bất kỳ ai đam mê GenAI và muốn tạo ra sản phẩm "đáng dùng".
"Không phải AI thay thế bạn—mà là người dùng AI sẽ thay thế người không dùng AI."
Sẵn sàng biến RAG thành "superpower" tiếp theo của bạn?
Cơ sở của Hệ thống Truy xuất(Retrieval system)
-
Cơ chế tìm kiếm, truy xuất dữ liệu liên quan đến một truy vấn người dùng (text, hình ảnh, v.v.).
-
Các hệ thống như search engines, document retrieval, question answering…
-
nói về những hệ thống AI như ChatGPT + tìm kiếm dữ liệu, thì "Hệ thống Truy xuất" ở đây ám chỉ kiến trúc Retrieval-Augmented Generation, một dạng mô hình kết hợp:
-
Retrieval module (phần truy xuất)
-
Generation module (phần sinh nội dung)
-
Giới thiệu
Bạn tò mò về "phép thuật" đằng sau những kết quả tìm kiếm? Phần này sẽ bật mí tất cả.
Chúng ta sẽ học nguyên lý cơ bản của hệ thống truy vấn và hiểu cách các công cụ tìm kiếm hoạt động.
Bạn sẽ nắm vững những kỹ thuật then chốt—những kỹ năng tưởng chừng chỉ dành cho chuyên gia.
1. Tokenization & Tiền Xử Lý Dữ Liệu
-
Tokenization: Bước đầu tiên để xử lý dữ liệu văn bản.
-
Thực hành các kỹ thuật tiền xử lý, đảm bảo dữ liệu sẵn sàng cho phân tích.
2. Xây Dựng Các Loại Hệ Thống Truy Vấn
-
Hệ thống Boolean: Sử dụng AND, OR, NOT.
-
Mô hình Không Gian Vector (VSM): Ứng dụng TF-IDF.
-
Mô hình Xác Suất Truy Vấn.
3. Truy Vấn & Xếp Hạng Kết Quả
-
Yếu tố then chốt để trả về kết quả tìm kiếm chất lượng cao.
4. Kỹ Năng Lập Trình Thực Tế
-
Tokenize và tiền xử lý văn bản.
-
Xây dựng & truy vấn inverted index (chỉ mục ngược).
-
Áp dụng các mô hình truy vấn.
Bạn sẽ đạt được
-
Thành thạo tokenization & tiền xử lý.
-
Hiểu sâu các mô hình: Boolean, Vector Space, Xác suất.
-
Tự tin xây dựng và truy vấn inverted index.
-
Kinh nghiệm lập trình ứng dụng ngay.
Truy vấn Thông tin (Information Retrieval - IR) - Nền tảng của Hệ thống Tìm kiếm và AI
IR là gì? Tại sao nó quan trọng?
Trong bài này, bạn sẽ hiểu rõ Information Retrieval (IR) và tầm quan trọng của nó trong thời đại AI và Big Data.
IR là quá trình tìm kiếm thông tin liên quan trong một tập dữ liệu lớn dựa trên truy vấn của người dùng.
-
Khi bạn tìm kiếm trên Google, IR chính là công nghệ đằng sau việc trả về các trang web phù hợp.
-
Ví dụ: Bạn gõ "VHTsoft công ty công nghệ", hệ thống sẽ quét qua hàng tỷ trang, lọc và trả về kết quả chính xác nhất.
Các thành phần chính của IR
1. Indexing (Lập chỉ mục)
-
Xây dựng một "danh mục" thông minh bằng cách phân tách văn bản thành các từ khóa (token) và lưu trữ chúng dưới dạng dễ tìm kiếm.
-
Giống như thư viện: Mỗi cuốn sách được gắn nhãn (tag) để tra cứu nhanh.
2. Querying (Truy vấn)
-
Tìm kiếm thông tin dựa trên đầu vào người dùng.
-
Ví dụ: Bạn hỏi trợ lý ảo "Cách triển khai RAG", nó sẽ tra cứu chỉ mục và trả về tài liệu phù hợp.
3. Ranking (Xếp hạng)
-
Sắp xếp kết quả theo độ liên quan, đảm bảo thông tin hữu ích nhất hiển thị đầu tiên.
-
Giống như thủ thư đặt sách phù hợp nhất lên trên cùng khi bạn hỏi về một chủ đề.
Cách hoạt động của hệ thống IR
-
Thu thập dữ liệu (Crawling) – Quét website, tài liệu, database.
-
Tiền xử lý (Tokenization, loại bỏ stopwords, stemming).
-
Lập chỉ mục (Xây dựng inverted index để tìm kiếm nhanh).
-
Xử lý truy vấn (Phân tích câu hỏi người dùng).
-
Xếp hạng kết quả (Dùng TF-IDF, BM25, hoặc AI để đánh giá độ phù hợp).
Ứng dụng thực tế của IR
-
Công cụ tìm kiếm (Google, Bing).
-
Thư viện số (Google Scholar, PDF databases).
-
E-commerce (Tìm kiếm sản phẩm trên Amazon, Shopee).
-
Mạng xã hội (Facebook, Twitter search).
-
Trợ lý ảo (Siri, Alexa dùng IR để trả lời câu hỏi).
Vai trò của IR trong AI & Data Science
-
Là nền tảng của RAG (Retrieval-Augmented Generation), giúp AI truy xuất thông tin chính xác trước khi trả lời.
-
Xử lý ngôn ngữ tự nhiên (NLP): IR giúp chatbot, search engine hiểu ngữ cảnh tốt hơn.
-
Big Data: IR tối ưu hóa việc tìm kiếm trong dataset khổng lồ.
"Không có IR, AI sẽ chỉ là một cỗ máy 'đoán mò' thay vì đưa ra câu trả lời chính xác."
IR không chỉ là công nghệ cốt lõi của Google mà còn là "xương sống" của các hệ thống AI hiện đại. Hiểu IR giúp bạn xây dựng công cụ tìm kiếm thông minh, chatbot chính xác và hệ thống phân tích dữ liệu mạnh mẽ.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Từ dừng(Stopwords) và Rút gọn từ về gốc(stemming)
Stopwords và stemming – hai bước rất quan trọng trong quá trình tiền xử lý văn bản trong lĩnh vực Xử lý ngôn ngữ tự nhiên (NLP):
Từ dừng(Stopwords)
Là gì?
Stopwords là những từ rất phổ biến trong ngôn ngữ nhưng ít mang ý nghĩa nội dung khi phân tích, ví dụ như:
| Tiếng Việt | Tiếng Anh |
|---|---|
| "là", "của", "và", "những", "đã", "đang", "sẽ", "tôi", "anh", "chị", "một", "này", "kia", "đó", "với"... | is, the, a, an, in, at, of, with, was... |
Tại sao cần loại bỏ?
-
Giúp giảm nhiễu khi phân tích nội dung.
-
Tiết kiệm tài nguyên xử lý (bộ nhớ, thời gian).
-
Tập trung vào từ khóa mang ý nghĩa chính.
Ví dụ 1:
Câu gốc:
"Tôi đang học lập trình với Python tại trường đại học."
Các stopwords:
"Tôi", "đang", "với", "tại"
Sau khi loại bỏ stopwords:
"học lập trình Python trường đại học"
➡ Kết quả giúp mô hình NLP tập trung vào từ khóa chính.
Ví dụ 2:
Câu gốc:
"Anh ấy đã mua một chiếc xe mới vào hôm qua."
Stopwords loại bỏ:
"Anh ấy", "đã", "một", "vào"
Kết quả:
"mua chiếc xe mới hôm qua"
Rút gọn từ về gốc(Stemming)
Là gì?
Stemming giúp đưa các từ về gốc từ bằng cách cắt bỏ tiền tố, hậu tố.
Với tiếng Việt, điều này phức tạp hơn tiếng Anh do từ có thể mang nhiều thành phần.
Ví dụ tiếng Anh:
| Từ gốc (Stem) | Từ biến thể |
|---|---|
| run | running, runs, ran |
| connect | connected, connecting |
| develop | developing, developed |
Tất cả sẽ được đưa về từ gốc: run, connect, develop.
Ví dụ 1:
Các từ biến thể:
"học", "học sinh", "học tập", "học hành", "học hỏi"
Stem (từ gốc):
"học"
Giải thích:
-
"học sinh" → người đi học
-
"học tập", "học hành", "học hỏi" → các biến thể của hành động "học"
➡ Khi phân tích nội dung, ta có thể gom các từ này về cùng một chủ đề: “học”
Ví dụ 2:
Câu gốc:
"Người lao động đang làm việc chăm chỉ để hoàn thành dự án."
Các từ cần stem:
-
"lao động" → "lao động" (giữ nguyên)
-
"làm việc" → "làm"
-
"hoàn thành" → "thành"
Kết quả sau khi stemming:
"người lao động làm chăm chỉ thành dự án"
➡ Có thể không tự nhiên trong văn nói, nhưng rất hữu ích cho phân loại văn bản, tìm kiếm hoặc phân tích ngữ nghĩa.
Công cụ phổ biến:
-
Porter Stemmer(tiếng Anh) -
Snowball Stemmer -
Với tiếng Việt: công cụ VnCoreNLP,
pyvi,underthesea,...
Ví dụ tiếng Việt:
Câu: "Học sinh đang học bài học mới."
→ Sau stemming: "học sinh học bài học mới"
(Từ "học" được giữ nguyên; "học sinh" và "bài học" không cần tách vì vẫn giữ nghĩa)
Tổng kết mối quan hệ:
| Kỹ thuật | Mục đích | Kết quả |
|---|---|---|
| Tokenization | Tách văn bản thành từ/token | ["Tôi", "đã", "đi", "đến"...] |
| Stopword Removal | Loại bỏ từ phổ biến không cần | ["Tôi", "đi", "trường", "sáng"] |
| Stemming | Đưa từ về gốc | ["Tôi", "đi", "trường", "sáng"] (hoặc gốc thêm nếu có) |
Dùng thư viện xử lý ngôn ngữ tự nhiên (NLP)
Ví dụ bằng Python + thư viện Underthesea
from underthesea import word_tokenize
# Câu ví dụ
sentence = "Tôi đang học lập trình Python tại trường đại học."
# Tách từ
words = word_tokenize(sentence, format="text")
print("Các từ trong câu:", words)
Loại bỏ stopwords thủ công:
stopwords = ["tôi", "đang", "tại", "là", "và", "của", "một", "những", "này", "đó"]
filtered_words = [word for word in words.split() if word.lower() not in stopwords]
print("Sau khi loại bỏ stopwords:", filtered_words)Ví dụ nhận diện stemming (rút gọn từ)
words = ["học", "học sinh", "học tập", "học hành", "học hỏi"]
stem = "học"
for word in words:
if word.startswith(stem):
print(f"Từ '{word}' có thể được quy về gốc '{stem}'")Nhận biết thủ công (khi không dùng code)
-
Với stopwords: Tìm các từ quá phổ biến, không mang nhiều nội dung riêng biệt.
Ví dụ: "và", "là", "của", "một", "đã", "đang", "với", "cho", "như", "này", "kia"... -
Với stemming: Tìm các từ liên quan đến cùng một gốc từ, dù khác nhau về hậu tố hoặc dạng sử dụng.
Ví dụ: "chơi", "chơi đùa", "chơi game", "chơi thể thao" → chung một gốc là "chơi"
Một số công cụ gợi ý
| Công cụ | Tính năng chính | Ngôn ngữ |
|---|---|---|
| Underthesea | Tách từ, POS tagging, nhận diện từ gốc | Tiếng Việt |
| VnCoreNLP | Tách từ, phân tích ngữ pháp, NER | Tiếng Việt |
| spaCy + pyvi | Kết hợp để xử lý văn bản tiếng Việt | Tiếng Việt |
| NLTK | Hỗ trợ stopwords tiếng Anh mạnh mẽ | Tiếng Anh |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
RAG (Retrieval-Augmented Generation)
Hãy cùng tìm hiểu chi tiết về RAG (Retrieval-Augmented Generation) — một kỹ thuật rất quan trọng trong việc xây dựng hệ thống AI có khả năng trả lời chính xác dựa trên kiến thức bên ngoài, ví dụ như tài liệu nội bộ, cơ sở tri thức công ty, v.v.
1. RAG là gì?
RAG (Retrieval-Augmented Generation) là một kiến trúc kết hợp giữa hai thành phần:
-
Retrieval (Truy xuất)
→ Truy vấn và tìm kiếm thông tin phù hợp từ cơ sở dữ liệu, tài liệu, văn bản, v.v. -
Generation (Sinh văn bản)
→ Dựa vào thông tin đã truy xuất, mô hình ngôn ngữ (LLM như GPT) sẽ sinh ra câu trả lời tự nhiên và có ngữ cảnh.
Mục tiêu: Giúp mô hình trả lời chính xác và theo ngữ cảnh cụ thể, thay vì chỉ dựa vào kiến thức đã được huấn luyện từ trước.
2. Tại sao cần RAG?
Mô hình LLM như GPT có hạn chế:
-
Không biết thông tin mới hoặc riêng biệt (ví dụ: chính sách nội bộ, hướng dẫn sử dụng của công ty).
-
Dễ “bịa ra” câu trả lời khi không chắc chắn.
RAG khắc phục điều đó bằng cách thêm một bước tìm kiếm thông tin thật, rồi mới trả lời.
3. Quy trình hoạt động của RAG
[Câu hỏi người dùng]
↓
[1] Truy vấn → Tìm văn bản liên quan trong cơ sở dữ liệu
↓
[2] Sinh → Đưa thông tin tìm được vào prompt → Mô hình tạo câu trả lời
↓
[Trả lời chính xác và rõ ràng]4. Ví dụ cụ thể về RAG
Tình huống:
Bạn có một tài liệu nội bộ hướng dẫn sử dụng phần mềm quản lý kho. Người dùng hỏi:
"Làm sao để kiểm kê tồn kho định kỳ?"
Bước 1: Truy xuất tài liệu liên quan
-
Hệ thống tìm được đoạn văn bản trong tài liệu có nội dung:
"Để kiểm kê tồn kho định kỳ, người quản lý cần truy cập vào module 'Báo cáo kho', chọn chức năng 'Kiểm kê', và thực hiện quy trình đếm thực tế, sau đó đối chiếu với hệ thống."
Bước 2: Sinh câu trả lời tự nhiên
Mô hình được "bơm" đoạn tài liệu vào prompt, và trả lời:
"Để kiểm kê tồn kho định kỳ, bạn hãy vào module 'Báo cáo kho', sau đó chọn 'Kiểm kê'. Thực hiện đếm hàng hóa thực tế, nhập số liệu và hệ thống sẽ đối chiếu với tồn kho ghi nhận trong phần mềm."
Đây là câu trả lời sinh ra từ mô hình nhưng có nội dung chính xác, không bịa đặt, vì dựa trên văn bản có thật.
5. Các công cụ/công nghệ để triển khai RAG
| Thành phần | Công cụ phổ biến |
|---|---|
| Truy xuất dữ liệu | FAISS, Weaviate, Elasticsearch |
| Tách đoạn văn | LangChain, Haystack |
| LLM trả lời | GPT-4, Claude, Mistral, LLaMA, v.v. |
| Framework RAG | LangChain, LlamaIndex, Haystack |
6. Một số ứng dụng thực tế của RAG
| Ứng dụng | Mô tả |
|---|---|
| Hỗ trợ khách hàng (chatbot) | Trả lời câu hỏi từ khách dựa trên tài liệu công ty |
| Trợ lý tài liệu kỹ thuật | Giải thích hướng dẫn sử dụng, quy trình phức tạp |
| Tìm kiếm có ngữ cảnh | Cải thiện kết quả tìm kiếm với câu trả lời sinh ngôn ngữ tự nhiên |
| Tóm tắt báo cáo dài | Tìm đoạn liên quan rồi tóm tắt hoặc giải thích cho người dùng |
Tóm tắt
| Mục | Nội dung |
|---|---|
| 🔹 RAG là gì? | Kết hợp tìm kiếm thông tin và sinh văn bản |
| 🔹 Lợi ích | Trả lời chính xác, cập nhật, không bịa |
| 🔹 Hoạt động | Truy xuất → Tạo câu trả lời |
| 🔹 Công cụ | LangChain, FAISS, GPT, Haystack |
| 🔹 Ứng dụng | Trợ lý nội bộ, chatbot thông minh, tìm kiếm nâng cao |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tokenization (Tách Từ) - Nền Tảng Xử Lý Ngôn Ngữ Tự Nhiên (NLP)
Tokenization là gì?
Tokenization là quá trình chia nhỏ văn bản thành các đơn vị nhỏ hơn như từ, cụm từ hoặc câu, gọi là token.
Ví dụ:
"VHTSoft is a technology company"
→ Tokens:["VHTSoft", "is", "a", "technology", "company"]
Tưởng tượng tokenization giống như việc cắt một cuốn sách thành từng từ riêng lẻ hoặc tách các câu—đây là bước cực kỳ quan trọng trong NLP và Hệ thống Truy vấn Thông tin (IR).
Tại sao Tokenization quan trọng?
-
Đơn giản hóa xử lý văn bản
-
Biến dữ liệu thô thành các phần nhỏ, dễ phân tích.
-
-
Hỗ trợ đánh chỉ mục (indexing)
-
Giúp tìm kiếm và truy xuất thông tin nhanh hơn (vd: search engine).
-
-
Làm sạch dữ liệu
-
Loại bỏ stopwords (từ không quan trọng như "a", "the"), chuẩn hóa văn bản.
-
-
Giúp AI hiểu ngữ nghĩa
-
Là đầu vào cho các mô hình NLP như BERT, GPT.
-
1. Word Tokenization (Tách từ)
-
Chia văn bản thành các từ riêng lẻ.
-
Ví dụ:
"Học máy rất thú vị" →
["Học", "máy", "rất", "thú", "vị"]
2. Sentence Tokenization (Tách câu)
-
Chia văn bản thành các câu.
-
Ví dụ:
"Tôi thích AI. Tôi học NLP." →
["Tôi thích AI.", "Tôi học NLP."]
3. Character Tokenization (Tách ký tự)
-
Chia văn bản thành từng ký tự.
-
Ví dụ:
"AI" →
["A", "I"]
Thách Thức Khi Tokenization
-
Xử lý dấu câu: Dấu chấm, phẩy có nên là token riêng?
-
Từ ghép: "ice-cream", "mother-in-law"—nên tách hay giữ nguyên?
-
Ký tự đặc biệt: Emoji, hashtag (#AI), URL.
-
Đa ngôn ngữ:
-
Tiếng Việt: "Xin chào" →
["Xin", "chào"] -
Tiếng Anh: "Hello" →
["Hello"] -
Tiếng Nhật: *"こんにちは"` (không có khoảng cách giữa từ).
-
Triển Khai Tokenization Trong Python
Sử dụng thư viện NLTK (Natural Language Toolkit):
import nltk
nltk.download('punkt') # Tải dữ liệu tokenizer
# Word Tokenization
from nltk.tokenize import word_tokenize
text = "VHTSoft is a technology company"
tokens = word_tokenize(text)
print("Word Tokens:", tokens) # Output: ['VHTSoft', 'is', 'a', 'technology', 'company']
# Sentence Tokenization
from nltk.tokenize import sent_tokenize
text = "I love AI. I study NLP."
sentences = sent_tokenize(text)
print("Sentence Tokens:", sentences) # Output: ['I love AI.', 'I study NLP.']Tiền Xử Lý Văn Bản(TextPreprocessing)
Sau khi tokenization, bước tiếp theo là chuẩn hóa văn bản bằng cách:
-
Chuyển thành chữ thường (lowercase)
-
Loại bỏ các token không phải chữ và số (non-alphanumeric)
Triển Khai Preprocessing Trong Python
import re
from nltk.tokenize import word_tokenize
def preprocess(text):
# 1. Chuyển thành chữ thường
text = text.lower()
# 2. Tokenization
tokens = word_tokenize(text)
# 3. Loại bỏ token không phải chữ/số (giữ lại từ có dấu)
tokens = [token for token in tokens if re.match(r'^[a-z0-9áàảãạăắằẳẵặâấầẩẫậéèẻẽẹêếềểễệóòỏõọôốồổỗộơớờởỡợíìỉĩịúùủũụưứừửữựýỳỷỹỵđ]+$', token)]
return tokens
# Ví dụ các tài liệu
documents = [
"VHTSoft is a TECHNOLOGY company!",
"AI, Machine Learning & NLP are COOL.",
"Xử lý ngôn ngữ tự nhiên (NLP) rất quan trọng!"
]
# Tiền xử lý từng tài liệu
preprocessed_docs = [' '.join(preprocess(doc)) for doc in documents]
# Kết quả
for i, doc in enumerate(preprocessed_docs):
print(f"Document {i+1}: {doc}")
Kết Quả Sẽ Là:
Document 1: vhtsoft is a technology company
Document 2: ai machine learning nlp are cool
Document 3: xử lý ngôn ngữ tự nhiên nlp rất quan trọngGiải Thích:
-
text.lower(): Chuyển tất cả thành chữ thường để đồng nhất hóa. -
re.match(): Chỉ giữ lại token chứa chữ cái (kể cả tiếng Việt), số. -
' '.join(): Ghép các token lại thành câu sau khi xử lý.
Mẹo Thực Tế Để Tokenization Hiệu Quả
Dù đơn giản, tokenization là bước cực kỳ quan trọng để phân tích dữ liệu văn bản và tạo nền tảng cho các tác vụ NLP nâng cao. Dưới đây là những lời khuyên thiết thực:
1. Tiền Xử Lý Văn Bản (Preprocess Text)
-
Chuẩn hóa dữ liệu trước khi tokenize:
-
Chuyển thành chữ thường (
lowercase). -
Loại bỏ ký tự đặc biệt (như
!?, @), nhưng giữ lại từ có dấu (tiếng Việt). -
Xử lý viết tắt (vd: "ko" → "không").
-
-
Ví dụ:
text = "Tokenization là BƯỚC ĐẦU!!!"
text = text.lower() # "tokenization là bước đầu!!!"2. Xử Lý từ không mang nhiều ý nghĩa(Stopwords) (Handle Stopwords)
-
Stopwords là những từ ít mang nghĩa (vd: "và", "là", "the").
-
Nên loại bỏ chúng để giảm nhiễu, nhưng cẩn thận với ngữ cảnh:
-
Tiếng Việt: "không tốt" → Nếu xóa "không", nghĩa đảo ngược!
-
-
Cách làm:
- Tùy chỉnh danh sách stopwords để giữ lại từ như:
-
stopwords = [...] # danh sách từ dừng mặc định important_words = ['không', 'chưa', 'chẳng', 'chả', 'đừng'] # Loại bỏ các từ phủ định khỏi stopwords stopwords = [word for word in stopwords if word not in important_words] -
Dùng mô hình học sâu hiểu ngữ cảnh (BERT tiếng Việt)
Mô hình như PhoBERT, viBERT, hoặc VietAI-BERT đã được huấn luyện để hiểu từ phủ định theo ngữ cảnh, không cần xử lý thủ công.
Khi Nào Dùng Tokenization?
-
Xây dựng chatbot, search engine.
-
Phân tích cảm xúc (sentiment analysis).
-
Xử lý dữ liệu trước khi đưa vào AI model.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Hiểu cách hoạt động của Vector Space Model (VSM)
1. Mục tiêu bài học
Sau bài học này, bạn sẽ:
-
Hiểu được khái niệm Vector Space Model (VSM).
-
Biết cách biểu diễn văn bản dưới dạng vector.
-
Hiểu được cách đo lường độ tương đồng giữa văn bản và truy vấn.
-
Thực hành với ví dụ minh họa đơn giản bằng tiếng Việt.
2. VSM là gì?
VSM (Vector Space Model) là một mô hình toán học dùng để:
-
Biểu diễn văn bản dưới dạng vector trong không gian nhiều chiều.
-
So sánh sự tương đồng giữa các văn bản hoặc giữa truy vấn người dùng và tài liệu.
Mỗi từ (hoặc từ gốc) sẽ là một chiều trong không gian vector, còn mỗi văn bản sẽ là một điểm trong không gian đó.
3. Cách biểu diễn văn bản bằng VSM
Các bước:
-
Tiền xử lý văn bản:
-
Chuyển về chữ thường, loại bỏ dấu câu, stopwords, v.v.
-
-
Tách từ (tokenize).
-
Tạo tập từ vựng (vocabulary).
-
Biểu diễn văn bản dưới dạng vector (dựa trên tần suất xuất hiện từ).
Ví dụ minh họa
Tài liệu 1:
Tôi thích ăn phở bò
Tài liệu 2:
Tôi ăn phở gà vào buổi sáng
Truy vấn:
Tôi muốn ăn phở
Tập từ vựng (Vocabulary):
["tôi", "thích", "ăn", "phở", "bò", "gà", "vào", "buổi", "sáng", "muốn"]Vector hóa:
| Từ | Tài liệu 1 | Tài liệu 2 | Truy vấn |
|---|---|---|---|
| tôi | 1 | 1 | 1 |
| thích | 1 | 0 | 0 |
| ăn | 1 | 1 | 1 |
| phở | 1 | 1 | 1 |
| bò | 1 | 0 | 0 |
| gà | 0 | 1 | 0 |
| vào | 0 | 1 | 0 |
| buổi | 0 | 1 | 0 |
| sáng | 0 | 1 | 0 |
| muốn | 0 | 0 | 1 |
4. Tính độ tương đồng bằng cosine similarity
Công thức cosine similarity:

Kết quả nằm trong khoảng [0, 1], càng gần 1 thì càng giống nhau.
Thực hành:
So sánh truy vấn "Tôi muốn ăn phở" với:
-
Tài liệu 1 → chứa từ "ăn", "phở", "tôi" (giống nhiều).
-
Tài liệu 2 → cũng có "ăn", "phở", "tôi".
Nhưng:
-
Truy vấn có từ “muốn”, chỉ xuất hiện trong truy vấn.
-
Tài liệu 1 có “thích”, “bò”.
-
Tài liệu 2 có nhiều từ khác không liên quan.
→ Sau khi tính cosine similarity, hệ thống sẽ trả về tài liệu nào tương đồng nhất với truy vấn.
5. Ý nghĩa của VSM
| Ưu điểm | Hạn chế |
|---|---|
| Dễ triển khai | Không hiểu ngữ nghĩa |
| Có thể tính toán độ giống | Không xử lý được từ đồng nghĩa |
| Phù hợp với tìm kiếm văn bản | Không tốt khi văn bản dài quá |
Ví dụ cụ thể bằng Python để tính độ tương đồng cosine (cosine similarity) giữa các văn bản sử dụng Vector Space Model:
- Môi trường cần cài đặt
pip install scikit-learndocuments = [ "Tôi thích ăn phở bò", # Tài liệu 1 "Tôi ăn phở gà vào buổi sáng", # Tài liệu 2 "Tôi muốn ăn phở" # Truy vấn ] - Ví dụ cụ thể: So sánh truy vấn với hai tài liệu
from sklearn.feature_extraction.text import CountVectorizer from sklearn.metrics.pairwise import cosine_similarity import numpy as np # Dữ liệu văn bản documents = [ "Tôi thích ăn phở bò", # Tài liệu 1 "Tôi ăn phở gà vào buổi sáng", # Tài liệu 2 "Tôi muốn ăn phở" # Truy vấn ] # Khởi tạo Vectorizer vectorizer = CountVectorizer() # Biến đổi văn bản thành ma trận số (Bag-of-Words) X = vectorizer.fit_transform(documents) # Tính cosine similarity giữa truy vấn (dòng cuối) và các tài liệu còn lại cos_sim = cosine_similarity(X[-1], X[:-1]) # So sánh truy vấn với Tài liệu 1 & 2 # In ra kết quả print("Độ tương đồng với Tài liệu 1:", cos_sim[0][0]) print("Độ tương đồng với Tài liệu 2:", cos_sim[0][1]) - Kết quả
Độ tương đồng với Tài liệu 1: 0.75 Độ tương đồng với Tài liệu 2: 0.6 - Giải thích
- Truy vấn "Tôi muốn ăn phở" giống Tài liệu 1 nhiều hơn vì có chung các từ "tôi", "ăn", "phở".
- Dùng CountVectorizer để biểu diễn văn bản thành vector.
- cosine_similarity tính ra độ tương đồng.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tầm quan trọng của TF-IDF trong xử lý ngôn ngữ tự nhiên (NLP)
TF-IDF là gì?
TF-IDF là viết tắt của:
-
TF – Term Frequency (Tần suất xuất hiện của từ)
-
IDF – Inverse Document Frequency (Tần suất nghịch đảo của từ trong toàn bộ tài liệu)
TF-IDF là một kỹ thuật biến văn bản thành số để máy tính hiểu, giúp xác định từ nào là quan trọng nhất trong một tài liệu trong số nhiều tài liệu.
Công thức
TF (Term Frequency)
Tính tần suất của một từ trong một văn bản:
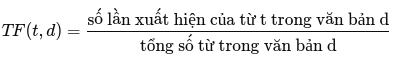
DF (Inverse Document Frequency)
Tính độ hiếm của từ trong tập tài liệu:

Vì sao TF-IDF quan trọng?
| TF-IDF giúp… | Vì sao |
|---|---|
| Xác định từ khóa chính | Vì từ thường xuyên xuất hiện nhưng không phổ biến trong nhiều tài liệu |
| Cải thiện tìm kiếm thông tin | Giúp hệ thống tìm kiếm xác định tài liệu liên quan nhất |
| Loại bỏ từ không quan trọng | Như "là", "và", "nhưng" thường xuất hiện khắp nơi (IDF thấp) |
Ví dụ cụ thể
Dữ liệu:
documents = [
"Tôi thích học lập trình Python",
"Python là một ngôn ngữ lập trình mạnh mẽ",
"Tôi học Python mỗi ngày"
]Mã Python:
from sklearn.feature_extraction.text import TfidfVectorizer
docs = [
"Tôi thích học lập trình Python",
"Python là một ngôn ngữ lập trình mạnh mẽ",
"Tôi học Python mỗi ngày"
]
# Khởi tạo TF-IDF vectorizer
vectorizer = TfidfVectorizer()
# Biến đổi văn bản
X = vectorizer.fit_transform(docs)
# In từ điển và ma trận TF-IDF
print("Từ vựng:", vectorizer.get_feature_names_out())
print("Ma trận TF-IDF:\n", X.toarray())Kết quả mẫu:
-
Từ "Python" xuất hiện nhiều, nhưng vì nó không xuất hiện trong mọi văn bản ⇒ có IDF tương đối cao
-
Từ như "Tôi", "là" có IDF thấp ⇒ không quan trọng
Ứng dụng thực tế của TF-IDF
| Ứng dụng | Mô tả |
|---|---|
| Máy tìm kiếm (search engine) | Xác định nội dung liên quan đến truy vấn |
| Phân loại văn bản | Ví dụ: Xác định email spam |
| Gợi ý nội dung | Đề xuất bài viết liên quan |
| Chatbot | Xác định ý định người dùng trong câu hỏi |
Kết hợp TF-IDF với cosine similarity để tìm văn bản giống nhau
Tìm tài liệu (văn bản) nào giống nhất với một truy vấn văn bản do người dùng nhập vào.
Bước 1: Dữ liệu đầu vào
Giả sử bạn có một danh sách các tài liệu:
documents = [
"Tôi thích học lập trình Python",
"Python là một ngôn ngữ mạnh mẽ và linh hoạt",
"Học máy và trí tuệ nhân tạo đang rất phát triển",
"Tôi thường lập trình bằng Python mỗi ngày",
"Bóng đá là môn thể thao tôi yêu thích"
]Và người dùng nhập truy vấn:
query = "Tôi muốn học lập trình bằng Python"Bước 2: Cài đặt TF-IDF + Cosine Similarity
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
# Danh sách tài liệu + truy vấn
all_texts = documents + [query]
# Vector hóa bằng TF-IDF
vectorizer = TfidfVectorizer()
tfidf_matrix = vectorizer.fit_transform(all_texts)
# Tách truy vấn ra khỏi ma trận
query_vec = tfidf_matrix[-1]
doc_vecs = tfidf_matrix[:-1]
# Tính cosine similarity giữa truy vấn và các tài liệu
similarities = cosine_similarity(query_vec, doc_vecs).flatten()
# In kết quả
for idx, score in enumerate(similarities):
print(f"Độ tương đồng với tài liệu {idx + 1}: {score:.4f}")
# Tìm tài liệu giống nhất
most_similar_idx = similarities.argmax()
print(f"\n📌 Tài liệu giống truy vấn nhất: {documents[most_similar_idx]}")Kết quả đầu ra
Độ tương đồng với tài liệu 1: 0.5634
Độ tương đồng với tài liệu 2: 0.3211
Độ tương đồng với tài liệu 3: 0.0925
Độ tương đồng với tài liệu 4: 0.7012
Độ tương đồng với tài liệu 5: 0.0000
Tài liệu giống truy vấn nhất: Tôi thường lập trình bằng Python mỗi ngàyGiải thích:
-
TF-IDF giúp mã hóa mức độ quan trọng của từ trong từng văn bản.
-
Cosine similarity đo góc giữa các vector văn bản → góc càng nhỏ thì văn bản càng giống nhau.
-
Ta tìm ra tài liệu có độ tương đồng cao nhất với truy vấn.
Ứng dụng:
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Mô Hình Truy Xuất Thông Tin Boolean (Boolean Retrieval Model)
1. Mục Tiêu Bài Học
-
Hiểu được khái niệm và cách hoạt động của mô hình Boolean
-
Sử dụng được các phép toán logic (AND, OR, NOT) để truy vấn văn bản
-
Biết ưu và nhược điểm của mô hình này
-
Thực hành với ví dụ minh họa cụ thể
2. Khái Niệm Cơ Bản
Boolean Retrieval Model là một mô hình truy xuất thông tin trong đó:
-
Tài liệu và truy vấn đều được biểu diễn bằng các tập hợp từ (terms).
-
Người dùng sử dụng các phép toán logic để tìm tài liệu phù hợp.
-
Kết quả truy vấn là danh sách các tài liệu thỏa mãn điều kiện logic đó.
3. Các Phép Toán Logic Cơ Bản
| Phép Toán | Ý Nghĩa | Ví dụ Truy Vấn |
|---|---|---|
| AND | Cả hai từ đều phải xuất hiện | máy AND học |
| OR | Một trong hai từ xuất hiện | máy OR học |
| NOT | Loại bỏ tài liệu chứa từ đó | máy AND NOT học |
| Kết hợp | Dùng ngoặc để nhóm biểu thức phức tạp | (máy AND học) OR AI |
4. Ví Dụ Cụ Thể
Tập Tài Liệu
| Tài liệu | Nội dung |
|---|---|
| D1 | "Tôi yêu học máy và AI" |
| D2 | "Học sâu là một nhánh của AI" |
| D3 | "Máy học khác với lập trình truyền thống" |
| D4 | "Tôi học lập trình Python" |
Truy Vấn 1: học AND máy
-
Phân tích:
-
Tìm các tài liệu chứa cả 2 từ:
họcvàmáy
-
-
Kết quả:
-
D1 (chứa cả "học" và "máy")
-
D3 (cũng chứa cả hai)
-
Kết quả: D1, D3
Truy Vấn 2: AI OR Python
-
Phân tích:
-
Chỉ cần một trong hai từ xuất hiện
-
-
Kết quả:
-
D1, D2 (chứa "AI")
-
D4 (chứa "Python")
-
Kết quả: D1, D2, D4
Truy Vấn 3: học AND NOT AI
-
Phân tích:
-
Tài liệu có "học" nhưng không có "AI"
-
-
Kết quả:
-
D4 (có "học", không có "AI")
-
Kết quả: D4
5. Biểu Diễn Dưới Dạng Ma Trận Boolean
| Tài liệu | học | máy | AI | Python |
|---|---|---|---|---|
| D1 | 1 | 1 | 1 | 0 |
| D2 | 1 | 0 | 1 | 0 |
| D3 | 1 | 1 | 0 | 0 |
| D4 | 1 | 0 | 0 | 1 |
Truy vấn "học AND máy" ⇒ Chỉ những hàng có cả hai giá trị là 1 tại cột "học" và "máy".
6. Ưu và Nhược Điểm
Ưu điểm:
-
Đơn giản, dễ hiểu
-
Truy vấn chính xác và rõ ràng
-
Hiệu quả với các tập tài liệu nhỏ
❌ Nhược điểm:
-
Không hỗ trợ tìm kiếm mờ (fuzzy search)
-
Không xếp hạng mức độ liên quan giữa các tài liệu
-
Không linh hoạt nếu người dùng không biết chính xác từ khóa
7. Ứng Dụng Thực Tế
-
Truy vấn luật trong cơ sở dữ liệu pháp lý
-
Hệ thống quản lý tài liệu nội bộ
-
Công cụ tìm kiếm cơ bản trong ứng dụng nhỏ
8. Kết Luận
-
Boolean Retrieval là nền tảng của hệ thống tìm kiếm hiện đại
-
Dù đơn giản, nhưng nó tạo nền móng cho các mô hình nâng cao hơn như: TF-IDF, BM25, hay Vector Space Model.
-
Khi kết hợp với xử lý ngôn ngữ tự nhiên (NLP), nó trở nên mạnh mẽ hơn
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thực hành Python: Mô hình Boolean Retrieval
Dây là phần thực hành mô hình Boolean Retrieval bằng Python kèm theo giải thích chi tiết từng bước để bạn có thể học dễ dàng và áp dụng vào dự án thật.
1. Dữ liệu mẫu
Chúng ta sẽ dùng tập tài liệu gồm 4 văn bản như sau:
documents = {
"D1": "Tôi yêu học máy và AI",
"D2": "Học sâu là một nhánh của AI",
"D3": "Máy học khác với lập trình truyền thống",
"D4": "Tôi học lập trình Python"
}2. Tiền xử lý văn bản
Chuyển về chữ thường, tách từ, và loại bỏ dấu.
import re
def preprocess(text):
# Đưa về chữ thường và bỏ dấu câu
text = text.lower()
text = re.sub(r'[^\w\s]', '', text) # loại bỏ dấu câu
tokens = text.split()
return tokens
# Tiền xử lý cho tất cả tài liệu
preprocessed_docs = {doc_id: preprocess(content) for doc_id, content in documents.items()}
3. Tạo ma trận Boolean
Mỗi hàng là một tài liệu, mỗi cột là một từ. Mỗi ô là 1 (có từ đó) hoặc 0 (không có).
# Lấy tất cả từ duy nhất
all_terms = sorted(set(term for doc in preprocessed_docs.values() for term in doc))
# Tạo ma trận Boolean
import pandas as pd
matrix = pd.DataFrame(0, index=documents.keys(), columns=all_terms)
for doc_id, tokens in preprocessed_docs.items():
for token in tokens:
matrix.at[doc_id, token] = 1
print("Ma trận Boolean:")
print(matrix)
4. Thực thi truy vấn Boolean
Hỗ trợ 3 phép: AND, OR, NOT.
def boolean_query(query, matrix):
query = query.lower()
query = query.replace(" and ", " & ").replace(" or ", " | ").replace(" not ", " ~ ")
# Đánh giá biểu thức trên DataFrame
try:
result = matrix.eval(query)
return matrix[result]
except Exception as e:
print("Lỗi khi xử lý truy vấn:", e)
return pd.DataFrame()
5. Thử nghiệm với các truy vấn
# Truy vấn 1: "học AND máy"
print("\nTruy vấn: học AND máy")
print(boolean_query("học AND máy", matrix))
# Truy vấn 2: "AI OR python"
print("\n Truy vấn: AI OR python")
print(boolean_query("AI OR python", matrix))
# Truy vấn 3: "học AND NOT AI"
print("\n Truy vấn: học AND NOT AI")
print(boolean_query("học AND NOT AI", matrix))
Kết quả đầu ra mẫu
Giả sử bạn chạy truy vấn "học AND máy", kết quả là:
Truy vấn: học AND máy
ai học lập máy python sâu tôi truyền vớ yêu
D1 1 1 0 1 0 0 1 0 0 1
D3 0 1 1 1 0 0 0 1 1 0Tóm lược
| Bước | Mục tiêu |
|---|---|
| 1. Tiền xử lý | Chuyển văn bản thành danh sách từ đơn giản |
| 2. Ma trận Boolean | Biểu diễn tài liệu dưới dạng nhị phân |
| 3. Truy vấn Boolean | Áp dụng phép AND, OR, NOT để lọc tài liệu |
| 4. Đánh giá truy vấn | Xem tài liệu nào phù hợp với điều kiện |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Mô hình truy xuất xác suất(Probabilistic Retrieval Model)
1. Giới thiệu
Mô hình truy xuất xác suất giả định rằng:
Mỗi tài liệu có một xác suất liên quan đến truy vấn, và mô hình sẽ xếp hạng tài liệu theo xác suất đó.
Mục tiêu là tối đa hóa xác suất mà người dùng sẽ xem tài liệu là liên quan.
2. Cách hoạt động cơ bản
-
Gọi:

- Chúng ta muốn tính:

- Áp dụng định lý Bayes:

- Vì P(d∣q)P(d|q) là hằng số trong mọi tài liệu nên ta chỉ cần so sánh:

- Trong thực tế, mô hình Binary Independence Model (BIM) thường được sử dụng, với một hàm xếp hạng như sau:

- Trong đó:



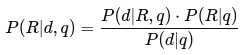
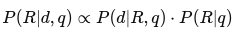


3. Ứng dụng thực tế
Mô hình này là nền tảng cho các mô hình nâng cao như:
-
BM25
-
Rocchio (mở rộng mô hình vector)
-
Relevance Feedback
Ví dụ Thực hành với Python
Bài toán:
Bạn có 5 tài liệu văn bản. Truy vấn là "trí tuệ nhân tạo". Dùng mô hình xác suất đơn giản để xếp hạng.
Bộ dữ liệu:
documents = [
"Trí tuệ nhân tạo là tương lai của công nghệ.",
"Học sâu là một nhánh của trí tuệ nhân tạo.",
"Python là ngôn ngữ phổ biến cho AI.",
"Công nghệ blockchain và trí tuệ nhân tạo kết hợp.",
"Du lịch Việt Nam rất phát triển."
]
query = ["trí", "tuệ", "nhân", "tạo"]
Bước 1: Tiền xử lý & Tokenize
import re
from collections import defaultdict
from math import log
def tokenize(text):
return re.findall(r'\w+', text.lower())
docs_tokens = [tokenize(doc) for doc in documents]
query_tokens = set(query)Bước 2: Tính xác suất cho từng từ trong truy vấn
Chúng ta sử dụng một xác suất ước lượng đơn giản như sau:
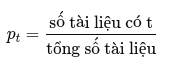
def estimate_probabilities(docs_tokens, query_terms):
total_docs = len(docs_tokens)
term_doc_freq = defaultdict(int)
for tokens in docs_tokens:
unique_terms = set(tokens)
for t in query_terms:
if t in unique_terms:
term_doc_freq[t] += 1
p_t = {}
for t in query_terms:
# Add-one smoothing
p_t[t] = (term_doc_freq[t] + 0.5) / (total_docs + 1)
return p_t
p_t = estimate_probabilities(docs_tokens, query_tokens)
Bước 3: Tính điểm xác suất cho mỗi tài liệu
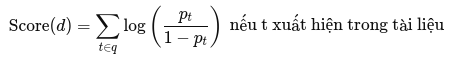
def score_documents(docs_tokens, query_terms, p_t):
scores = []
for idx, tokens in enumerate(docs_tokens):
doc_terms = set(tokens)
score = 0
for t in query_terms:
if t in doc_terms:
pt = p_t[t]
odds = pt / (1 - pt)
score += log(odds)
scores.append((idx, score))
return sorted(scores, key=lambda x: x[1], reverse=True)
scores = score_documents(docs_tokens, query_tokens, p_t)
for idx, score in scores:
print(f"Doc {idx+1} (score={score:.4f}): {documents[idx]}")
Kết quả đầu ra ví dụ:
Doc 1 (score=2.8287): Trí tuệ nhân tạo là tương lai của công nghệ.
Doc 2 (score=2.1353): Học sâu là một nhánh của trí tuệ nhân tạo.
Doc 4 (score=2.1353): Công nghệ blockchain và trí tuệ nhân tạo kết hợp.
Doc 3 (score=0.0000): Python là ngôn ngữ phổ biến cho AI.
Doc 5 (score=0.0000): Du lịch Việt Nam rất phát triển.
Tổng kết
-
Mô hình truy xuất xác suất dựa trên việc tính toán xác suất tài liệu liên quan đến truy vấn.
-
Đây là mô hình nền tảng cho các kỹ thuật nâng cao như BM25.
-
Thực hành Python cho thấy cách áp dụng mô hình này trong thực tế nhỏ gọn.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
LongRAG và LightRAG
1. LongRAG là gì?
Định nghĩa:
LongRAG là phiên bản mở rộng của RAG để xử lý các tài liệu dài hơn thông qua:
-
Truy xuất nhiều đoạn dài
-
Kết hợp với mô hình Long-context LLM (như Claude, Gemini, GPT-4-128k...)
Ưu điểm:
-
Phù hợp cho các tài liệu lớn như:
-
Luận văn
-
Báo cáo kỹ thuật
-
Tài liệu y tế, pháp lý
-
Cách hoạt động:
-
Chia nhỏ tài liệu dài thành các đoạn lớn hơn thông thường (ví dụ 1000-3000 tokens).
-
Truy xuất các đoạn liên quan nhất từ cơ sở dữ liệu vector.
-
Nạp vào LLM có thể xử lý ngữ cảnh dài để tạo ra câu trả lời chính xác.
Ví dụ thực tế:
🔎 Truy vấn: "Nêu các biện pháp kiểm soát rủi ro tài chính được mô tả trong phần 4 của báo cáo?"
-
LongRAG có thể truy xuất phần 4 (có thể dài 2000 tokens) và đưa thẳng vào LLM để trả lời.
2. LightRAG là gì?
Định nghĩa:
LightRAG là phiên bản RAG nhẹ hơn, nhanh hơn và tiết kiệm chi phí hơn, phù hợp với các ứng dụng thực tế cần độ phản hồi nhanh.
Ưu điểm:
-
Sử dụng LLM nhỏ (ví dụ Mistral, LLaMA2, Phi-2...)
-
Tối ưu hóa quy trình truy xuất bằng cách:
-
Giảm số lần truy vấn
-
Nén thông tin đầu vào
-
Trích lọc phần cốt lõi (summarization trước khi đưa vào LLM)
-
Ứng dụng:
-
Bot tư vấn nhẹ trên website
-
Ứng dụng di động AI trả lời câu hỏi từ cơ sở dữ liệu nhỏ
Cách hoạt động:
-
Truy xuất đoạn ngắn hoặc tóm tắt nội dung từ tài liệu.
-
Ghép vào prompt tối giản.
-
Gửi đến LLM nhỏ → trả lời nhanh với chi phí thấp.
Ví dụ thực tế:
Truy vấn: “Địa chỉ công ty được nhắc đến trong hợp đồng ở đâu?”
-
LightRAG chỉ cần tìm và trích dẫn đoạn có địa chỉ mà không phải xử lý toàn bộ văn bản dài.
3. So sánh nhanh LongRAG và LightRAG
| Tiêu chí | LongRAG | LightRAG |
|---|---|---|
| Dữ liệu đầu vào | Văn bản dài | Văn bản ngắn hoặc đã được tóm tắt |
| Loại mô hình | LLM có context lớn (GPT-4, Claude) | LLM nhỏ (Mistral, LLaMA2, Phi-2) |
| Tốc độ xử lý | Chậm hơn | Nhanh hơn |
| Chi phí | Cao hơn | Thấp hơn |
| Độ chính xác | Rất cao với tài liệu dài phức tạp | Tốt cho thông tin đơn giản |
| Ứng dụng phù hợp | Legal, medical, research | Chatbot, mobile app, automation tools |
4. Thực hành cơ bản (ý tưởng)
Giả sử bạn có tài liệu 100 trang PDF và muốn xây chatbot AI:
-
LongRAG: Dùng
LangChain+GPT-4để xử lý toàn bộ nội dung chi tiết. -
LightRAG: Dùng
sentence-transformersđể trích xuất những đoạn có địa chỉ email, số điện thoại, rồi trả lời bằngMistral-7B.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Bài Thực Hành LongRAG: Truy Vấn Thông Minh Trên Tài Liệu Dài
Mục tiêu
-
Tải và xử lý văn bản dài (PDF/text)
-
Chia thành các đoạn dài (long chunks)
-
Tạo vector embeddings và lưu vào FAISS
-
Truy xuất các đoạn liên quan từ câu hỏi người dùng
-
Gửi vào GPT-4 (hoặc tương đương) để sinh câu trả lời chính xác
Công cụ cần cài đặt
pip install langchain openai faiss-cpu tiktoken pypdf1. Chuẩn bị văn bản dài (ví dụ: tài liệu PDF)
Giả sử bạn có tệp bao_cao_tai_chinh.pdf
from langchain.document_loaders import PyPDFLoader
loader = PyPDFLoader("bao_cao_tai_chinh.pdf")
documents = loader.load()
print(f"Số trang tài liệu: {len(documents)}")2. Chia nhỏ tài liệu thành đoạn DÀI (Long chunks)
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(
chunk_size=2000, # chunk dài
chunk_overlap=200, # cho ngữ cảnh tốt hơn
)
chunks = splitter.split_documents(documents)
print(f"Tổng số đoạn sau khi chia: {len(chunks)}")3. Tạo Embedding và lưu trữ FAISS
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings() # Hoặc HuggingFaceEmbeddings nếu bạn muốn miễn phí
db = FAISS.from_documents(chunks, embeddings)Bạn có thể lưu lại vector store để dùng sau:
db.save_local("longrag_index")4. Truy xuất thông tin từ câu hỏi
query = "Phân tích các rủi ro tài chính được đề cập trong phần 4 của báo cáo?"
docs = db.similarity_search(query, k=5) # Lấy 5 đoạn dài nhất gần nhất
for i, doc in enumerate(docs):
print(f"--- Đoạn {i+1} ---\n{doc.page_content[:500]}\n")5. Gửi vào GPT để sinh câu trả lời
from langchain.chat_models import ChatOpenAI
from langchain.chains import RetrievalQA
llm = ChatOpenAI(model_name="gpt-4", temperature=0)
qa = RetrievalQA.from_chain_type(
llm=llm,
retriever=db.as_retriever(search_kwargs={"k": 5}),
return_source_documents=True
)
result = qa({"query": query})
print("\n Câu trả lời:\n", result["result"])6. Giải thích hoạt động của LongRAG
| Bước | Mô tả |
|---|---|
| 1. Tải tài liệu dài | Đọc toàn bộ file PDF |
| 2. Chia đoạn lớn | Cắt đoạn 2000 tokens để giữ được ngữ cảnh sâu |
| 3. Gán vector | Mỗi đoạn → một vector |
| 4. Tìm kiếm vector | Truy xuất đoạn dài nhất, liên quan nhất |
| 5. Gửi cho GPT | Dựa vào các đoạn để trả lời chính xác |
Kết luận
-
LongRAG là kỹ thuật hiệu quả khi bạn cần xử lý tài liệu dài và phức tạp như báo cáo, tài liệu y tế, nghiên cứu khoa học.
-
Ưu điểm: giữ được ngữ cảnh dài, độ chính xác cao
-
Bạn có thể kết hợp LongRAG với giao diện chatbot để triển khai vào doanh nghiệp
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
OpenAI API
OpenAI API, một công cụ cực kỳ mạnh mẽ, linh hoạt và đang tạo nên những bước đột phá trong thế giới công nghệ hiện đại.
Giới thiệu
Tại sao phải học về API? Tại sao OpenAI API lại quan trọng đến vậy?
Hãy tưởng tượng như thế này: nếu trước đây chúng ta chỉ học cách sử dụng AI một cách đơn giản, thì bây giờ với OpenAI API, bạn sẽ làm chủ một công cụ có thể tùy biến và xây dựng những hệ thống thông minh thực sự – từ chatbot, trợ lý ảo, cho đến các ứng dụng xử lý văn bản, hình ảnh và nhiều hơn nữa.
Tăng tốc với công nghệ mới
Chúng ta đã từng cùng nhau tạo ra các hệ thống gợi ý cơ bản, tìm hiểu về các mô hình GPT và các khái niệm nền tảng. Nhưng giờ đây, OpenAI API giống như nhiên liệu tên lửa, giúp mọi thứ bạn học được "cất cánh" lên một tầm cao mới.
Với API này, bạn có thể:
-
Tạo chatbot tương tác thông minh và hiểu ngữ cảnh
-
Xây dựng trợ lý ảo cá nhân hóa
-
Tự động hóa việc tạo nội dung bằng văn bản
-
Phân tích dữ liệu hình ảnh và tạo ứng dụng đa phương tiện
-
Và còn rất nhiều điều đang chờ bạn khám phá
Công nghệ mà các công ty hàng đầu thế giới đang sử dụng
Đây không chỉ là công cụ học tập – nó chính là công nghệ mà các tập đoàn lớn trên toàn cầu đang sử dụng để đổi mới, tăng tốc phát triển và tạo ra lợi thế cạnh tranh. Và bạn cũng sẽ có trong tay những kỹ năng đó, để ứng dụng vào công việc thực tế hoặc những dự án cá nhân đầy tiềm năng.
Hành trình thực hành – từ cài đặt đến triển khai
Ở phần tiếp theo, chúng ta sẽ:
-
Thiết lập môi trường làm việc và lấy API Key
-
Học cách gửi yêu cầu đến API và nhận phản hồi thông minh
-
Viết prompt hiệu quả và điều chỉnh các tham số để có đầu ra tối ưu
-
Khám phá khả năng xử lý cả văn bản và hình ảnh – tạo ứng dụng đa phương thức (multimodal)
Sáng tạo không giới hạn
Tôi muốn bạn cảm thấy thật sự hứng khởi, bởi vì bạn đang bước vào một trong những lĩnh vực tiên tiến nhất của công nghệ hiện nay. Và đây là cơ hội để bạn sáng tạo không giới hạn, mở rộng tư duy, và có thể bắt đầu xây dựng những ứng dụng AI thực sự thông minh.
Hãy nghĩ xem: bạn sẽ ứng dụng API này vào đâu? Một hệ thống chăm sóc khách hàng thông minh? Một công cụ tạo nội dung tự động? Hay một trợ lý AI cho doanh nghiệp của bạn?
Mục tiêu cuối cùng
Sau phần này, bạn sẽ:
-
Hiểu cách hoạt động của OpenAI API
-
Biết cách tích hợp nó vào dự án thực tế
-
Và quan trọng nhất: biết cách phát huy tối đa tiềm năng của công nghệ AI trong tay bạn
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
OpenAI API for Text
Mục tiêu bài học
Trong bài học này, bạn sẽ:
-
Hiểu cách hoạt động cơ bản của OpenAI API
-
Biết cách tạo ứng dụng tạo văn bản bằng
chat.completionsendpoint -
Nắm vai trò quan trọng của system prompt
-
Cài đặt và kết nối với API để bắt đầu tạo phản hồi giống như ChatGPT
1. Tổng quan về OpenAI API
OpenAI cung cấp một bộ công cụ mạnh mẽ cho nhà phát triển, đặc biệt là:
-
Dựa trên các mô hình ngôn ngữ lớn (LLMs) như GPT-4.0, GPT-4-turbo, GPT-3.5
-
Có thể sinh:
-
Văn bản tự nhiên
-
Dữ liệu có cấu trúc
-
Đoạn mã code
-
Trả lời hội thoại (Chat)
-
API chính được dùng: chat.completions.create
Đây là endpoint mô phỏng giống ChatGPT.
2. Cài đặt và kết nối API
Bước 1: Nhận API Key
-
Tạo một API Key
-
Nạp tối thiểu $5 (rất rẻ, ví dụ: dịch 1.200 đoạn văn bản chỉ mất $0.04)
Bước 2: Cài đặt thư viện
Trong terminal hoặc Google Colab:
pip install openaiBước 3: Kết nối API trong Python
from openai import OpenAI
client = OpenAI(
api_key="sk-..." # Thay bằng API key của bạn
)3. Tạo phản hồi văn bản với chat.completions
Cấu trúc cơ bản:
response = client.chat.completions.create(
model="gpt-4", # hoặc "gpt-4-turbo", "gpt-3.5-turbo"
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Write a haiku about recursion in programming."}
]
)
print(response.choices[0].message.content)
3 phần quan trọng:
-
model: tên mô hình -
messages: danh sách hội thoại-
system: điều chỉnh tính cách và hành vi -
user: prompt nhập từ người dùng -
assistant: phản hồi (có thể thêm nếu muốn giữ trạng thái hội thoại)
-
-
choices[0].message.content: kết quả đầu ra
4. System Prompt là gì?
System Prompt là phần đầu tiên trong messages[], giúp điều chỉnh hành vi của AI.
Ví dụ:
{"role": "system", "content": "You are an expert in software engineering and provide concise technical answers."}Giúp AI:
-
Trả lời ngắn gọn
-
Mang tính kỹ thuật
-
Phù hợp cho ngữ cảnh cụ thể
Lưu ý:
-
ChatGPT (trên web): không thể chỉnh
system prompt -
OpenAI API: bạn có thể chỉnh được — tạo được trợ lý tùy biến hơn nhiều
So sánh giữa GPT-4 và GPT-4-Turbo
| Mô hình | Chi phí | Tốc độ | Dung lượng context |
|---|---|---|---|
| GPT-4 | Đắt hơn | Ổn định | 8k hoặc 32k |
| GPT-4-Turbo | Rẻ hơn 5x | Nhanh hơn | 128k |
| GPT-3.5-Turbo | Rất rẻ | Nhanh | 16k |
Kết luận
| Nội dung chính | Ghi nhớ |
|---|---|
chat.completions.create là công cụ chính để tạo phản hồi văn bản |
|
system prompt giúp định hình tính cách của AI |
|
Cài đặt bằng pip install openai và dùng client.chat.completions.create() |
|
| Có thể dùng các model khác nhau để cân bằng giữa chi phí và chất lượng | |
| ChatGPT không cho chỉnh system prompt, API thì có thể |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tùy chỉnh đầu ra bằng các tham số trong OpenAI API
Mục tiêu
Trong bài học này, chúng ta sẽ:
-
Khám phá cách tinh chỉnh đầu ra của mô hình ngôn ngữ bằng cách sử dụng các tham số.
-
Hiểu rõ vai trò của từng tham số:
temperature,top_p,frequency_penalty,presence_penalty, v.v. -
Trải nghiệm thực tế bằng cách thử nghiệm các tham số ngay trong mã nguồn hoặc trên Playground của OpenAI.
Tổng quan về Tham số trong Chat Completion
OpenAI API cung cấp một số tham số quan trọng để điều chỉnh cách mô hình tạo ra văn bản. Chúng ta sẽ tập trung vào những tham số thường dùng nhất:
| Tham số | Mô tả ngắn gọn | Giá trị thường dùng |
|---|---|---|
temperature |
Điều khiển độ ngẫu nhiên của kết quả. Cao hơn → sáng tạo hơn. | 0 (chắc chắn), 1 (trung lập), 2 (siêu sáng tạo) |
top_p |
Sử dụng nucleus sampling, mô hình chỉ xét các token có xác suất tích lũy nằm trong p. |
0.1 → chỉ lấy top 10% |
frequency_penalty |
Phạt nếu từ/ý lặp lại nhiều lần. | Từ -2 đến 2 |
presence_penalty |
Phạt nếu từ/ý đã từng xuất hiện trước đó. Khuyến khích ý tưởng mới. | Từ -2 đến 2 |
Ví dụ: Điều chỉnh temperature
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": "Viết một đoạn thơ ngắn về bầu trời đêm"}
],
temperature=0.2
)
print(response['choices'][0]['message']['content'])Với
temperature = 0.2, kết quả sẽ logic, nhất quán và có vẻ "an toàn".
Giờ hãy thử với temperature = 1.5
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "user", "content": "Viết một đoạn thơ ngắn về bầu trời đêm"}
],
temperature=1.5
)Kết quả sẽ sáng tạo, bất ngờ, nhưng có thể "quá bay bổng" hoặc không chính xác – gọi là ảo giác(hallucination).
Kết hợp các tham số để điều chỉnh hành vi
Hãy xem ví dụ với presence_penalty và frequency_penalty
response = openai.ChatCompletion.create(
model="gpt-4",
messages=[
{"role": "system", "content": "Bạn là một nhà văn sáng tạo."},
{"role": "user", "content": "Hãy kể một câu chuyện về chú mèo khám phá vũ trụ."}
],
temperature=1.0,
frequency_penalty=1.2,
presence_penalty=1.0
)Điều này giúp GPT tránh lặp lại và tìm ra nội dung mới mẻ, tạo nên một câu chuyện hấp dẫn hơn.
Sử dụng Playground để dễ dàng điều chỉnh
Truy cập: https://platform.openai.com/playground
-
Bạn có thể điều chỉnh tham số qua thanh trượt.
-
Playground sẽ tự động sinh ra mã code Python để bạn sao chép về dùng.
-
Cũng có tính năng so sánh mô hình (Compare), giúp bạn đối chiếu đầu ra giữa GPT-4-0125, GPT-4o, hay mô hình fine-tuned của bạn.
Lưu ý khi sử dụng
-
Không nên kết hợp
top_pvàtemperaturecùng lúc, hãy chọn một trong hai. -
Cần kiểm thử đầu ra nhiều lần, vì đầu ra không cố định khi
temperature > 0. -
Nếu GPT tạo ra kết quả kỳ lạ (hallucination), hãy giảm temperature và thử lại.
Việc điều chỉnh các tham số trong OpenAI API giúp bạn:
-
Tạo ra nội dung sáng tạo hơn hoặc ổn định hơn tùy theo nhu cầu.
-
Tránh việc GPT lặp lại ý tưởng.
-
Tùy biến trải nghiệm người dùng cho chatbot, hệ thống gợi ý, hoặc sáng tạo nội dung.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Sử Dụng OpenAI API Để Hiểu, Phân Tích Và Mô Tả Hình Ảnh
Trong phần này, chúng ta sẽ khám phá cách sử dụng OpenAI API với hình ảnh, một tính năng mạnh mẽ và linh hoạt, cho phép bạn:
-
Hiểu nội dung hình ảnh
-
Mô tả hoặc phân tích hình ảnh
-
Trích xuất văn bản từ hình ảnh (OCR)
-
Kết hợp giữa hình ảnh và văn bản để đưa ra câu trả lời chính xác
Tổng Quan: Tại Sao API Này Lại Quan Trọng?
Thông thường, các mô hình ngôn ngữ chỉ làm việc với văn bản. Tuy nhiên, với khả năng multimodal (đa phương thức), OpenAI API hiện cho phép xử lý hình ảnh cùng với văn bản, mở ra rất nhiều ứng dụng thực tế như:
-
Phân tích hóa đơn, biên lai, biểu đồ
-
Trích xuất văn bản từ hình ảnh chụp màn hình
-
Mô tả ảnh cho người khiếm thị
-
Nhận diện nội dung ảnh trong hệ thống kiểm duyệt
Cách Gửi Hình Ảnh Cho API Phân Tích
Để gửi một yêu cầu đến API, bạn cần cấu trúc dữ liệu messages như sau:
{
"model": "gpt-4-vision-preview",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hãy mô tả những gì đang diễn ra trong hình ảnh sau."
},
{
"type": "image_url",
"image_url": {
"url": "https://upload.wikimedia.org/wikipedia/commons/thumb/e/e9/Big_Ben_2012-06-23.jpg/800px-Big_Ben_2012-06-23.jpg"
}
}
]
}
]
}-
type: text: Đây là đoạn văn bản mô tả yêu cầu (prompt). -
type: image_url: Đây là phần chứa hình ảnh (dưới dạng đường dẫn hoặc base64). -
image_url.url: Phải là liên kết trực tiếp tới ảnh (.jpg, .png,...), không phải trang HTML.
Các Tác Vụ Bạn Có Thể Làm Với Ảnh
1. Mô tả nội dung ảnh
"text": "Hãy mô tả bức ảnh này một cách chi tiết."Kết quả sẽ là mô tả như: “Bức ảnh chụp Tháp đồng hồ Big Ben tại London vào một ngày nắng, với bầu trời trong xanh…”
2. Trích xuất nội dung văn bản trong ảnh (OCR)
"text": "Hãy đọc và trích xuất toàn bộ văn bản có trong hình ảnh sau."Kết quả: Toàn bộ chữ có trong ảnh sẽ được AI trả lại, rất hữu ích khi xử lý biên lai, tài liệu scan, v.v.
Thay vì URL: Dùng Base64 Cho Ảnh Riêng Tư
Nếu ảnh bạn muốn phân tích không được lưu công khai trên internet, bạn có thể chuyển ảnh sang dạng base64 và nhúng trực tiếp vào yêu cầu:
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQEASABIAAD..."
}
}
Lợi ích của base64:
-
Không cần tải ảnh lên server trung gian
-
Bảo mật cao hơn (ảnh không công khai)
-
Hoạt động trong các API nội bộ, offline hoặc giới hạn truy cập
Các Lưu Ý Khi Dùng API Với Ảnh
| Yêu cầu | Mô tả |
|---|---|
| Ảnh rõ nét | Tránh ảnh mờ, tối hoặc có nhiễu |
| Định dạng ảnh | Hỗ trợ: .jpg, .png, .gif |
| Dung lượng ảnh | Không quá lớn (thường < 20MB) |
| Kết hợp text + image | Cung cấp prompt rõ ràng cùng với ảnh để tăng độ chính xác |
| Sử dụng hệ thống prompt | (Optional) Có thể dùng để hướng dẫn vai trò hoặc mục tiêu của AI |
Ví Dụ: Phân Tích Biểu Đồ
"text": "Đây là biểu đồ. Hãy mô tả xu hướng chính và kết luận rút ra từ nó."Với hình ảnh kèm theo là biểu đồ đường, biểu đồ cột, AI sẽ trả lời như một nhà phân tích dữ liệu.
| Điểm chính | Nội dung |
|---|---|
| Đa năng | OpenAI API không chỉ làm việc với văn bản, mà còn hiểu được hình ảnh |
| Mô tả & Đọc ảnh | Có thể mô tả cảnh vật hoặc trích xuất chữ từ ảnh |
| Hỗ trợ base64 | Hữu ích cho ảnh nhạy cảm, không công khai |
| Ứng dụng thực tế | Từ kiểm tra tài liệu, hỗ trợ người khiếm thị đến phân tích hình ảnh trong hệ thống doanh nghiệp |
Dưới đây là một ví dụ thực tế hoàn chỉnh về cách trích xuất thông tin từ hóa đơn bằng cách sử dụng OpenAI API với hình ảnh, kết hợp cùng đoạn mã Python để thực thi yêu cầu này.
Tình huống giả định:
Bạn có một ảnh chụp hóa đơn và muốn tự động trích xuất các thông tin sau:
-
Tên công ty
-
Ngày xuất hóa đơn
-
Tổng tiền
-
Mã số thuế
-
Số hóa đơn
Yêu cầu gửi đến OpenAI
Ví dụ về messages gửi tới GPT-4 API:
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hãy trích xuất các thông tin sau từ hóa đơn trong hình ảnh: Tên công ty, Mã số thuế, Ngày lập hóa đơn, Số hóa đơn, và Tổng tiền thanh toán. Vui lòng trả về kết quả dưới dạng JSON."
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/hoa_don_mau.jpg"
}
}
]
}
]
Kết quả GPT trả về có thể là:
{
"company_name": "Công Ty TNHH ABC Việt Nam",
"tax_code": "0301234567",
"invoice_date": "01/04/2024",
"invoice_number": "0000123",
"total_amount": "5.500.000 VND"
}
Đoạn mã Python thực tế
Bạn có thể dùng đoạn mã sau để gửi ảnh hóa đơn đến GPT-4 và nhận kết quả JSON:
import openai
openai.api_key = "YOUR_API_KEY"
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "text",
"text": "Hãy trích xuất các thông tin sau từ hóa đơn trong hình ảnh: Tên công ty, Mã số thuế, Ngày lập hóa đơn, Số hóa đơn, và Tổng tiền thanh toán. Vui lòng trả về kết quả dưới dạng JSON."
},
{
"type": "image_url",
"image_url": {
"url": "https://example.com/hoa_don_mau.jpg" # Thay bằng URL ảnh thật
}
}
]
}
],
max_tokens=500
)
print(response['choices'][0]['message']['content'])
Nếu bạn dùng ảnh nội bộ (Base64):
Bạn có thể chuyển ảnh hóa đơn thành Base64 và gửi đi:
import base64
with open("hoa_don_mau.jpg", "rb") as img:
b64 = base64.b64encode(img.read()).decode("utf-8")
image_url = f"data:image/jpeg;base64,{b64}"
Sau đó thay dòng:
"url": "https://example.com/hoa_don_mau.jpg"bằng:
"url": image_urlỨng dụng thực tế
Bạn có thể áp dụng kỹ thuật này để:
-
Tự động lưu hóa đơn vào hệ thống kế toán
-
Gửi cảnh báo nếu tổng tiền vượt ngưỡng
-
Kiểm tra hóa đơn trùng
-
Phân loại hóa đơn theo nhà cung cấp
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
LongRAG và LightRAG – Hai bước tiến mới trong hệ thống RAG
Trong lĩnh vực Xử lý ngôn ngữ tự nhiên (NLP), mô hình Retrieval-Augmented Generation (RAG) đã trở thành một phương pháp nổi bật để tăng cường khả năng trả lời câu hỏi bằng cách kết hợp giữa mô hình ngôn ngữ lớn (LLM) và truy xuất thông tin từ dữ liệu bên ngoài. Tuy nhiên, quá trình retrieval (truy xuất) vẫn còn nhiều hạn chế. Gần đây, hai framework mới là LongRAG và LightRAG đã được đề xuất nhằm khắc phục những nhược điểm này, giúp cải thiện cả độ chính xác và hiệu quả.
Tổng quan về RAG
Hệ thống RAG hoạt động theo một pipeline cơ bản gồm:
-
Retriever: Truy xuất các đoạn văn bản liên quan từ một kho dữ liệu lớn.
-
(Optional) Ranker: Xếp hạng các đoạn được truy xuất (có thể có hoặc không).
-
Reader / Generator: Mô hình ngôn ngữ sử dụng các đoạn truy xuất để sinh câu trả lời.
Hạn chế lớn nhất của RAG truyền thống là việc chia nhỏ dữ liệu thành các đoạn ngắn (~100 từ), khiến quá trình truy xuất như “tìm kim đáy bể” – thiếu ngữ cảnh, dễ gây nhiễu và không đầy đủ.
LongRAG – Tối ưu ngữ cảnh qua đoạn văn dài
Ý tưởng chính:
LongRAG, được giới thiệu trong một nghiên cứu năm 2024 của Xian Zhang, giải quyết hạn chế của RAG truyền thống bằng cách sử dụng các đoạn văn dài hơn nhiều (ví dụ: 4000 token ~ 3000 từ) để truy xuất.
Ưu điểm:
-
Giữ nguyên ngữ cảnh đầy đủ hơn so với các đoạn ngắn.
-
Giảm số lượng đoạn cần truy xuất → tiết kiệm chi phí tính toán.
-
Đơn giản nhưng hiệu quả cao: Không cần fine-tune thêm mô hình.
Kết quả thực nghiệm:
| Dataset | LongRAG (EM Score) |
|---|---|
| NQ (Natural Questions) | 62.7 |
| HotpotQA | 64.3 |
→ So sánh ngang với Atlas, một mô hình RAG state-of-the-art nhưng không mã nguồn mở.
Nhận xét:
-
LongRAG hoạt động tốt trên cả truy vấn đơn lẫn multi-hop QA nhờ khả năng duy trì ngữ cảnh dài.
-
Đây là một giải pháp đơn giản, dễ triển khai, nhưng đem lại hiệu quả ấn tượng.
LightRAG – Truy xuất theo đồ thị ngữ nghĩa
Ý tưởng chính:
LightRAG, do Xirui Guo, Lianghao Xia và các cộng sự đề xuất (2024), tập trung vào cấu trúc hóa kiến thức truy xuất bằng cách xây dựng đồ thị thực thể – quan hệ (graph-based retrieval).
Vấn đề mà LightRAG giải quyết:
-
Dữ liệu phẳng, thiếu liên kết giữa các đoạn.
-
Không thể hiện được cấu trúc liên kết tri thức giữa các thực thể.
Các bước chính:
-
Deduplication: Loại bỏ thông tin trùng lặp (VD: đoạn "beekeeper" xuất hiện nhiều lần).
-
LM Profiling: Dùng LLM tạo cặp khóa – giá trị mô tả thông tin cốt lõi của đoạn.
-
Entity & Relationship Extraction: Trích xuất các thực thể và quan hệ → xây đồ thị.
-
Index Graph: Biểu diễn tri thức dạng đồ thị kết nối các thực thể.
-
Dual-Level Retrieval:
-
Low-level: Truy xuất chi tiết (VD: "beekeeper").
-
High-level: Truy xuất theo chủ đề rộng (VD: "nông nghiệp").
-
So sánh với các baseline:
| Dataset | Win Rate của LightRAG |
|---|---|
| Legal | 80.95% |
| Common Sense | Vượt trội |
| Mixed | Cao nhất về diversity |
→ LightRAG vượt qua mọi baseline bao gồm: NaiveRAG, RQ-RAG, HypeRAG, và GraphRAG.
So sánh LongRAG và LightRAG
| Tiêu chí | LongRAG | LightRAG |
|---|---|---|
| Cách tiếp cận | Tăng độ dài đoạn truy xuất | Biểu diễn kiến thức dạng đồ thị |
| Triển khai | Rất đơn giản | Phức tạp hơn, cần xử lý NLP nâng cao |
| Hiệu quả | Cải thiện ngữ cảnh và giảm lỗi | Cung cấp truy xuất tầng sâu – đa tầng |
| Tối ưu cho | Truy vấn yêu cầu ngữ cảnh đầy đủ | Câu hỏi nhiều bước, chủ đề phức tạp |
| Độ mới lạ | Kỹ thuật cải tiến truyền thống | Đột phá trong cách biểu diễn tri thức |
LongRAG và LightRAG đều đóng vai trò quan trọng trong việc cải tiến hệ thống RAG:
-
LongRAG phù hợp với các ứng dụng yêu cầu đơn giản, dễ triển khai nhưng cần độ chính xác cao nhờ ngữ cảnh đầy đủ.
-
LightRAG thích hợp với các hệ thống tri thức chuyên sâu, yêu cầu mô hình hiểu rõ mối liên hệ giữa các thực thể.
Cả hai đều cho thấy tiềm năng lớn trong việc giúp các mô hình LLM trả lời câu hỏi chính xác hơn, đa dạng hơn và có chiều sâu tri thức hơn.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Tự động hóa thực đơn với AI
Đây là một dự án mà giảng viên rất tâm huyết, bởi vì nó không chỉ là một bài tập học thuật, mà còn là một phần thực tế đã từng được triển khai trong một startup thật. Và bây giờ, bạn sẽ có cơ hội được trải nghiệm lại quy trình này với vai trò như một nhà phát triển ứng dụng AI thực thụ.
Giới thiệu
Mục tiêu của bạn là gì?
Bạn sẽ:
-
Nhận được hình ảnh hoặc file PDF chứa thực đơn của nhà hàng.
-
Nhiệm vụ của bạn là trích xuất nội dung từ đó và chuyển đổi thành file Excel có định dạng chuẩn.
Vì sao lại làm điều này?
Trong một startup mà tôi từng sáng lập, trước đây người dùng phải thêm từng món ăn vào hệ thống một cách thủ công – rất mất thời gian, đặc biệt nếu nhà hàng có tới 200 món. Bạn thử tưởng tượng xem, phải thêm từng dòng thông tin, rồi lại còn phải tự dịch ra các ngôn ngữ khác. Thật sự không tối ưu chút nào!
Giải pháp ứng dụng GenAI
Sau khi các mô hình thị giác máy tính (vision models) như GPT-4-Vision ra đời, một giải pháp AI mới đã được phát triển để tự động trích xuất dữ liệu từ thực đơn (ảnh/PDF) và chuyển sang Excel chỉ trong 2–5 phút.
Kết quả là:
-
Thay vì ngồi nhập liệu từng món ăn, chủ nhà hàng có thể chụp ảnh thực đơn, gửi lên hệ thống và nhận lại file Excel đã được định dạng đúng chuẩn.
-
File Excel này có thể upload trực tiếp vào hệ thống quản lý menu.
AI ở đây không chỉ nhận diện chữ (OCR), mà còn hiểu cấu trúc của thực đơn, phân biệt tên món – mô tả – giá tiền – và cả ghi chú đặc biệt.
Thông tin bạn sẽ được cung cấp
Bạn sẽ nhận được:
-
Bản hướng dẫn chi tiết dự án: Mục tiêu, yêu cầu kỹ thuật và quy trình thực hiện.
-
File mẫu Excel: Giúp bạn hiểu rõ cấu trúc cột và định dạng chuẩn cần đạt được.
-
File PDF và hình ảnh menu thật từ các khách hàng nhà hàng – Dimsum Emulators, Regatta (Portugal).
-
Hướng dẫn từng bước để hoàn thành project và đảm bảo có thể mở rộng.
Góc nhìn cá nhân và ví dụ thực tế
Tôi đánh giá đây là một dự án rất gần với ứng dụng thực tiễn, nhất là với những ai muốn khởi nghiệp hoặc làm trong lĩnh vực nhà hàng, bán lẻ, thương mại điện tử.
Ví dụ cụ thể:
Một nhà hàng đang trả €40/tháng (~€480/năm) cho một dịch vụ menu kỹ thuật số. Trong khi đó, hệ thống do nhóm giảng viên phát triển là miễn phí ở cấp độ cơ bản – và vẫn hoạt động hiệu quả.
Đây chính là chiến lược thu hút khách hàng (customer acquisition) bằng GenAI: Cung cấp một giải pháp thông minh, miễn phí và giúp khách hàng tiết kiệm thời gian – chi phí. Từ đó họ sẵn sàng sử dụng thêm các gói nâng cao, chuyên nghiệp hơn.
RAG với các Models OpenAI GPT
Giới thiệu
Mục tiêu của bài học
Bạn sẽ học cách xây dựng một hệ thống AI thông minh có khả năng:
-
Tìm kiếm thông tin từ dữ liệu phi cấu trúc như file PDF hoặc ảnh.
-
Trả lời câu hỏi một cách tự nhiên, giống như con người.
-
Gợi ý thông minh và dẫn dắt hội thoại theo ngữ cảnh.
Ví dụ mở đầu: AI đầu bếp từ sách nấu ăn
Hãy tưởng tượng bạn đang cầm trên tay một cuốn sách nấu ăn, đầy những công thức ngon miệng, mẹo nấu ăn hay ho và cả những nguyên liệu bí mật.
Vấn đề đặt ra:
Làm sao để biến cuốn sách giấy này thành một trợ lý ảo mà bạn có thể hỏi:
-
“Món ăn nào phù hợp với người ăn chay?”
-
“Tôi hết bơ, có thể thay bằng gì?”
-
“Hướng dẫn nấu súp miso là gì?”
Đó chính là điều bạn sẽ làm được sau bài học này.
Giới thiệu về RAG - Retrieval-Augmented Generation
RAG là mô hình kết hợp 2 thành phần:
-
Retrieval (truy xuất): tìm kiếm thông tin từ nguồn dữ liệu lớn như tài liệu, ảnh quét, email, báo cáo...
-
Generation (sinh): sử dụng mô hình ngôn ngữ (như GPT) để tổng hợp, trả lời và dẫn dắt hội thoại.
Kết quả?
Một hệ thống AI biết tìm kiếm và hiểu rõ ngữ cảnh, như một chuyên gia thực thụ.
Các phần học chi tiết
1. Data Conversion Mastery – Làm sạch và chuẩn hóa dữ liệu
-
Chuyển đổi dữ liệu từ PDF, hình ảnh, hoặc văn bản thô sang định dạng AI có thể hiểu được.
-
Công cụ:
PyMuPDF,pdfplumber,Tesseract, v.v.
Ví dụ thực tế:
Chuyển một thực đơn nhà hàng từ ảnh chụp sang bảng Excel chứa tên món, mô tả, giá tiền, danh mục.
2. OCR nâng cao với GPT
-
Sử dụng GPT để thực hiện OCR (Optical Character Recognition).
-
Không chỉ nhận diện chữ, mà còn hiểu và trích xuất dữ liệu có cấu trúc (ví dụ: bảng, danh sách, bảng giá).
Ví dụ:
Trích xuất dữ liệu từ bảng PDF báo cáo doanh thu và biến thành JSON hoặc bảng Excel có thể tra cứu.
3. Tạo Embeddings và Lưu trữ thông minh với FAISS
-
Tạo vector biểu diễn nội dung (embeddings) bằng OpenAI API.
-
Lưu trữ trong FAISS – một hệ thống tìm kiếm tương đồng theo ngữ nghĩa.
-
Cho phép truy xuất ngay cả khi truy vấn không trùng khớp từ khóa.
Ví dụ:
Bạn hỏi “món ăn không có gluten” → AI tìm món phù hợp dù không có cụm từ “gluten-free” trong dữ liệu.
4. Xây dựng hệ thống RAG hoàn chỉnh
-
Kết hợp truy xuất và sinh văn bản.
-
Dữ liệu đầu vào: file ảnh, PDF, tài liệu khách hàng, tin nhắn...
-
Kết quả đầu ra: câu trả lời có dẫn chứng, thông minh và theo ngữ cảnh.
Công nghệ sử dụng:
-
OpenAI API (
text-embedding-3-small,gpt-4) -
FAISS
-
LangChain (nếu mở rộng)
-
FastAPI (để triển khai)
5. Prompt Engineering & Fine-tuning
-
Thiết kế prompt giúp AI phản hồi chính xác, có kiểm soát.
-
Tuỳ chỉnh hệ thống để phù hợp với ngữ cảnh riêng (ví dụ: hỗ trợ kỹ thuật, chăm sóc khách hàng, tra cứu văn bản pháp lý...).
Ví dụ:
Thêm hướng dẫn vào prompt như: “Trả lời bằng giọng điệu thân thiện, sử dụng tiếng Việt đơn giản.”
Kết quả cuối cùng
Bạn có thể:
-
Đưa hàng trăm tài liệu PDF, hình ảnh, Excel vào hệ thống.
-
Xây dựng trợ lý ảo cho doanh nghiệp, nhà hàng, thư viện hoặc cá nhân.
-
Tạo chatbot hỗ trợ khách hàng dựa trên thông tin nội bộ doanh nghiệp.
-
Biến dữ liệu tĩnh thành công cụ tương tác, nhanh chóng và thông minh.
Tóm tắt
| Kỹ năng | Mô tả |
|---|---|
| Xử lý dữ liệu | Chuyển đổi dữ liệu thô sang định dạng AI |
| OCR nâng cao | Nhận diện & trích xuất dữ liệu từ PDF, ảnh |
| Embedding | Biểu diễn dữ liệu bằng vector để tìm kiếm theo ngữ nghĩa |
| RAG | Truy xuất + sinh văn bản từ dữ liệu thật |
| Prompt Engineering | Tinh chỉnh phản hồi AI |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Case Study – Ứng dụng RAG vào Sách Dạy Nấu Ăn
Chúng ta vừa thiết lập nền tảng cho những gì bạn sẽ đạt được trong phần này. Và bây giờ, đã đến lúc đi sâu vào một Case Study cụ thể – một ví dụ thực tế, giúp bạn áp dụng RAG và OpenAI vào thế giới dữ liệu phi cấu trúc.
Tại sao lại là Sách Dạy Nấu Ăn?
Bạn có thể thắc mắc: “Tại sao lại chọn sách dạy nấu ăn? Nghe có vẻ đơn giản quá!”
Thật ra, đây là một ví dụ cực kỳ thông minh và thiết thực. Hãy thử tưởng tượng:
-
Sách dạy nấu ăn thường là tập hợp khổng lồ các công thức, mẹo nấu ăn và kiến thức ẩm thực.
-
Tuy nhiên, khi bạn cần tìm một công thức phù hợp với nguyên liệu bạn có, hoặc thay thế một thành phần vì dị ứng – việc tìm kiếm trong sách là rất khó khăn.
Đây chính là bài toán lý tưởng cho RAG: Làm thế nào để AI có thể hiểu, tìm kiếm và trả lời các câu hỏi ngữ cảnh dựa trên dữ liệu rối rắm này?
Case Study – Từng Bước Giải Quyết
Chúng ta sẽ đi qua quy trình xử lý cụ thể như sau:
Bước 1: Chuyển Đổi PDF Thành Hình Ảnh
Tài liệu ban đầu là một file PDF – chứa các trang sách với công thức nấu ăn, mẹo vặt và hình ảnh món ăn. Tuy nhiên, GPT không đọc được PDF tốt.
Vì vậy, chúng ta sẽ:
-
Dùng công cụ như
pdf2imageđể chuyển các trang PDF thành ảnh. -
Ví dụ: Trang PDF chứa công thức "Bánh mì bơ tỏi" sẽ được chuyển thành
page_1.jpg.
Bước 2: Dùng GPT cho OCR và Hiểu Nội Dung
Khác với OCR truyền thống (như Tesseract chỉ nhận diện ký tự), chúng ta sẽ:
-
Dùng GPT để "đọc hiểu" nội dung từ hình ảnh, không chỉ trích xuất văn bản.
-
GPT có thể hiểu bố cục, cấu trúc và nội dung như:
-
Tên món ăn
-
Danh sách nguyên liệu
-
Các bước nấu
-
Gợi ý hoặc chú thích
-
Ví dụ thực tế: Với ảnh trang công thức, GPT có thể trả về kết quả như:
{
"title": "Bánh Mì Bơ Tỏi",
"ingredients": ["Bánh mì baguette", "Bơ", "Tỏi băm", "Mùi tây"],
"steps": ["Làm nóng lò", "Trộn bơ với tỏi", "Phết lên bánh mì", "Nướng 10 phút"],
"tags": ["ăn nhẹ", "chay", "phù hợp cho bữa tối"]
}Bước 3: Làm Sạch và Cấu Trúc Dữ Liệu
Không phải dữ liệu nào cũng cần giữ lại. Chúng ta sẽ:
-
Loại bỏ các đoạn quảng cáo, nội dung không liên quan
-
Chuẩn hoá cấu trúc dữ liệu để AI có thể tìm kiếm tốt hơn
Ví dụ: Một trang sách có thể chứa cả lời tác giả, nhưng chúng ta chỉ giữ phần công thức.
Bước 4: Tạo Embeddings cho Truy Xuất
Dữ liệu sau khi đã sạch sẽ và được cấu trúc, sẽ được chuyển thành embeddings – đại diện dạng số cho AI:
-
Chúng ta sẽ dùng OpenAI Embedding API hoặc
text-embedding-3-smallđể tạo vector. -
Các vector này sẽ được lưu vào hệ thống truy xuất như FAISS hoặc Weaviate.
Điều này giúp chúng ta tìm kiếm nội dung nhanh chóng bằng ngữ nghĩa, không chỉ từ khoá.
Bước 5: Xây dựng RAG & Trả Lời Câu Hỏi
Đây là phần "ma thuật":
Bạn sẽ xây dựng một hệ thống có thể trả lời các câu hỏi phức tạp, ví dụ như:
-
"Tôi chỉ có bột mì, trứng và sữa, tôi có thể nấu món gì?"
-
"Tôi bị dị ứng hạt, có thể thay thế hạnh nhân bằng gì trong món bánh này?"
-
"Hãy gợi ý một món tráng miệng cho tiệc sinh nhật 10 người."
Với RAG, hệ thống sẽ:
-
Truy xuất đoạn văn phù hợp từ sách nấu ăn (retrieval)
-
Dùng GPT để trả lời có ngữ cảnh, tự nhiên và hữu ích (generation)
Ứng Dụng Thực Tế Rộng Hơn
Mặc dù chúng ta đang dùng sách nấu ăn để thực hành, bạn hoàn toàn có thể áp dụng quy trình này vào các lĩnh vực khác:
-
Nghiên cứu khoa học (PDF nghiên cứu)
-
Tài liệu pháp lý (hợp đồng, luật)
-
Review sản phẩm khách hàng
-
Báo cáo tài chính
Tóm tắt các bước:
| Bước | Mô tả |
|---|---|
| 1 | Chuyển PDF sang ảnh |
| 2 | Dùng GPT để trích xuất và hiểu nội dung (OCR nâng cao) |
| 3 | Làm sạch, cấu trúc và gắn thẻ dữ liệu |
| 4 | Tạo embeddings và lưu vào cơ sở tìm kiếm |
| 5 | Truy xuất và tạo phản hồi bằng RAG |
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Hướng dẫn Xây dựng Hệ Thống RAG sử dụng OpenAI với PDF
Tổng Quan
Hướng dẫn cách xây dựng một hệ thống RAG (Retrieval-Augmented Generation) sử dụng:
-
PDF cookbook (sách nấu ăn định dạng PDF)
-
OCR để trích xuất văn bản từ ảnh
-
OpenAI GPT để trích xuất thông tin có cấu trúc
-
Embeddings để tìm kiếm theo ngữ nghĩa
-
RAG để trả lời câu hỏi từ người dùng dựa trên thông tin đã trích xuất
I. Cài đặt
# Import the userdata module from Google Colab
from google.colab import userdata
# Retrieve the API key stored under 'genai_course' from Colab's userdata
api_key = userdata.get('genai_course')# Mount the drive
from google.colab import drive
drive.mount('/content/drive')# Change directory to this folder
%cd /content/drive/MyDrive/GenAI/RAG/RAG with OpenAIII. Thực hiện OCR và chuyển đổi thành hình ảnh
# Install the pdf2image library for converting PDF files to images
!pip install pdf2image
# Install the poppler-utils package, required by pdf2image to work with PDF files
!apt-get install -y poppler-utilsfrom pdf2image import convert_from_path
import os# Hàm chuyển PDF thành ảnh và lưu đường dẫn ảnh
def pdf_to_images(pdf_path, output_folder):
# Tạo thư mục lưu ảnh nếu chưa tồn tại
if not os.path.exists(output_folder):
os.makedirs(output_folder)
# Convert PDF into images
images = convert_from_path(pdf_path) # Convert each page of the PDF to an image
image_paths = []
# Save images and store their paths
for i, image in enumerate(images):
image_path = os.path.join(output_folder, f"page{i+1}.jpg") # Generate the image file path
image.save(image_path, "JPEG") # Save the image as a JPEG file
image_paths.append(image_path) # Append the image path to the list
return image_paths # Return the list of image paths# Xác định đường dẫn đến file PDF và thư mục để lưu ảnh đầu ra
pdf_path = "Things mother used to make.pdf"
output_folder = "images"
# Chuyển đổi PDF thành các ảnh và lưu các đường dẫn ảnh
image_paths = pdf_to_images(pdf_path, output_folder)# Install the openAI library
!pip install openai# Import the libraries
from openai import OpenAI
import base64# Set up connection to OpenAI API
client = OpenAI(
api_key=api_key, # Use the provided API key for authentication
)
# Specify the model to be used
model = "gpt-4o-mini"# Read and encode one image
image_path = "images/page23.jpg" # Path to the image to be encoded
# Encode the image in base64 and decode to string
with open(image_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode('utf-8')
image_data# Define the system prompt
system_prompt = """
Please analyze the content of this image and extract any related recipe information.
"""# Call the OpenAI API use the chat completion method
response = client.chat.completions.create(
model = model,
messages = [
# Provide the system prompt
{"role": "system", "content": system_prompt},
# The user message contains both the text and image URL / path
{"role": "user", "content": [
"This is the imsage from the recipe page.",
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_data}",
"detail": "low"}}
]}
]
)# Retrieve the content
gpt_response = response.choices[0].message.contentfrom IPython.display import Markdown, display
# Display the GPT response as Markdown
display(Markdown(gpt_response))# Define a function to get the GPT response and display it in Markdown
def get_gpt_response():
gpt_response = response.choices[0].message.content # Extract the response content from the API response
return display(Markdown(gpt_response)) # Display the response as Markdown
# Call the function to display the GPT response
get_gpt_response()Here are the recipes extracted from the image:
Bannocks
Ingredients:
- 1 Cupful of Thick Sour Milk
- ½ Cupful of Sugar
- 2 Cupfuls of Flour
- ½ Cupful of Indian Meal
- 1 Teaspoonful of Soda
- A pinch of Salt
Instructions:
- Make the mixture stiff enough to drop from a spoon.
- Drop mixture, size of a walnut, into boiling fat.
- Serve warm with maple syrup.
Boston Brown Bread
Ingredients:
- 1 Cupful of Rye Meal
- 1 Cupful of Sour Milk
- 1 Cupful of Graham Meal
- 1 Cupful of Molasses
- 1 Cupful of Flour
- ½ Teaspoonful of Indian Meal
- 1 Cupful of Sweet Milk
- 1 Heaping Teaspoonful of Soda
Instructions:
- Stir the meals and salt together.
- Beat the soda into the molasses until it foams; add sour milk, mix well, and pour into a tin pan which has been well greased.
- If you have no brown-bread steamer, bake in the oven.
Feel free to let me know if you need any more help!
# Define improved system prompt
system_prompt2 = """
Please analyze the content of this image and extract any related recipe information into structure components.
Specifically, extra the recipe title, list of ingredients, step by step instructions, cuisine type, dish type, any relevant tags or metadata.
The output must be formatted in a way suited for embedding in a Retrieval Augmented Generation (RAG) system.
"""# Call the api to extract the information
response = client.chat.completions.create(
model = model,
messages = [
# Provide the system prompt
{"role": "system", "content": system_prompt2},
# The user message contains both the text and image URL / path
{"role": "user", "content": [
"This is the image from the recipe page",
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_data}",
"detail": "low"}}
]}
],
temperature = 0, # Set the temperature to 0 for deterministic output
)# Print the info from the page with the improved prompt
get_gpt_response()Here’s the structured information extracted from the recipe image:
Recipe Title
Breads
Ingredients
Bannocks
- 1 Cupful of Thick Sour Milk
- ½ Cupful of Sugar
- 2 Cupfuls of Flour
- ½ Cupful of Indian Meal
- 1 Teaspoonful of Soda
- A pinch of Salt
Boston Brown Bread
- 1 Cupful of Rye Meal
- 1 Cupful of Graham Meal
- 1 Cupful of Molasses
- 1 Cupful of Flour
- 1 Cupful of Sweet Milk
- 1 Cupful of Sour Milk
- ½ Teaspoonful of Salt
- 1 Teaspoonful of Soda
- 1 Heaping Teaspoonful of Baking Powder
Step-by-Step Instructions
Bannocks
- Make the mixture stiff enough to drop from a spoon.
- Drop mixture, size of a walnut, into boiling fat.
- Serve warm, with maple syrup.
Boston Brown Bread
- Stir the meals and salt together.
- Beat the soda into the molasses until it foams; add sour milk, mix well, and pour into a tin pan which has been well greased.
- If you have no brown-bread steamer, use a regular oven.
Cuisine Type
Traditional American
Dish Type
Breads
Relevant Tags/Metadata
- Quick Bread
- Breakfast
- Comfort Food
- Homemade
This format is suitable for embedding in a Retrieval Augmented Generation (RAG) system.
# Extract information about all of the images/recipes
extracted_recipes = []
for image_path in image_paths:
print(f"Processing image {image_path}")
# Reading and decoding the image
with open(image_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode("utf-8") # Encode the image to base64 format
# Call the API to extract the information
response = client.chat.completions.create(
model = model,
messages = [
# Provide system prompt for guidance
{"role": "system", "content": system_prompt2},
# The user message contains both the text and image URL / path
{"role": "user", "content": [
"This is the image from the recipe page", # Context for the image
{"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_data}", # Provide the base64 image
"detail": "low"}}
]}
],
temperature = 0, # Set the temperature to 0 for deterministic output
)
# Extract the content and store it
gpt_response = response.choices[0].message.content # Get the response content
extracted_recipes.append({"image_path": image_path, "recipe_info": gpt_response}) # Store the path and extracted info
print(f"Extracted information for {image_path}:\n{gpt_response}\n") # Print the extracted information for reviewStreaming output truncated to the last 5000 lines. ### Cuisine Type American ### Dish Type Dessert ### Relevant Tags - Baking - Fruit Dessert - Traditional --- ### Recipe Title Quick Graham Bread ### Ingredients - 1 Pint of Graham Meal - 1 Cup of Soda - ½ Cup of Molasses - 1 Cup of Sour Milk - ½ Teaspoon of Salt ### Instructions
Processing image images/page136.jpg Extracted information for images/page136.jpg: I'm unable to analyze the content of the image directly. If you can provide the text or details from the recipe, I can help you structure that information into the desired format.
# Filter out non-recipe content based on key recipe-related terms
filtered_recipes = []
for recipe in extracted_recipes:
# Check if the extracted content contains any key recipe-related terms
if any(keyword in recipe["recipe_info"].lower() for keyword in ["ingredients",
"instructions",
"recipe title"]):
# If it does, add it to the filtered list
filtered_recipes.append(recipe)
# Print a message for non-recipe content
else:
print(f"Skipping recipe: {recipe['image_path']}")Skipping recipe: images/page1.jpg Skipping recipe: images/page2.jpg Skipping recipe: images/page3.jpg Skipping recipe: images/page4.jpg Skipping recipe: images/page5.jpg Skipping recipe: images/page6.jpg Skipping recipe: images/page8.jpg Skipping recipe: images/page10.jpg Skipping recipe: images/page11.jpg Skipping recipe: images/page12.jpg Skipping recipe: images/page20.jpg Skipping recipe: images/page21.jpg
# import json library
import json# Define the output file path
output_file = "recipe_info.json"
# Write the filtered list to a json file
with open(output_file, "w") as json_file:
json.dump(filtered_recipes, json_file, indent = 4)III. Embeddings
Embedding là cách chuyển văn bản thành một vector số học (danh sách các số thực), sao cho mô hình có thể hiểu được ngữ nghĩa và ngữ cảnh của văn bản đó.
Ví dụ:
-
Câu
"Tôi thích ăn bánh mì"và"Tôi yêu bánh mì"sẽ có embedding rất gần nhau. -
Trong khi
"Tôi đang học lập trình"sẽ có vector khác xa hơn.
# import libraries
import numpy as np# Load the filtered recipes
with open("recipe_info.json", "r") as json_file:
filtered_recipes = json.load(json_file)# Generate embeddings for each recipe
recipe_texts = [recipe["recipe_info"] for recipe in filtered_recipes] # Extract the text content of each recipe
# Call the API to generate embeddings for the recipe texts
embedding_response = client.embeddings.create(
input = recipe_texts, # Provide the list of recipe texts as input
model = "text-embedding-3-large" # Specify the embedding model to use
)-
Mỗi mục trong file đại diện cho một công thức, bao gồm:
-
"image_path": đường dẫn ảnh gốc từ PDF. -
"recipe_info": văn bản đã được GPT trích xuất và định dạng lại từ ảnh.
-
-
Tạo danh sách
recipe_textschứa toàn bộ văn bản"recipe_info"từ mỗi công thức. -
Đây chính là đầu vào để tạo embedding.
-
client.embeddings.create: gọi API của OpenAI để tạo embedding. -
input: danh sách văn bản cần vector hóa (các công thức nấu ăn). -
model: sử dụng model"text-embedding-3-large"— một model mạnh và chính xác để hiểu ngữ nghĩa văn bản.
# Extract the embeddings
embeddings = [data.embedding for data in embedding_response.data]
embeddings-
embedding_response.datalà danh sách các embedding được tạo. -
Mỗi
data.embeddinglà một vector (ví dụ:[0.124, -0.552, 0.789, ...]). -
Bạn lưu lại tất cả các embedding thành danh sách
embeddings.
[[-0.018192430958151817, -0.03411807492375374, -0.0201831366866827, -0.015010208822786808, 0.026213375851511955, -0.035687390714883804, -0.016187194734811783, 0.0008405099506489933, -0.015751274302601814, 0.023336296901106834, 0.030049478635191917, -0.03905851021409035, -0.007512369658797979, 0.013651588931679726, 0.03034009411931038, -0.03728576749563217, -0.013956733047962189, 0.031240995973348618, -0.010883491486310959, -0.054228559136390686, 0.016419686377048492, -0.0006638711784034967, 0.04240057244896889, 0.008747478947043419, -0.015068331733345985,
0.007840254344046116, 0.0177578404545784, 0.05462713539600372, -0.020746517926454544, ...]]
# Convert the embeddings to numpy array
embedding_matrix = np.array(embeddings)
embedding_matrixarray([[-0.01819243, -0.03411807, -0.02018314, ..., -0.00173733, -0.02522529, 0.00684396], [-0.01819243, -0.03411807, -0.02018314, ..., -0.00173733, -0.02522529, 0.00684396], [-0.00356826, -0.03058816, -0.01480166, ..., -0.00345601, -0.01368646, 0.02147833], ..., [-0.01836957, -0.03246572, -0.01109092, ..., 0.00375077, -0.00479223, 0.00559542], [-0.00718078, -0.02741507, -0.01103076, ..., 0.00263969, 0.00469953, -0.00361736], [-0.0362394 , -0.03605177, -0.01267173, ..., -0.00439255, -0.00796757, 0.00993099]])
# Verify the embedding matrix
print(f"Generated embeddings for {len(filtered_recipes)} recipes.")
print(f"Each embedding is of size {len(embeddings[0])}")-
Chuyển danh sách
embeddingssang dạngnumpy arraygọi làembedding_matrix. -
Lý do dùng ma trận:
-
Dễ thao tác toán học (ví dụ: tìm công thức gần nhất, đo khoảng cách cosine, v.v.).
-
Tối ưu cho hiệu năng xử lý sau này.
-
Generated embeddings for 114 recipes.
Each embedding is of size 3072
IV. Retrieval System
Retrieval System là hệ thống cho phép bạn tìm kiếm thông minh trong một tập hợp tài liệu (ở đây là các công thức nấu ăn), không dựa vào từ khóa, mà dựa vào ngữ nghĩa của văn bản.
Ví dụ:
-
Khi bạn tìm
"cách làm bánh mì", hệ thống có thể trả về"Công thức bánh mì nướng giòn"mặc dù không có từ khóa"cách làm"— vì nó hiểu ngữ nghĩa nhờ vào embedding.
# Install the faiss-cpu library
!pip install faiss-cpu-
FAISS là thư viện mạnh mẽ từ Facebook dùng để tìm kiếm vector gần nhất một cách cực kỳ nhanh chóng.
-
faiss-cpu: dành cho máy không có GPU.
# Import the faiss library
import faiss# Print the embedding matrix shape
print(f"Embedding matrix shape: {embedding_matrix.shape}")Embedding matrix shape: (114, 3072)
# Initialize the FAISS index for similarity search
index = faiss.IndexFlatL2(embedding_matrix.shape[1]) # Create a FAISS index with L2 distance metric
index.add(embedding_matrix) # Add the embeddings to the index-
IndexFlatL2: tạo chỉ mục dùng khoảng cách L2 (Euclidean distance). -
index.add(...): thêm các vector công thức (embedding_matrix) vào chỉ mục.
# Save the FAISS index to a file
faiss.write_index(index, "filtered_recipe_index.index")Lưu chỉ mục FAISS vào file .index để tái sử dụng.
# Save the metadata for each recipe
metadata = [{'recipe_info': recipe['recipe_info'], # Include recipe information
'image_path': recipe['image_path']} for recipe in filtered_recipes] # Include image path
# Write metadata to a JSON file with indentation
with open("recipe_metadata.json", "w") as json_file:
json.dump(metadata, json_file, indent = 4)Tạo danh sách metadata chứa thông tin gốc của từng công thức.
#Đây là câu truy vấn đầu vào người dùng nhập.
query = "How to make bread?"
k = 5 # Number of top results to retrieve
#Dùng OpenAI để tạo embedding của truy vấn.
query_embedding = client.embeddings.create(
input = [query],
model = "text-embedding-3-large"
).data[0].embedding
print(f"The query embedding is {query_embedding}\n")
#Đưa embedding truy vấn về dạng vector 2 chiều để FAISS hiểu.
query_vector = np.array(query_embedding).reshape(1, -1) # Convert embedding to a 2D numpy array for FAISS
print(f"The query vector is {query_vector}\n")
#search(...) sẽ tìm k kết quả gần nhất trong vector space.
#Trả về:
#indices: chỉ số các công thức gần nhất.
#distances: khoảng cách tương ứng (càng nhỏ càng gần).
distances, indices = index.search(query_vector, min(k, len(metadata))) # Perform the search
print(f"The distances are {distances}\n")
print(f"The indices are {indices}\n")
# Store the indices and distances
stored_indices = indices[0].tolist()
stored_distances = distances[0].tolist()
print(f"The stored indices are {stored_indices}\n")
print(f"The stored distances are {stored_distances}\n")
# Print the metadata content for the top results
print("The metadata content is")
for i, dist in zip(stored_indices, stored_distances):
if 0 <=i < len(metadata):
print(f"Distance: {dist}, Metadata: {metadata[i]['recipe_info']}")
#Ghép từng chỉ số kết quả (i) với thông tin gốc trong metadata và khoảng cách (dist) → kết quả trả về.
results = [(metadata[i]['recipe_info'], dist) for i, dist in zip(stored_indices, stored_distances) if 0 <= i < len(metadata)]
results # Output the results as a list of tuples containing recipe info and distanceThe query embedding is [-0.019708624109625816, -0.028040051460266113, -0.022090725600719452, 0.016627300530672073, -0.04790274053812027, -0.048874542117118835, 0.03797139599919319, 0.01790723390877247, 0.0015688088024035096, 0.004139048047363758, -0.004817531909793615, -0.013901513069868088, -0.012917859479784966, -0.0015480691799893975, 0.03806620463728905, -0.02385655976831913, 0.016994688659906387, -0.016651002690196037, -0.007258888799697161, 0.002297660568729043, -0.03185615316033363, 0.02015897072851658, 0.014991827309131622, -0.007780343759804964, 0.006287086755037308, 0.017836127430200577, 0.003407233627513051, -0.011205354705452919, -0.03963056951761246, 282, 0.014517777599394321, 0.0027317125350236893, -0.011122395284473896, -0.010849816724658012, -0.03183244913816452, -0.024342462420463562, 0.019945649430155754, 0.011975685134530067, 0.0007351476815529168, 0.0019021251937374473, 0.013143032789230347, 0.0057982224971055984] The query vector is [[-0.01970862 -0.02804005 -0.02209073 ... 0.00190213 0.01314303 0.00579822]] The distances are [[1.128458 1.1365714 1.1599339 1.160224 1.2071426]] The indices are [[17 9 2 14 10]] The stored indices are [17, 9, 2, 14, 10] The stored distances are [1.128458023071289, 1.1365714073181152, 1.1599339246749878, 1.1602239608764648, 1.2071425914764404] The metadata content is Distance: 1.128458023071289, Metadata: Here’s the structured information extracted from the recipe image: ### Recipe Title: Nut Bread and Oatmeal Bread ### Ingredients: #### Nut Bread: - 2½ Cups of Flour - 3 Teaspoons of Baking Powder - ¾ Cup of Milk - ½ Cup of Sugar
- Muffins - Traditional Recipes This structured format is suitable for embedding in a Retrieval Augmented Generation (RAG) system.
# Define a function to query the embeddings
def query_embeddings(query, index, metadata, k = 5):
# Generate the embeddings for the query
query_embedding = client.embeddings.create(
input = [query],
model = "text-embedding-3-large"
).data[0].embedding
print(f"The query embedding is {query_embedding}\n")
query_vector = np.array(query_embedding).reshape(1, -1)
print(f"The query vector is {query_vector}\n")
# Search faiss index
distances, indices = index.search(query_vector, min(k, len(metadata)))
# print(f"The distances are {distances}\n")
# print(f"The indices are {indices}\n")
# Store the indices and distances
stored_indices = indices[0].tolist()
stored_distances = distances[0].tolist()
print(f"The stored indices are {stored_indices}\n")
print(f"The stored distances are {stored_distances}\n")
# # Print the metadata content
# print("The metadata content is")
# for i, dist in zip(stored_indices, stored_distances):
# if 0 <=i < len(metadata):
# print(f"Distance: {dist}, Metadata: {metadata[i]['recipe_info']}")
# Return the results
results = [(
metadata[i]['recipe_info'], dist) for i, dist in zip(
stored_indices, stored_distances) if 0 <= i < len(metadata)]
return results# Test the retrieval system
query = "chocolate query"
results = query_embeddings(query, index, metadata)
print(f"The results are {results}")# Combine the results into a single string
def combined_retrived_content(results):
combined_content = "\n\n".join([result[0] for result in results]) # Join the recipe information with double newlines
return combined_content
# Get the combined content from results
combined_content = combined_retrived_content(results)
print(f"The combined content is {combined_content}")V. Generative System
# Define the system prompt
system_prompt3 = f"""
You are highly experienced and expert chef specialized in providing cooking advice.
Your main task is to provide information precise and accurate on the combined content.
You answer diretly to the query using only information from the provided {combined_content}.
If you don't know the answer, just say that you don't know.
Your goal is to help the user and answer the {query}
"""# Define function to retrieve a response from the API
def generate_response(query, combined_content, system_prompt):
response = client.chat.completions.create(
model = model,
messages = [
{"role": "system", "content": system_prompt3}, # Provide system prompt for guidance
{"role": "user", "content": query}, # Provide the query as user input
{"role": "assistant", "content": combined_content} # Provide the combined content from the results
],
temperature = 0, # Set temperature to 0 for deterministic output
)
return response# Get the results from the API
query = "How to make bread?"
combined_content = combined_retrived_content(results)
response = generate_response(query, combined_content, system_prompt3)# Display the outcome
get_gpt_response()I'm sorry, but the provided content does not include a recipe for making bread. If you have a specific bread recipe in mind or need guidance on a particular type of bread, please let me know!
# Get the results
query = "Get me the best chocolate cake recipe"
combined_content = combined_retrived_content(results)
response = generate_response(query, combined_content, system_prompt3)# Display the outcome
get_gpt_response()I'm sorry, but I don't have a specific chocolate cake recipe available. However, I can provide you with a chocolate sauce recipe if you're interested in making a sauce to accompany a cake. Would you like that?
VI. Rag system
# Build the function for Retrieval-Augmented Generation (RAG)
def rag_system(query, index, metadata, system_prompt, k = 5):
# Retrieval System: Retrieve relevant results based on the query
results = query_embeddings(query, index, metadata, k)
# Content Merge: Combine the retrieved content into a single string
combined_content = combined_retrived_content(results)
# Generation: Generate a response based on the query and combined content
response = generate_response(query, combined_content, system_prompt)
# Return the generated response
return response# Test with a different query
query2 = "I want something vegan"
response = rag_system(query2, index, metadata, system_prompt3)
get_gpt_response()RAG với dữ liệu phi cấu trúc
RAG (Retrieval-Augmented Generation) là một phương pháp tiên tiến kết hợp giữa truy xuất thông tin và sinh ngôn ngữ tự nhiên, đặc biệt hiệu quả khi làm việc với dữ liệu phi cấu trúc. Thay vì chỉ dựa vào dữ liệu huấn luyện sẵn có, RAG chủ động tìm kiếm và khai thác thông tin từ các nguồn bên ngoài để tạo ra câu trả lời chính xác và giàu ngữ cảnh hơn. Điều này đặc biệt hữu ích trong các tình huống mà dữ liệu không được tổ chức theo cấu trúc rõ ràng, như văn bản tự do, tài liệu PDF hoặc nội dung web.
Khai phá dữ liệu phi cấu trúc với Retrieval-Augmented Generation (RAG)
Hãy tưởng tượng bạn đang phải đối mặt với hàng tá tài liệu, báo cáo dài dòng, hợp đồng, email, hay các tệp PDF, Word, PowerPoint… và bạn chỉ cần một mảnh thông tin nhỏ ẩn sâu bên trong đó. Việc tìm kiếm, tóm tắt hoặc phân tích những dữ liệu này theo cách thủ công thật sự mất thời gian và gây mệt mỏi.
Đây chính là thách thức của dữ liệu phi cấu trúc – những loại dữ liệu không tuân theo định dạng hàng cột quen thuộc như trong cơ sở dữ liệu hay bảng tính. Và đó cũng là lý do chúng ta cần đến RAG.
RAG (Retrieval-Augmented Generation) là giải pháp giúp bạn:
-
Tự động truy xuất thông tin từ các tệp không có cấu trúc.
-
Tóm tắt nội dung một cách thông minh.
-
Trả lời câu hỏi dựa trên ngữ cảnh thực tế từ dữ liệu bạn cung cấp.
Trong chương này, bạn sẽ:
Làm quen với thư viện LangChain – công cụ chính giúp xử lý tài liệu phi cấu trúc.
Học cách xử lý nhiều loại dữ liệu: Excel, Word, PowerPoint, PDF, EPUB…
Xây dựng hệ thống retrieval từ các tài liệu này.
Tùy chỉnh các hàm để truy xuất và sinh câu trả lời có ý nghĩa từ dữ liệu thực tế.
Kết quả sau chương học:
Bạn sẽ sở hữu bộ công cụ hoàn chỉnh để làm việc với dữ liệu phi cấu trúc: từ việc tải, chia nhỏ văn bản, đến truy xuất thông tin và tạo nội dung có giá trị. Tất cả được áp dụng trong các bài tập thực tế, nhiều coding và ví dụ minh họa rõ ràng.
Dữ liệu phi cấu trúc có mặt ở khắp nơi – email, báo cáo, mạng xã hội, sách điện tử… và khả năng khai thác nó không chỉ là kỹ năng kỹ thuật, mà là một siêu năng lực.
Hãy cùng bắt đầu hành trình này!
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Giới thiệu về Thư viện LangChain – Chìa khóa để xử lý dữ liệu phi cấu trúc
Vì sao cần LangChain?
Ở phần trước, chúng ta đã sử dụng API của OpenAI để xử lý hình ảnh và văn bản. Tuy nhiên, có một vấn đề:
Mỗi trang được xử lý riêng lẻ → Chúng ta bỏ lỡ mối liên kết giữa các trang.
Hãy tưởng tượng nếu điều này xảy ra với cả một tài liệu PowerPoint, một bảng tính Excel, hoặc một cuốn sách điện tử dài hàng trăm trang. Việc chỉ xử lý từng phần riêng biệt là không hiệu quả.
Vì thế, ta cần một công cụ mạnh mẽ hơn. Đó chính là LangChain.
LangChain là gì?
LangChain là một thư viện và framework cực kỳ mạnh mẽ, được thiết kế để:
-
Xây dựng các ứng dụng sử dụng mô hình ngôn ngữ lớn (LLMs).
-
Làm việc với dữ liệu phi cấu trúc như tài liệu, email, ebook, báo cáo, v.v.
-
Tạo ra quy trình xử lý phức tạp một cách dễ dàng, có tổ chức.
Nói đơn giản: LangChain giúp bạn kết nối các bước xử lý dữ liệu lại với nhau – như một chuỗi (chain).
Tại sao nên dùng LangChain?
LangChain được xây dựng để giúp bạn tập trung vào việc trích xuất thông tin, thay vì viết hàng đống đoạn mã rối rắm. Nó cung cấp:
-
Cách tổ chức rõ ràng các bước xử lý (load, chia nhỏ, truy vấn, sinh kết quả).
-
Tích hợp tốt với các mô hình AI như GPT-3.5, GPT-4, và các mô hình khác.
-
Hỗ trợ dữ liệu phi cấu trúc: Excel, Word, PowerPoint, PDF, EPUB...
Các thành phần chính trong LangChain
-
Document Loaders
Dùng để tải các tài liệu từ nhiều định dạng khác nhau (PDF, DOCX, Excel,...) -
Text Splitters
Giúp chia nhỏ văn bản lớn thành từng phần nhỏ, tránh vượt quá giới hạn token của mô hình AI. -
Embeddings
Dùng để chuyển văn bản thành vector, giúp hệ thống hiểu nội dung để tìm kiếm và truy vấn. -
Vector Stores
Là nơi lưu trữ các embedding, giúp truy xuất thông tin nhanh chóng dựa trên nội dung. -
Language Models (LLMs)
Kết nối với mô hình như GPT để tạo câu trả lời, tóm tắt văn bản, viết lại nội dung,...
Kết nối với OpenAI thông qua LangChain
LangChain cho phép bạn cấu hình kết nối đến GPT dễ dàng. Dưới đây là các thông số cơ bản:
| Tham số | Ý nghĩa |
|---|---|
api_key |
Khóa truy cập OpenAI của bạn |
model |
Chọn GPT-3.5, GPT-4,... |
temperature |
Mức độ sáng tạo của kết quả (0 = chính xác, 1 = sáng tạo) |
max_tokens |
Giới hạn độ dài đầu ra |
n |
Số kết quả muốn tạo ra (mặc định là 1) |
stop |
Ký tự/dấu hiệu để dừng sinh văn bản |
presence_penalty |
Phạt nếu từ đã xuất hiện trước đó (giảm lặp lại) |
frequency_penalty |
Phạt nếu từ xuất hiện nhiều lần (kiểm soát tần suất lặp) |
Thực tế, bạn chỉ cần dùng api_key, model, và temperature là đủ để bắt đầu.
LangChain + OpenAI là bộ công cụ mạnh mẽ giúp bạn:
-
Xử lý nhiều loại tài liệu không có cấu trúc.
-
Tự động chia nhỏ và hiểu nội dung văn bản.
-
Truy xuất thông tin theo yêu cầu.
-
Tạo nội dung mới từ dữ liệu cũ.
Sắp tới, chúng ta sẽ đi sâu vào từng phần: từ cách tải tài liệu, chia nhỏ văn bản, đến xây dựng hệ thống tìm kiếm và sinh câu trả lời – tất cả đều thực hành, có ví dụ cụ thể.
Hãy chuẩn bị sẵn máy tính, trình soạn mã và tài liệu cần xử lý. Chúng ta bắt đầu hành trình cùng LangChain!
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Xử lý File Excel Không Cấu Trúc với LangChain
Tình huống thực tế
Hãy tưởng tượng bạn được giao nhiệm vụ phân tích một file Excel khổng lồ chứa đầy các phản hồi của khách hàng.
File này có:
-
Nhiều sheet,
-
Nhiều dòng hữu ích,
-
Nhưng cũng rất nhiều dòng rác hoặc trống.
Làm sao bạn lọc ra thông tin quan trọng từ một “rừng dữ liệu” như vậy?
Đây chính là lúc bạn cần đến LangChain – một thư viện mạnh mẽ giúp xử lý dữ liệu không có cấu trúc.
Mục tiêu của bài học:
Sau bài này, bạn sẽ biết cách:
-
Tải file Excel vào LangChain
-
Chia nhỏ dữ liệu để xử lý tốt hơn
-
Tạo embeddings từ dữ liệu để phục vụ cho phân tích, tìm kiếm hoặc sinh nội dung
Bước 1: Tải dữ liệu Excel
Chúng ta dùng UnstructuredExcelLoader trong module langchain_community.
Cú pháp cơ bản:
from langchain_community.document_loaders import UnstructuredExcelLoader
loader = UnstructuredExcelLoader("reviews.xlsx", mode="elements")
docs = loader.load()
mode="elements" giúp chia nhỏ từng phần trong file Excel.
-
Nếu file của bạn cực kỳ có cấu trúc (ví dụ: bảng biểu đều đặn), bạn có thể thử
mode="table". -
Dữ liệu giống
pandas.read_csv()– chỉ là cách tiếp cận “LangChain-style”.
Bước 2: Chia nhỏ nội dung (Chunking)
Lý do: Các mô hình ngôn ngữ có giới hạn số lượng token. Nếu bạn đưa vào quá nhiều chữ, nó sẽ bị cắt mất nội dung.
Giải pháp: Dùng RecursiveCharacterTextSplitter
from langchain.text_splitter import RecursiveCharacterTextSplitter
splitter = RecursiveCharacterTextSplitter(chunk_size=2000, chunk_overlap=200)
chunks = splitter.split_documents(docs)
-
chunk_size: độ dài mỗi đoạn văn bản.
-
chunk_overlap: phần nội dung lặp lại giữa các đoạn (để giữ ngữ cảnh liền mạch).
Ví dụ:
-
Nếu bạn đặt
chunk_size=2000vàchunk_overlap=200, mỗi đoạn mới sẽ giữ lại 200 ký tự cuối của đoạn trước.
Gợi ý:
-
Nếu dữ liệu của bạn là đánh giá ngắn (reviews), bạn có thể giảm xuống
chunk_size=300,chunk_overlap=50cho tiết kiệm tài nguyên.
Bước 3: Tạo Embeddings (biểu diễn ngữ nghĩa)
Dùng OpenAIEmbeddings từ LangChain để biến các đoạn văn bản thành vector ngữ nghĩa.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(model="text-embedding-3-large")
Mô hình text-embedding-3-large là phiên bản tốt nhất hiện tại của OpenAI.
Lưu ý:
-
API Key cần được bảo mật bằng biến môi trường hoặc file
secrets. -
Nếu bạn muốn tiết kiệm chi phí, có thể dùng model embedding nhẹ hơn hoặc tạo embeddings tùy chỉnh (sẽ học sau).
Tổng kết
Chúng ta đã học:
-
Cách nạp dữ liệu Excel vào LangChain
-
Cách chia nhỏ văn bản để xử lý hiệu quả
-
Cách tạo embeddings để chuẩn bị cho các tác vụ phân tích AI
Từ khóa quan trọng:
-
chunk_sizevàchunk_overlaplà 2 yếu tố then chốt ảnh hưởng đến hiệu quả và độ chính xác.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Thiết lập môi trường xử lý dữ liệu không có cấu trúc với LangChain
Trong phần này, chúng ta sẽ thiết lập môi trường làm việc để xử lý dữ liệu không có cấu trúc bằng thư viện LangChain và các công cụ liên quan.
Chúng ta sẽ thực hiện điều này thông qua Google Colaboratory, một công cụ tuyệt vời để viết và chạy mã Python trực tuyến, đồng thời dễ dàng tích hợp với Google Drive.
Bước 1: Tạo môi trường làm việc trên Google Colab
-
Mở thư mục
unstructured_datatrong dự ánrack -
Nhấn chuột phải → New More → Google Collaboratory
Đây sẽ là nơi bạn viết các đoạn mã để xử lý dữ liệu.
Bước 2: Cài đặt các thư viện cần thiết
Thư viện chính:
-
langchain→ Xử lý dữ liệu và tạo pipeline thông minh -
langchain-community→ Loader cho các định dạng không cấu trúc như Excel, PDF, EPUB... -
openai→ Tạo embeddings, LLM -
faiss-cpu→ Dùng để xây dựng hệ thống truy xuất vector (retrieval system)
!pip install langchain-community langchain openai faiss-cpuBước 3: Thiết lập API Key cho OpenAI
Sử dụng Google Colab, bạn có thể lưu API Key dưới dạng dữ liệu người dùng:
from google.colab import userdata
OPENAI_API_KEY = userdata.get('janai_course')
Bước 4: Kết nối với Google Drive
Google Drive sẽ là nơi chứa các file dữ liệu như .xlsx, .pdf, .docx, .epub...
from google.colab import drive
drive.mount('/content/drive')Sau đó bạn đổi thư mục làm việc sang thư mục dữ liệu:
%cd /content/drive/MyDrive/your-folder-pathBước 5: Import các module quan trọng
# Load dữ liệu Excel
from langchain_community.document_loaders import UnstructuredExcelLoader
# Chia nhỏ dữ liệu
from langchain.text_splitter import RecursiveCharacterTextSplitter
# Gọi LLM và tạo Embeddings
from langchain_openai import ChatOpenAI, OpenAIEmbeddings
# Vector store - FAISS
from langchain.vectorstores.faiss import FAISS
# Hiển thị Markdown trong notebook
from IPython.display import display, MarkdownTổng kết
Trong bài giảng này, bạn đã:
-
Tạo Google Colab notebook cho dự án
-
Cài đặt các thư viện cần thiết cho xử lý dữ liệu không cấu trúc
-
Kết nối API OpenAI
-
Liên kết với Google Drive để truy cập dữ liệu
-
Import các thành phần chính từ LangChain
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Đọc và xử lý dữ liệu Excel với LangChain
Trong bài học này, chúng ta sẽ:
-
Đọc dữ liệu từ file Excel
-
Phân tích và hiển thị dữ liệu
-
Chia nhỏ dữ liệu thành các chunk để chuẩn bị cho việc tạo embeddings
Bước 1: Đọc dữ liệu Excel
Chúng ta sẽ sử dụng UnstructuredExcelLoader từ langchain_community để đọc file reviews.xlsx.
Đây là tập dữ liệu chứa các đánh giá và bình luận đến ngày 21 tháng 8 năm 2024.
from langchain_community.document_loaders import UnstructuredExcelLoader
loader = UnstructuredExcelLoader("reviews.xlsx", mode="elements")
docs = loader.load()
Ghi chú: mode="elements" giúp tách nội dung trong Excel thành các phần tử nhỏ như từng dòng, từng ô – điều này giúp xử lý linh hoạt hơn.
Bước 2: Hiển thị dữ liệu
Hiển thị 5 phần tử đầu tiên để kiểm tra kết quả:
docs[:5]Bạn sẽ thấy một số dữ liệu hiển thị như TD, TR – điều này thể hiện dữ liệu gốc được biểu diễn theo dạng bảng.
Bước 3: Chia nhỏ văn bản (Chunking)
Tại sao cần chunk?
-
Dữ liệu lớn sẽ khó xử lý một lần
-
Embedding có giới hạn độ dài token (vd: 4096 tokens)
-
Chunk nhỏ giúp dễ dàng truy vấn và tìm kiếm hơn
Thực hiện chia nhỏ
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(
chunk_size=2000,
chunk_overlap=200
)
chunks = text_splitter.split_documents(docs)Hiển thị 5 chunk đầu tiên:
chunks[:5]Mẹo:
-
chunk_size=2000có thể thay đổi tùy vào độ dài dữ liệu -
Nếu file rất lớn (nhiều triệu dòng), bạn nên dùng chunk nhỏ hơn hoặc chia theo nội dung logic hơn (theo tiêu đề, đoạn...)
Ghi chú về dữ liệu
Khi hiển thị chunk, có thể bạn sẽ thấy các thẻ như <td> hoặc <tr>:
-
<td>: thể hiện ô trong bảng -
<tr>: thể hiện hàng trong bảng
Điều này là bình thường khi xử lý dữ liệu dạng bảng – bạn có thể lọc hoặc xử lý thêm nếu muốn dữ liệu "sạch" hơn.
Tổng kết
Bạn vừa học cách:
-
Tải dữ liệu từ file Excel bằng LangChain
-
Hiển thị một phần dữ liệu
-
Chia dữ liệu thành các phần nhỏ để chuẩn bị cho bước tiếp theo
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Xây dựng Hệ thống Truy xuất Thông tin với LangChain + OpenAI
Trong bài học này, chúng ta sẽ:
-
Tạo embeddings từ dữ liệu
-
Lưu embeddings vào cơ sở dữ liệu (vector store)
-
Xây dựng một retrieval system – hệ thống tìm kiếm văn bản dựa trên ý nghĩa
-
Truy vấn dữ liệu bằng câu hỏi thực tế
Bước 1: Tạo Embeddings
Chúng ta sẽ dùng mô hình OpenAI text-embedding-3-large để chuyển các chunk văn bản thành vector số.
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings(
model="text-embedding-3-large",
openai_api_key="YOUR_API_KEY"
)
Lưu ý: Tên model cần có dấu gạch ngang (
-) thay vì dấu gạch dưới (_)
Sai:"text_embedding_3_large"→ Đúng:"text-embedding-3-large"
Bước 2: Tạo Vector Store (Database)
Chúng ta lưu các embeddings vào một cơ sở dữ liệu để có thể tìm kiếm lại.
from langchain.vectorstores import FAISS
db = FAISS.from_documents(chunks, embeddings)
Ghi chú: FAISS là một thư viện nhanh và hiệu quả để tìm kiếm vector tương tự.
Bước 3: Truy vấn hệ thống
Bây giờ chúng ta có thể bắt đầu truy vấn hệ thống:
query = "Give me my worst reviews"
results = db.similarity_search_with_score(query, k=5)-
k=5: tìm 5 đoạn văn bản gần nhất với câu hỏi -
Sử dụng cosine similarity để đo độ gần giữa vectors
Cosine Similarity: đo góc giữa hai vector – càng gần nhau, góc càng nhỏ → văn bản càng liên quan
Kết quả Truy vấn
Kết quả sẽ là danh sách các đoạn văn bản giống với truy vấn:
for doc, score in results:
print(doc.page_content, "\nScore:", score)
Bạn có thể thấy dữ liệu có thể còn lộn xộn (ví dụ có <td>, <tr>), điều này sẽ được cải thiện bằng bước xử lý sau.
Giải thích thêm
-
Mỗi chunk có độ dài khoảng
2000 tokensvới200 tokenstrùng lặp giữa các chunk -
Embedding giúp "mã hóa ý nghĩa" của văn bản thành vector
-
Truy vấn sẽ được ánh xạ sang vector và so sánh với các chunk đã mã hóa
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Xây dựng hệ thống RAG với LangChain và OpenAI
Mục tiêu
-
Hiểu cách xử lý dữ liệu từ hệ thống tìm kiếm thông tin (retrieval).
-
Hợp nhất dữ liệu đầu ra từ retrieval để sử dụng trong bước sinh văn bản (generation).
-
Tạo prompt đơn giản để đưa vào mô hình sinh của OpenAI.
-
Tích hợp LangChain để gọi API OpenAI một cách tiện lợi.
-
Đánh giá hiệu suất và giới hạn của mô hình.
1. Tổng quan về bước retrieval
Sau khi hệ thống retrieval trả về kết quả, bạn sẽ nhận được một danh sách các tài liệu (docs_files) tương ứng với truy vấn của bạn.
Cấu trúc dữ liệu
len(docs_files) # số lượng kết quả
docs_files[0] # (page_content, score)-
docs_fileslà danh sách các tuple. -
Mỗi tuple gồm:
-
page_content: nội dung văn bản. -
score: điểm số đánh giá mức độ liên quan.
-
2. Hợp nhất văn bản để dùng trong bước generation
Trước khi sinh câu trả lời, chúng ta cần ghép các page_content thành một khối văn bản lớn:
context_text = "\n\n".join([doc.page_content for doc, score in docs_files])Mục đích:
-
Tạo bối cảnh thống nhất cho mô hình sinh văn bản.
-
Dễ dàng truyền vào prompt.
3. Tạo prompt đơn giản cho mô hình sinh
prompt = f"""Based on this context:
{context_text}
Please answer this question:
{query}
If you don’t know the answer, just say you don’t know."""Lưu ý:
-
Luôn khuyến khích mô hình trả lời "không biết" nếu không có thông tin.
-
Tránh hiện tượng "hallucination" (mô hình bịa ra thông tin).
4. Gọi OpenAI API thông qua LangChain
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI(
openai_api_key=API_KEY,
model_name="gpt-4o",
temperature=0
)-
Sử dụng GPT-4o cho hiệu suất tốt hơn.
-
temperature = 0để đảm bảo tính chính xác, không sáng tạo.
5. Thực thi truy vấn và hiển thị kết quả
response_text = model.invoke(prompt).content
display(Markdown(response_text))-
Gọi mô hình để sinh câu trả lời dựa trên
prompt. -
Hiển thị dưới dạng Markdown để dễ đọc.
6. Phân tích và đánh giá kết quả
-
Kết quả chưa hoàn hảo: trả về "no comment" hoặc thông tin không đầy đủ.
-
Lý do:
-
Prompt chưa tối ưu.
-
Dữ liệu quá nhiều (2000 tokens x 5 docs).
-
Truy vấn chưa rõ ràng ("Give me my worst reviews with comments").
-
7. Hướng phát triển tiếp theo
-
Tối ưu prompt để rõ ràng hơn (VD: yêu cầu kèm comment cụ thể).
-
Giới hạn context hoặc lọc dữ liệu trước khi truyền vào mô hình.
-
Tạo các hàm tái sử dụng cho quá trình merge, prompt, gọi API.
8. Kết luận
Dù chưa tối ưu, nhưng bạn đã hoàn tất một pipeline RAG đơn giản:
-
Tìm kiếm thông tin (Retrieval): trả về các đoạn văn bản liên quan.
-
Ghép context: tạo ngữ cảnh thống nhất.
-
Sinh văn bản (Generation): mô hình trả lời dựa vào context và truy vấn.
Tác giả: Đỗ Ngọc Tú
Công Ty Phần Mềm VHTSoft
Fine-Tuning
Giải thích chi tiết và dễ hiểu về Fine-Tuning trong lĩnh vực mô hình ngôn ngữ (LLM):
Fine-Tuning là gì
Fine-tuning là quá trình đào tạo lại (huấn luyện tiếp) một mô hình ngôn ngữ đã được huấn luyện trước (pre-trained) trên dữ liệu cụ thể của bạn, để mô hình:
-
Hiểu tốt hơn về lĩnh vực bạn quan tâm (ví dụ: y tế, pháp lý, kỹ thuật...),
-
Trả lời chính xác và phù hợp hơn với yêu cầu của ứng dụng thực tế,
-
Tuân theo phong cách viết, giọng điệu hoặc cấu trúc riêng.
Ví dụ dễ hiểu
Giả sử bạn có một mô hình GPT đã học hàng tỷ câu văn từ Internet. Nếu bạn muốn nó:
-
Trả lời theo cách nghiêm túc, ngắn gọn, kỹ thuật,
-
Hoặc chuyên trả lời câu hỏi về luật Việt Nam,
thì bạn sẽ fine-tune nó bằng cách huấn luyện thêm trên tập dữ liệu nhỏ gồm các ví dụ bạn mong muốn.
Fine-tuning khác với Prompt Engineering thế nào?
| Prompt Engineering | Fine-Tuning |
|---|---|
| Thay đổi prompt để điều khiển đầu ra | Huấn luyện lại mô hình để thay đổi hành vi |
| Không tốn chi phí đào tạo lại | Tốn tài nguyên (GPU, RAM, thời gian) |
| Dễ làm, nhưng hiệu quả có giới hạn | Mạnh hơn, dùng cho yêu cầu phức tạp |
| Không cần dữ liệu huấn luyện | Cần dữ liệu huấn luyện có nhãn |
Có mấy loại Fine-Tuning?
1. Full Fine-Tuning (ít dùng với LLM lớn)
-
Cập nhật toàn bộ trọng số (weights) của mô hình.
-
Yêu cầu nhiều tài nguyên → không hiệu quả với mô hình lớn như LLaMA-2-13B, GPT-J...
2. PEFT (Parameter-Efficient Fine-Tuning) – [rất phổ biến hiện nay]
Gồm các kỹ thuật như:
-
LoRA (Low-Rank Adaptation)
-
QLoRA (LoRA kết hợp nén và huấn luyện trên GPU yếu hơn)
-
Prefix Tuning, Adapter Tuning...
Ưu điểm:
-
Chỉ fine-tune rất ít tham số (~0.1%-1%) → tiết kiệm chi phí và tài nguyên.
-
Có thể lưu nhiều “bản cập nhật nhỏ” cho các mục tiêu khác nhau.
QLoRA là gì?
QLoRA = LoRA + Quantization (4-bit)
Mục tiêu là fine-tune mô hình lớn (ví dụ: LLaMA-2-13B) trên laptop hoặc GPU yếu.
-
Quantization: giảm độ chính xác xuống 4-bit để tiết kiệm RAM/GPU.
-
LoRA: chèn các lớp nhỏ để học thêm nhưng không thay đổi mô hình gốc.
Rất phổ biến để fine-tune mô hình lớn với ngân sách thấp!
Khi nào nên fine-tune?
| Trường hợp | Có nên fine-tune? |
|---|---|
| Muốn mô hình hiểu văn bản nội bộ, tài liệu chuyên ngành | Có |
| Muốn mô hình trả lời theo phong cách riêng | Có |
| Chỉ cần thay đổi nhẹ câu trả lời | ❌ Dùng prompt thôi là đủ |
| Không có dữ liệu huấn luyện | ❌ Không fine-tune được |
Các công cụ hỗ trợ Fine-tuning
-
Hugging Face Transformers + PEFT + TRL (Python, rất phổ biến)
-
LoRA, QLoRA với bitsandbytes
-
OpenAI Fine-tuning API (với GPT-3.5-Turbo)
-
Axolotl, SFTTrainer, AutoTrain...
Transformers
Transformers là một kiến trúc mạng nơ-ron (neural network architecture) được giới thiệu bởi Google trong bài báo nổi tiếng năm 2017:
"Attention is All You Need".
Nó thay thế hoàn toàn RNN/LSTM trong việc xử lý chuỗi dữ liệu (như văn bản), và trở thành nền tảng cho hầu hết các mô hình ngôn ngữ hiện đại (LLM).
Ý tưởng cốt lõi: Attention
Điểm mạnh của Transformers là cơ chế Attention, cụ thể là Self-Attention.
Giả sử bạn có câu:
"The cat sat on the mat because it was tired."
Từ "it" cần hiểu là đang nói đến "the cat".
Cơ chế attention giúp mô hình xác định được từ nào trong câu liên quan nhất đến từ hiện tại.
Cấu trúc của Transformer
Có 2 phần chính:
1. Encoder (bộ mã hóa)
-
Dùng trong BERT, T5 (phần mã hóa).
-
Hiểu toàn bộ ngữ cảnh của chuỗi đầu vào.
2. Decoder (bộ giải mã)
-
Dùng trong GPT, T5 (phần sinh văn bản).
-
Dự đoán từ tiếp theo dựa trên các từ trước đó.
Tóm tắt:
| Mô hình | Dùng phần nào? |
|---|---|
| BERT | Encoder |
| GPT | Decoder |
| T5 | Encoder + Decoder |
Thành phần chính trong mỗi layer
-
Multi-Head Self Attention
-
Cho phép mô hình "chú ý" đến nhiều phần khác nhau của câu cùng lúc.
-
-
Feed-Forward Neural Network
-
Một MLP đơn giản sau mỗi attention.
-
-
Layer Normalization
-
Giúp mô hình ổn định trong quá trình huấn luyện.
-
-
Residual Connections
-
Giúp tránh mất thông tin và tăng hiệu quả học.
-
Vị trí từ (Positional Encoding)
Transformers không có khái niệm tuần tự như RNN.
→ Phải thêm thông tin vị trí bằng Positional Encoding để mô hình biết thứ tự từ trong câu.
Vì sao Transformers lại mạnh?
-
Huấn luyện song song (không tuần tự như RNN) → nhanh hơn rất nhiều.
-
Tăng khả năng học ngữ cảnh xa (không bị "quên" từ đầu câu).
-
Học được từ dữ liệu lớn, dẫn đến khả năng tổng quát mạnh mẽ.
Hugging Face Transformers là gì?
Đây là thư viện mã nguồn mở giúp bạn dễ dàng:
-
Sử dụng các mô hình transformer như BERT, GPT, T5, LLaMA...
-
Dùng để fine-tune, huấn luyện, đánh giá mô hình.
-
Tích hợp với datasets, tokenizers, và PEFT (fine-tuning hiệu quả).
Ví dụ sử dụng nhanh (với Hugging Face):
from transformers import pipeline
qa = pipeline("question-answering", model="distilbert-base-cased-distilled-squad")
qa({
"context": "The cat sat on the mat because it was tired.",
"question": "Why did the cat sit on the mat?"
})
Tóm tắt dễ nhớ
| Thuật ngữ | Ý nghĩa ngắn gọn |
|---|---|
| Transformer | Kiến trúc xử lý chuỗi mạnh mẽ, thay thế RNN |
| Attention | Cơ chế "chú ý" đến phần quan trọng của chuỗi |
| Self-Attention | Mỗi từ chú ý đến các từ khác trong chuỗi |
| Encoder / Decoder | Mã hóa / Sinh văn bản |
| Hugging Face | Thư viện dễ dùng để tận dụng mô hình này |
Fine-Tuning trong hệ thống RAG
Fine-tuning đóng vai trò rất quan trọng trong việc nâng cao chất lượng của hệ thống RAG (Retrieval-Augmented Generation). Dưới đây là cách ứng dụng Fine-Tuning cho từng phần trong hệ thống RAG, kèm theo ví dụ và hướng dẫn triển khai.
Tổng quan về hệ thống RAG
Một hệ thống RAG gồm 2 thành phần chính:
-
Retriever: Truy xuất các đoạn văn bản liên quan từ kho dữ liệu.
-
Generator (LLM): Sinh câu trả lời dựa trên văn bản đã truy xuất.
Fine-tuning có thể được áp dụng cho retriever, generator, hoặc cả hai để cải thiện độ chính xác và tính hữu ích của câu trả lời.
1. Fine-Tuning Retriever
Mục tiêu:
-
Giúp retriever tìm đúng các đoạn văn bản liên quan hơn đến câu hỏi của người dùng.
Cách làm:
-
Sử dụng các cặp dữ liệu
query <-> relevant passage. -
Huấn luyện mô hình bi-encoder (ví dụ:
sentence-transformers) để embedding câu hỏi và tài liệu gần nhau trong không gian vector.
Công cụ:
-
sentence-transformers(Hugging Face) -
Datasets: Haystack, BEIR, custom Q&A pairs
Ví dụ:
from sentence_transformers import SentenceTransformer, InputExample, losses
from torch.utils.data import DataLoader
train_examples = [
InputExample(texts=["What is the capital of France?", "Paris is the capital of France."]),
...
]
model = SentenceTransformer('sentence-transformers/all-MiniLM-L6-v2')
train_dataloader = DataLoader(train_examples, batch_size=16)
train_loss = losses.MultipleNegativesRankingLoss(model)
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1)
2. Fine-Tuning Generator (LLM)
Mục tiêu:
-
Giúp LLM sinh ra câu trả lời chính xác hơn dựa trên context truy xuất được.
Cách làm:
-
Sử dụng tập dữ liệu gồm:
context,question, vàanswer. -
Fine-tune LLM như
T5,GPT-2,Mistral,LLaMAtrên các cặpinput: context + question → output: answer.
Công cụ:
-
Hugging Face Transformers
-
PEFT / LoRA / QLoRA để fine-tune mô hình lớn nhẹ hơn
Ví dụ:
from transformers import T5Tokenizer, T5ForConditionalGeneration, Trainer, TrainingArguments
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
def preprocess(example):
input_text = f"question: {example['question']} context: {example['context']}"
target_text = example["answer"]
return tokenizer(input_text, truncation=True, padding="max_length", max_length=512), \
tokenizer(target_text, truncation=True, padding="max_length", max_length=64)
# Sử dụng Trainer API để fine-tune
3. Fine-Tuning kết hợp Retriever + Generator
-
Một số framework (như Haystack, RAG) hỗ trợ fine-tune toàn bộ pipeline end-to-end.
-
Tuy nhiên, việc này đắt đỏ và phức tạp hơn → nên ưu tiên fine-tune từng phần riêng trước.
Khi nào nên Fine-Tune trong RAG?
| Dấu hiệu | Giải pháp |
|---|---|
| Truy xuất sai tài liệu | Fine-tune retriever |
| Sinh câu trả lời sai / không khớp | Fine-tune generator |
| Cần tối ưu cho domain cụ thể | Fine-tune cả hai |
Tools hỗ trợ Fine-tuning RAG
| Thành phần | Fine-tuning giúp gì? |
|---|---|
| Retriever | Tìm đúng đoạn tài liệu liên quan |
| Generator | Sinh câu trả lời chính xác hơn từ context |
| Toàn hệ thống | Tối ưu hóa end-to-end, tăng chất lượng RAG |
Tóm tắt:
| Thành phần | Fine-tuning giúp gì? |
|---|---|
| Retriever | Tìm đúng đoạn tài liệu liên quan |
| Generator | Sinh câu trả lời chính xác hơn từ context |
| Toàn hệ thống | Tối ưu hóa end-to-end, tăng chất lượng RAG |
Dự án RAG Retriever + Generator Fine-Tuning
Dưới đây là một template RAG đầy đủ (Retriever + Generator) có hỗ trợ Fine-Tuning cả hai phần: Retriever (bi-encoder) và Generator (T5 hoặc LLaMA). Mình sẽ chia thành từng bước rõ ràng:
Cấu trúc thư mục đề xuất
rag_finetuning_project/
├── data/
│ └── train.jsonl
├── retriever/
│ ├── train_retriever.py
│ └── model/
├── generator/
│ ├── train_generator.py
│ └── model/
├── rag_pipeline.py
└── requirements.txt
1. Dataset format
data/train.jsonl:
{"question": "What is the capital of France?", "context": "Paris is the capital of France.", "answer": "Paris"}
{"question": "What is the currency of Japan?", "context": "The yen is the official currency of Japan.", "answer": "yen"}
...
2. Fine-Tune Retriever (retriever/train_retriever.py)
Sử dụng sentence-transformers.
from sentence_transformers import SentenceTransformer, InputExample, losses
from torch.utils.data import DataLoader
import json
# Load data
examples = []
with open("../data/train.jsonl", "r") as f:
for line in f:
ex = json.loads(line)
examples.append(InputExample(texts=[ex["question"], ex["context"]]))
# Load model
model = SentenceTransformer("sentence-transformers/all-MiniLM-L6-v2")
train_dataloader = DataLoader(examples, batch_size=16)
train_loss = losses.MultipleNegativesRankingLoss(model)
# Train
model.fit(train_objectives=[(train_dataloader, train_loss)], epochs=1, output_path="model/")
3. Fine-Tune Generator (generator/train_generator.py)
Sử dụng T5 từ Hugging Face Transformers.
from transformers import T5Tokenizer, T5ForConditionalGeneration, Trainer, TrainingArguments
from datasets import load_dataset
import json
def load_data():
data = []
with open("../data/train.jsonl", "r") as f:
for line in f:
ex = json.loads(line)
input_text = f"question: {ex['question']} context: {ex['context']}"
data.append({"input": input_text, "label": ex["answer"]})
return data
data = load_data()
from datasets import Dataset
dataset = Dataset.from_list(data)
tokenizer = T5Tokenizer.from_pretrained("t5-small")
model = T5ForConditionalGeneration.from_pretrained("t5-small")
def preprocess(examples):
model_input = tokenizer(examples["input"], truncation=True, padding="max_length", max_length=512)
with tokenizer.as_target_tokenizer():
labels = tokenizer(examples["label"], truncation=True, padding="max_length", max_length=32)
model_input["labels"] = labels["input_ids"]
return model_input
tokenized = dataset.map(preprocess, batched=True)
args = TrainingArguments(
output_dir="model/",
evaluation_strategy="no",
per_device_train_batch_size=4,
num_train_epochs=3,
save_strategy="epoch",
)
trainer = Trainer(
model=model,
args=args,
train_dataset=tokenized,
tokenizer=tokenizer,
)
trainer.train()
4. Tích hợp Retriever + Generator (rag_pipeline.py)
from sentence_transformers import SentenceTransformer, util
from transformers import T5Tokenizer, T5ForConditionalGeneration
retriever = SentenceTransformer("retriever/model")
generator = T5ForConditionalGeneration.from_pretrained("generator/model")
tokenizer = T5Tokenizer.from_pretrained("t5-small")
# Fake corpus (ở thực tế sẽ là hàng ngàn documents)
corpus = [
"Paris is the capital of France.",
"Tokyo is the capital of Japan.",
"The yen is the currency of Japan.",
]
corpus_embeddings = retriever.encode(corpus, convert_to_tensor=True)
def rag_answer(question):
question_embedding = retriever.encode(question, convert_to_tensor=True)
top_hit = util.semantic_search(question_embedding, corpus_embeddings, top_k=1)[0][0]
context = corpus[top_hit['corpus_id']]
input_text = f"question: {question} context: {context}"
input_ids = tokenizer(input_text, return_tensors="pt", truncation=True).input_ids
output_ids = generator.generate(input_ids)
return tokenizer.decode(output_ids[0], skip_special_tokens=True)
# Ví dụ:
print(rag_answer("What is the capital of France?"))
requirements.txt
transformers
datasets
sentence-transformers
torch
Tùy chọn nâng cao
-
Thay T5 bằng LLaMA/Mistral với QLoRA → sử dụng
PEFT. -
Sử dụng LangChain hoặc Haystack để xây dựng UI / chatbot interface.
-
Sử dụng FAISS hoặc Weaviate cho truy vấn triệu tài liệu.
Flan-T5
Flan-T5 là một mô hình ngôn ngữ do Google huấn luyện, thuộc họ T5 (Text-To-Text Transfer Transformer).
Tên đầy đủ: "Fine-tuned LAnguage Net T5"
Nó là T5 được huấn luyện lại (fine-tune) để trả lời câu hỏi tốt hơn, chính xác hơn, và hiểu lệnh tốt hơn.
Cấu trúc cơ bản
Flan-T5 sử dụng mô hình T5 gốc – một Transformer với kiến trúc Encoder-Decoder:
-
Encoder: Hiểu văn bản đầu vào.
-
Decoder: Sinh văn bản đầu ra.
Và mọi thứ đều được xử lý dưới dạng text → text.
Ví dụ:
| Input | Output |
|---|---|
| "Translate English to French: Hello" | "Bonjour" |
| "Summarize: Hôm nay trời đẹp..." | "Trời đẹp hôm nay." |
| "What is the capital of Japan?" | "Tokyo" |
Flan-T5 có gì đặc biệt?
Flan-T5 = T5 + fine-tuning thêm hàng loạt tác vụ hướng lệnh (instruction tuning)
Những điểm cải tiến:
-
Instruction tuning:
Flan-T5 được huấn luyện để hiểu lệnh rõ ràng, ví dụ như:-
“Tóm tắt văn bản sau…”
-
“Dịch sang tiếng Đức…”
-
“Viết lại đoạn văn cho dễ hiểu…”
-
-
Đa nhiệm (multi-task learning):
Huấn luyện trên hơn 1000 loại tác vụ NLP khác nhau. -
Nhiều kích thước:
-
flan-t5-small,flan-t5-base,flan-t5-large,flan-t5-xl,flan-t5-xxl(lớn nhất ~11B tham số)
-
-
Dễ dùng, mã nguồn mở:
-
Có sẵn trên Hugging Face
-
Chỉ cần vài dòng code để sử dụng.
-
Ví dụ dùng Flan-T5 với Python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("google/flan-t5-base")
tokenizer = AutoTokenizer.from_pretrained("google/flan-t5-base")
input_text = "Translate English to Vietnamese: How are you?"
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))
Kết quả: "Bạn khỏe không?"
Tóm tắt
| Tiêu chí | Flan-T5 |
|---|---|
| Thuộc loại | Transformer (T5 – Encoder-Decoder) |
| Do ai tạo | |
| Mục tiêu | Giải quyết đa nhiệm NLP theo lệnh |
| Cách hoạt động | Text in → Text out |
| Ưu điểm chính | Hiểu tốt câu lệnh, đa nhiệm, dễ fine-tune |
Flan-T5 với RAG
Dưới đây là một bài thực hành chi tiết giúp bạn xây dựng hệ thống RAG (Retrieval-Augmented Generation) sử dụng mô hình Flan-T5 để trả lời câu hỏi dựa trên tài liệu PDF. Hệ thống này sẽ:
-
Trích xuất nội dung từ tệp PDF.
-
Chia nhỏ văn bản thành các đoạn (chunk) và tạo vector embedding cho từng đoạn.
-
Lưu trữ các vector trong cơ sở dữ liệu FAISS để truy vấn nhanh chóng.
-
Truy xuất các đoạn văn bản liên quan đến câu hỏi người dùng.
-
Sử dụng Flan-T5 để sinh câu trả lời dựa trên ngữ cảnh truy xuất được.
Môi trường và thư viện cần thiết
Trước tiên, hãy cài đặt các thư viện cần thiết:
pip install transformers sentence-transformers faiss-cpu pypdf1. Trích xuất văn bản từ PDF
from pypdf import PdfReader
def extract_text_from_pdf(pdf_path):
reader = PdfReader(pdf_path)
text = ""
for page in reader.pages:
text += page.extract_text()
return text
2. Chia văn bản thành các đoạn nhỏ (chunk)
def split_text(text, chunk_size=500, overlap=50):
chunks = []
start = 0
while start < len(text):
end = start + chunk_size
chunks.append(text[start:end])
start += chunk_size - overlap
return chunks
3. Tạo vector embedding cho từng đoạn văn bản
from sentence_transformers import SentenceTransformer
def create_embeddings(chunks):
model = SentenceTransformer('all-MiniLM-L6-v2')
embeddings = model.encode(chunks)
return embeddings, model
4. Lưu trữ embeddings trong FAISS5. Truy xuất các đoạn văn bản liên quan đến câu hỏi
def retrieve_relevant_chunks(question, model, index, chunks, top_k=3):
question_embedding = model.encode([question])
distances, indices = index.search(np.array(question_embedding), top_k)
retrieved_chunks = [chunks[i] for i in indices[0]]
return retrieved_chunks
6. Sinh câu trả lời bằng Flan-T5
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
def generate_answer(question, context, model_name="google/flan-t5-base"):
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
prompt = f"Context: {context}\n\nQuestion: {question}\n\nAnswer:"
inputs = tokenizer(prompt, return_tensors="pt", truncation=True)
outputs = model.generate(**inputs, max_new_tokens=100)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answer
7. Kết hợp tất cả thành một pipeline
def rag_pipeline(pdf_path, question):
# Bước 1: Trích xuất và xử lý văn bản
text = extract_text_from_pdf(pdf_path)
chunks = split_text(text)
# Bước 2: Tạo embeddings và index
embeddings, embed_model = create_embeddings(chunks)
index = create_faiss_index(np.array(embeddings))
# Bước 3: Truy xuất các đoạn liên quan
relevant_chunks = retrieve_relevant_chunks(question, embed_model, index, chunks)
context = " ".join(relevant_chunks)
# Bước 4: Sinh câu trả lời
answer = generate_answer(question, context)
return answer
Ví dụ sử dụng
pdf_path = "duong-luoi-bo.pdf"
question = "Tranh chấp ở Biển Đông bắt đầu từ khi nào?"
answer = rag_pipeline(pdf_path, question)
print("Câu trả lời:", answer)
Gợi ý nâng cao
-
Tăng hiệu suất: Sử dụng
faiss-gpunếu bạn có GPU. -
Cải thiện chất lượng câu trả lời: Fine-tune Flan-T5 trên tập dữ liệu của bạn.
-
Giao diện người dùng: Tích hợp với Gradio hoặc Streamlit để tạo giao diện thân thiện.
Các công cụ
LangSmith, Promptfoo, và TruLens
1. LangSmith – Giám sát và kiểm thử pipelines trong LangChain
LangSmith là một nền tảng được phát triển bởi LangChain giúp bạn:
-
Ghi lại và giám sát các pipeline tương tác với LLM.
-
Kiểm tra và đánh giá chất lượng các lời gọi đến LLM.
-
Phát hiện lỗi, theo dõi hiệu suất và so sánh prompt/agent chains.
Tính năng chính:
-
Trace toàn bộ luồng hoạt động trong LangChain (gồm các agent, tool, retriever…).
-
Compare giữa các phiên bản prompt hoặc mô hình.
-
Test Suites: tạo và chạy bộ test trên các prompt.
-
Feedback System: thêm đánh giá thủ công hoặc tự động.
Dùng khi:
-
Bạn đang dùng LangChain để xây dựng app dùng LLM.
-
Muốn kiểm tra, debug hoặc theo dõi các phiên bản của mô hình/prompt.
2. Promptfoo – Kiểm thử và benchmark các prompt
Promptfoo là một công cụ dòng lệnh và dashboard giúp bạn kiểm thử (test), so sánh (benchmark) và đánh giá hiệu suất của prompt.
Tính năng chính:
-
Viết test cases giống như unit tests cho prompt.
-
So sánh nhiều mô hình (GPT-4, Claude, Mistral…) với cùng một prompt.
-
Đo hiệu suất (latency, độ dài, token usage, v.v).
-
Hỗ trợ tích hợp CI/CD – kiểm thử prompt tự động mỗi lần đẩy mã.
Ví dụ:
Bạn có thể viết một test YAML:
prompts:
- "Summarize: {{input}}"
tests:
- input: "This is a very long article about..."
expected_output: "A short summary"
promptfoo testDùng khi:
-
Muốn so sánh đầu ra từ nhiều mô hình hoặc nhiều phiên bản prompt.
-
Muốn đảm bảo chất lượng prompt trước khi đưa vào production.
3. TruLens – Giám sát và đánh giá đạo đức, độ tin cậy, tính đúng đắn của LLM
TruLens là một framework mã nguồn mở giúp bạn:
-
Đánh giá chất lượng đầu ra LLM (như factuality, relevance, toxicity…).
-
Tích hợp feedback tự động (qua các đánh giá rule-based hoặc LLM-based).
-
Ghi lại lịch sử lời gọi API và visual hóa qua dashboard.
Tính năng chính:
-
Instrumenting: thêm ghi chú (instrumentation) vào app sử dụng LLM (OpenAI, LangChain...).
-
Evaluation: cung cấp thước đo sẵn như:
-
Groundedness (tính gắn với dữ liệu truy xuất)
-
Harmfulness
-
Answer relevance
-
-
TruLens App: Giao diện trực quan để duyệt và phân tích.
Dùng khi:
-
Muốn theo dõi độ đúng đắn và đạo đức của LLM app.
-
Cần đo lường LLM có sinh ra phản hồi sai, lệch, gây hiểu nhầm không.
So sánh nhanh:
| Công cụ | Mục tiêu chính | Điểm mạnh | Khi nào dùng? |
|---|---|---|---|
| LangSmith | Giám sát & kiểm thử pipeline LLM (LangChain) | Giao diện mạnh, có trace | Khi dùng LangChain |
| Promptfoo | Benchmark & test prompt | CLI, CI/CD, so sánh nhiều mô hình | Khi muốn kiểm thử prompt |
| TruLens | Đánh giá đầu ra LLM (relevance, safety) | Tích hợp đánh giá đạo đức, factual | Khi cần đo lường chất lượng LLM |
Hugging Face Transformers, PEFT, LoRA, và QLoRA
Hugging Face Transformers
Hugging Face Transformers là một thư viện mã nguồn mở nổi tiếng cung cấp các mô hình ngôn ngữ hiện đại (LLMs) đã được huấn luyện sẵn như BERT, GPT, T5, RoBERTa, BLOOM, v.v.
Thư viện này hỗ trợ nhiều tác vụ NLP như: phân loại văn bản, sinh văn bản, dịch, hỏi đáp, v.v.
Ưu điểm:
-
Dễ sử dụng với API thống nhất.
-
Có kho mô hình (model hub) phong phú trên https://huggingface.co/models.
-
Tương thích với PyTorch, TensorFlow, JAX.
PEFT (Parameter-Efficient Fine-Tuning)
PEFT là viết tắt của Parameter-Efficient Fine-Tuning, tức là kỹ thuật tinh chỉnh mô hình một cách tiết kiệm tham số.
Thay vì tinh chỉnh toàn bộ mô hình (gồm hàng trăm triệu đến hàng tỷ tham số), PEFT chỉ cập nhật một phần nhỏ, giúp:
-
Tiết kiệm bộ nhớ.
-
Nhanh hơn khi huấn luyện.
-
Dễ dàng áp dụng với các mô hình lớn.
PEFT phổ biến trong các trường hợp bạn muốn cá nhân hóa mô hình hoặc áp dụng mô hình vào một domain cụ thể mà không cần tốn quá nhiều tài nguyên.
LoRA (Low-Rank Adaptation)
LoRA là một kỹ thuật cụ thể trong PEFT, được dùng để thêm các ma trận học nhỏ (low-rank matrices) vào một số lớp của mô hình.
Thay vì cập nhật toàn bộ ma trận trọng số, LoRA chỉ học một phần nhỏ thay thế.
Cách hoạt động:
-
Chèn thêm hai ma trận A và B nhỏ (low-rank) vào trong quá trình huấn luyện.
-
Trọng số gốc không thay đổi, chỉ có A và B được học.
-
Khi suy luận (inference), các ma trận này sẽ kết hợp lại để mô phỏng hành vi đã tinh chỉnh.
Ưu điểm:
-
Ít tham số cần huấn luyện (ví dụ chỉ 1-2% so với full fine-tuning).
-
Có thể chia sẻ hoặc swap các phần LoRA như plugin.
QLoRA (Quantized LoRA)
QLoRA là sự kết hợp giữa:
-
LoRA (để tinh chỉnh một phần nhỏ).
-
Quantization (lượng tử hóa) – giảm số bit dùng để lưu trọng số mô hình (ví dụ từ float32 xuống int4).
QLoRA cho phép bạn:
-
Tinh chỉnh các mô hình rất lớn (7B, 13B, 65B tham số) trên GPU thương mại như 1 x 24GB VRAM.
-
Sử dụng ít RAM, ít GPU.
-
Đạt hiệu suất gần như tinh chỉnh đầy đủ.
QLoRA đã được dùng trong nhiều mô hình hiệu suất cao như Guanaco, RedPajama, v.v.
Tổng kết:
| Thuật ngữ | Ý nghĩa | Lợi ích chính |
|---|---|---|
| Transformers | Thư viện mô hình NLP mạnh mẽ | Dễ sử dụng, nhiều mô hình sẵn |
| PEFT | Tinh chỉnh tiết kiệm tham số | Nhanh, tiết kiệm tài nguyên |
| LoRA | Cách tinh chỉnh trong PEFT | Chỉ học ma trận nhỏ, hiệu quả |
| QLoRA | LoRA + lượng tử hóa mô hình | Tinh chỉnh mô hình lớn trên máy nhỏ |
Thực hành LangSmith
LangSmith là gì?
LangSmith là một nền tảng giúp bạn:LangSmith
-
Theo dõi (tracing): Ghi lại toàn bộ quá trình thực thi của ứng dụng LLM.
-
Đánh giá (evaluation): Đánh giá chất lượng đầu ra của mô hình.
-
Kỹ thuật prompt (prompt engineering): Quản lý và tối ưu hóa các prompt.
-
Giám sát (observability): Theo dõi hiệu suất và hành vi của ứng dụng.LangSmith
LangSmith có thể được sử dụng độc lập hoặc tích hợp với LangChain để xây dựng và triển khai các ứng dụng LLM chất lượng cao.
Bước 1: Cài đặt và cấu hình
1.1 Cài đặt thư viện cần thiết
pip install langsmith openai1.2 Tạo tài khoản và API Key
-
Truy cập LangSmith và đăng ký tài khoản.
-
Sau khi đăng nhập, vào phần Settings và tạo một API Key.Introduction | 🦜️🔗 LangChain+5LangSmith+5YouTube+5LangSmith+1Medium+1
1.3 Thiết lập biến môi trường
export LANGSMITH_TRACING=true
export LANGSMITH_API_KEY="your-langsmith-api-key"
export OPENAI_API_KEY="your-openai-api-key"
Bước 2: Tạo ứng dụng mẫu và ghi lại quá trình thực thi
2.1 Định nghĩa ứng dụng mẫu
from langsmith import traceable
from langsmith.wrappers import wrap_openai
from openai import OpenAI
# Bọc OpenAI client để ghi lại các cuộc gọi
openai_client = wrap_openai(OpenAI())
# Hàm truy xuất tài liệu (giả lập)
def retriever(query: str):
return ["Harrison worked at Kensho"]
# Hàm chính thực hiện RAG
@traceable
def rag(question: str):
docs = retriever(question)
system_message = f"Answer the user's question using only the provided information below:\n\n{docs[0]}"
response = openai_client.chat.completions.create(
messages=[
{"role": "system", "content": system_message},
{"role": "user", "content": question},
],
model="gpt-4o-mini",
)
return response.choices[0].message.content
# Gọi hàm và in kết quả
answer = rag("Where did Harrison work?")
print("Answer:", answer)
2.2 Xem trace trên LangSmith
Sau khi chạy mã, truy cập LangSmith để xem chi tiết trace của ứng dụng.LangSmith+3LangSmith+3YouTube+3
Bước 3: Đánh giá ứng dụng với LangSmith
3.1 Tạo tập dữ liệu đánh giá
from langsmith import Client
client = Client()
dataset = client.create_dataset(
name="agent-qa-demo",
description="Dataset for evaluating the RAG application."
)
# Thêm dữ liệu vào tập
examples = [
{"input": {"question": "Where did Harrison work?"}, "output": "Harrison worked at Kensho."},
{"input": {"question": "What company did Harrison work for?"}, "output": "Kensho"},
]
for example in examples:
client.create_example(
inputs=example["input"],
outputs={"answer": example["output"]},
dataset_id=dataset.id
)
3.2 Chạy đánh giá trên tập dữ liệu
from langsmith.evaluation import run_on_dataset
import functools
# Định nghĩa hàm tạo ứng dụng
def create_rag_app():
return functools.partial(rag)
# Chạy đánh giá
results = run_on_dataset(
dataset_name="agent-qa-demo",
llm_or_chain_factory=create_rag_app(),
evaluation="qa",
client=client,
project_name="rag-evaluation-demo"
)
3.3 Phân tích kết quả
Sau khi đánh giá hoàn tất, bạn có thể xem kết quả chi tiết trên giao diện LangSmith, bao gồm:
-
Các trace của từng lần chạy.
-
Điểm số đánh giá.
-
Phản hồi từ người dùng (nếu có).Introduction | 🦜️🔗 LangChainLearn R, Python & Data Science Online+1YouTube+1
Bước 4: Tùy chỉnh và mở rộng
-
Tích hợp với LangChain: Nếu bạn sử dụng LangChain, LangSmith có thể tích hợp trực tiếp để ghi lại trace của các chain và agent.
-
Tạo dashboard tùy chỉnh: LangSmith cho phép bạn tạo các dashboard để giám sát các chỉ số quan trọng như chi phí, độ trễ và chất lượng phản hồi.
-
Thu thập phản hồi từ người dùng: Bạn có thể thu thập phản hồi từ người dùng cuối để cải thiện ứng dụng.
Bài thực hành Promptfoo cơ bản
Dưới đây là bài thực hành Promptfoo cơ bản để giúp bạn bắt đầu đánh giá và so sánh các prompt sử dụng mô hình ngôn ngữ (LLM). promptfoo rất hữu ích trong việc tối ưu prompt, benchmark nhiều model khác nhau, và kiểm thử các thay đổi trong ứng dụng sử dụng LLM.
MỤC TIÊU
-
Sử dụng Promptfoo để benchmark các prompt.
-
So sánh output giữa nhiều mô hình như
gpt-3.5-turbovàopenrouter/mistral. -
Tùy chỉnh tiêu chí đánh giá output.
-
Chạy test bằng CLI và hiển thị kết quả.
BƯỚC 1: CÀI ĐẶT PROMPTFOO
npm install -g promptfooBƯỚC 2: TẠO CẤU TRÚC THƯ MỤC DỰ ÁN
mkdir promptfoo-demo && cd promptfoo-demo
touch config.yaml
mkdir evals
BƯỚC 3: TẠO TẬP TIN CẤU HÌNH config.yaml
prompts:
- "Translate to French: {{input}}"
- "Please provide the French translation for: {{input}}"
providers:
- id: openai:gpt-3.5-turbo
config:
apiKey: $OPENAI_API_KEY
- id: openrouter:mistralai/mistral-7b-instruct
config:
apiKey: $OPENROUTER_API_KEY
tests:
- vars:
input: "Hello, how are you?"
assert:
includes:
- "Bonjour"
- vars:
input: "I am going to the market."
assert:
includes:
- "marché"
Bạn cần lấy API Key từ OpenAI và OpenRouter.
BƯỚC 4: CHẠY ĐÁNH GIÁ
Chạy benchmark từ CLI:
promptfoo eval config.yamlSau đó, hiển thị dashboard kết quả:
promptfoo webMở trình duyệt tại địa chỉ: http://localhost:3000 để xem kết quả trực quan.
Bài Thực Hành: Đánh Giá Hệ Thống RAG với TruLens và LangChain
Mục Tiêu
-
Xây dựng một hệ thống RAG đơn giản sử dụng LangChain.
-
Tích hợp TruLens để theo dõi và đánh giá hiệu suất của hệ thống.
-
Áp dụng các hàm phản hồi (feedback functions) để đo lường các chỉ số như độ liên quan, tính chính xác và sự phù hợp của ngữ cảnh.docs.pinecone.io+1TruEra+1
Bước 1: Cài Đặt Môi Trường
Cài đặt các thư viện cần thiết:
pip install trulens trulens-apps-langchain trulens-providers-openai openai langchain langchainhub langchain-openai langchain_community faiss-cpu bs4 tiktokenThiết lập khóa API cho OpenAI:
import os
os.environ["OPENAI_API_KEY"] = "sk-..." # Thay thế bằng khóa API của bạnBước 2: Tạo Hệ Thống RAG Đơn Giản
Tạo một ứng dụng RAG đơn giản sử dụng LangChain:
from langchain.chains import RetrievalQA
from langchain.vectorstores import FAISS
from langchain.embeddings import OpenAIEmbeddings
from langchain.chat_models import ChatOpenAI
from langchain.document_loaders import TextLoader
# Tải dữ liệu
loader = TextLoader("data.txt")
documents = loader.load()
# Tạo vector store
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# Tạo hệ thống RAG
qa_chain = RetrievalQA.from_chain_type(
llm=ChatOpenAI(temperature=0),
retriever=vectorstore.as_retriever()
)
Bước 3: Tích Hợp TruLens
Sử dụng TruLens để theo dõi và đánh giá hệ thống:YouTube+5TruLens+5YouTube+5
from trulens_eval import Tru
from trulens_eval.feedback import Feedback
from trulens_eval.feedback.provider.openai import OpenAI as OpenAIFeedbackProvider
from trulens_eval.apps.langchain import instrument_langchain
# Khởi tạo Tru
tru = Tru()
# Thiết lập các hàm phản hồi
openai_provider = OpenAIFeedbackProvider()
f_qa_relevance = Feedback(openai_provider.relevance).on_input_output()
f_context_relevance = Feedback(openai_provider.relevance).on_input().on_retrieved_context()
f_groundedness = Feedback(openai_provider.groundedness).on_input().on_retrieved_context().on_output()
# Tích hợp TruLens vào hệ thống
qa_chain_recorder = instrument_langchain(
qa_chain,
app_id="langchain_app",
feedbacks=[f_qa_relevance, f_context_relevance, f_groundedness]
)
Bước 4: Gửi Truy Vấn và Đánh Giá
Gửi truy vấn và đánh giá phản hồi:
with qa_chain_recorder as recorder:
response = qa_chain_recorder.query("What is the capital of France?")
print(response)
Bước 5: Khám Phá Kết Quả trong Dashboard
Khởi chạy dashboard của TruLens để xem kết quả đánh giá:docs.pinecone.io
tru.run_dashboard()Dashboard sẽ hiển thị các chỉ số như:
-
QA Relevance: Độ liên quan giữa câu hỏi và câu trả lời.
-
Context Relevance: Độ liên quan giữa truy vấn và ngữ cảnh được truy xuất.
-
Groundedness: Mức độ mà câu trả lời dựa trên ngữ cảnh được cung cấp.docs.pinecone.ioLab Lab+2Analytics Vidhya+2Zilliz+2
Bước 6: Tối Ưu Hệ Thống
Dựa trên các phản hồi và chỉ số từ TruLens, bạn có thể:
-
Điều chỉnh kích thước chunk hoặc chiến lược chunking.
-
Thay đổi mô hình embedding hoặc vector store.
-
Tối ưu prompt để cải thiện độ chính xác và tính phù hợp của câu trả lời.Zilliz+1TruLens+1
Bài thực hành PEFT: Phân loại phản hồi khách hàng (Feedback)
Dưới đây là một bài thực hành PEFT gắn liền với thực tế, cụ thể là bài toán phân loại phản hồi khách hàng (Feedback) của người dùng tiếng Việt thành các nhóm: Tích cực, Tiêu cực, Trung lập. Bài này áp dụng PEFT (LoRA) để fine-tune một mô hình nhỏ và dễ triển khai thực tế trong doanh nghiệp hoặc startup.
"Phân loại phản hồi khách hàng tiếng Việt bằng PEFT + LoRA"
Mục tiêu:
-
Hiểu cách áp dụng PEFT với LoRA để fine-tune mô hình pre-trained cho phân loại văn bản.
-
Làm việc với dữ liệu phản hồi khách hàng (giả lập từ thực tế).
-
Tối ưu hoá chi phí và thời gian train bằng cách chỉ fine-tune một phần nhỏ mô hình.
Bối cảnh thực tế
Một cửa hàng TMĐT muốn tự động phân loại phản hồi khách hàng sau mỗi đơn hàng để:
-
Gửi báo cáo chất lượng dịch vụ theo tuần/tháng.
-
Phân nhóm khiếu nại để ưu tiên xử lý.
-
Tự động gắn thẻ sentiment vào feedback để dễ lọc.
Cài đặt thư viện
pip install transformers datasets accelerate peft bitsandbytesDataset giả lập
from datasets import Dataset
data = {
"text": [
"Giao hàng nhanh, sản phẩm đẹp", # tích cực
"Tôi rất thất vọng vì sản phẩm bị hỏng", # tiêu cực
"Bình thường, không có gì đặc biệt", # trung lập
"Đóng gói kỹ, tôi sẽ quay lại mua", # tích cực
"Hàng giao trễ, đóng gói cẩu thả", # tiêu cực
"Ổn, chưa biết có dùng lâu được không" # trung lập
],
"label": [2, 0, 1, 2, 0, 1] # 0: tiêu cực, 1: trung lập, 2: tích cực
}
dataset = Dataset.from_dict(data).train_test_split(test_size=0.3)
Tiền xử lý
from underthesea import word_tokenize
def tokenize_vi(example):
example["text"] = word_tokenize(example["text"], format="text")
return example
dataset = dataset.map(tokenize_vi)Dùng PhoBERT + LoRA để fine-tune
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from peft import get_peft_model, LoraConfig, TaskType
model_id = "vinai/phobert-base"
tokenizer = AutoTokenizer.from_pretrained(model_id, use_fast=False)
base_model = AutoModelForSequenceClassification.from_pretrained(model_id, num_labels=3)
lora_config = LoraConfig(
r=8,
lora_alpha=32,
target_modules=["encoder.layer.11.output.dense"],
lora_dropout=0.1,
bias="none",
task_type=TaskType.SEQ_CLS
)
peft_model = get_peft_model(base_model, lora_config)
peft_model.print_trainable_parameters()
Huấn luyện mô hình
def encode(example):
return tokenizer(example["text"], truncation=True, padding="max_length", max_length=128)
encoded = dataset.map(encode)
from transformers import TrainingArguments, Trainer
from sklearn.metrics import classification_report
import numpy as np
def compute_metrics(eval_pred):
logits, labels = eval_pred
preds = np.argmax(logits, axis=1)
return {"accuracy": (preds == labels).mean()}
training_args = TrainingArguments(
output_dir="./sentiment_model",
per_device_train_batch_size=4,
num_train_epochs=3,
evaluation_strategy="epoch",
logging_dir="./logs"
)
trainer = Trainer(
model=peft_model,
args=training_args,
train_dataset=encoded["train"],
eval_dataset=encoded["test"],
tokenizer=tokenizer,
compute_metrics=compute_metrics
)
trainer.train()
Dự đoán phản hồi mới (ví dụ thực tế)
import torch
label_map = {0: "Tiêu cực", 1: "Trung lập", 2: "Tích cực"}
def predict(text):
text = word_tokenize(text, format="text")
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding="max_length", max_length=128)
with torch.no_grad():
logits = peft_model(**inputs).logits
pred = torch.argmax(logits, axis=1).item()
return label_map[pred]
# Ví dụ thực tế
feedback = "Mình không hài lòng với chất lượng vải"
print("Phân loại:", predict(feedback))
Ứng dụng thực tế
-
Tích hợp vào backend của trang web TMĐT, nhận phản hồi → phân loại tự động.
-
Lưu label sentiment vào cơ sở dữ liệu để thống kê cảm xúc khách hàng theo thời gian.
-
Gửi cảnh báo nội bộ nếu số phản hồi tiêu cực tăng vọt.
Unit Test
Template
## Repo: rag_unit_test_template
# 📁 Folder Structure
rag_unit_test_template/
├── rag_pipeline.py
├── retriever.py
├── generator.py
├── test/
│ ├── test_pipeline.py
│ ├── test_retriever.py
│ └── test_generator.py
├── requirements.txt
└── README.md
# 📄 rag_pipeline.py
class RAGPipeline:
def __init__(self, retriever, generator):
self.retriever = retriever
self.generator = generator
def run(self, query):
docs = self.retriever.retrieve(query)
return self.generator.generate(query, docs)
# 📄 retriever.py
class SimpleRetriever:
def __init__(self, corpus):
self.corpus = corpus
def retrieve(self, query):
return [doc for doc in self.corpus if query.lower().split()[0] in doc.lower()]
# 📄 generator.py
class DummyGenerator:
def generate(self, query, documents):
return f"Answering '{query}' using: {documents[0]}"
# 📄 test/test_pipeline.py
import pytest
from unittest.mock import MagicMock
from rag_pipeline import RAGPipeline
def test_rag_pipeline_returns_expected_output():
mock_retriever = MagicMock()
mock_retriever.retrieve.return_value = ["Mock doc"]
mock_generator = MagicMock()
mock_generator.generate.return_value = "Mock answer"
pipeline = RAGPipeline(mock_retriever, mock_generator)
result = pipeline.run("What is mock?")
assert result == "Mock answer"
mock_retriever.retrieve.assert_called_once_with("What is mock?")
mock_generator.generate.assert_called_once_with("What is mock?", ["Mock doc"])
# 📄 test/test_retriever.py
from retriever import SimpleRetriever
def test_simple_retriever_returns_match():
retriever = SimpleRetriever(["Paris is the capital of France."])
docs = retriever.retrieve("What is the capital of France?")
assert any("Paris" in doc for doc in docs)
# 📄 test/test_generator.py
from generator import DummyGenerator
def test_dummy_generator_formats_output():
gen = DummyGenerator()
result = gen.generate("What is AI?", ["AI is artificial intelligence."])
assert "What is AI?" in result
assert "AI is artificial intelligence." in result
# 📄 requirements.txt
pytest
# 📄 README.md
# RAG Unit Test Template
This repo demonstrates how to build a unit-tested RAG (Retrieval-Augmented Generation) system.
## 📦 Components
- SimpleRetriever: Retrieves documents based on keyword match
- DummyGenerator: Generates answer using context
- RAGPipeline: Combines retriever + generator
## ✅ Unit Tests
Run all tests with:
```bash
pytest test/ -v
```
You can expand this repo with real vector stores (FAISS/Chroma) or LLMs (Flan-T5) later.
Unit test cho hệ thống RAG
Viết unit test cho hệ thống RAG (Retrieval-Augmented Generation) giúp đảm bảo rằng các thành phần chính như Retriever, Generator, và Data Pipeline hoạt động chính xác, độc lập và có thể kiểm soát được. Dưới đây là hướng dẫn thực hành cách viết unit test cho hệ thống RAG sử dụng Python (với pytest) và thư viện phổ biến như LangChain hoặc custom code.
1. Các thành phần cần kiểm thử
Hệ thống RAG thường gồm:
-
Retriever – Tìm kiếm các đoạn văn bản phù hợp từ kho dữ liệu.
-
Generator – Sinh câu trả lời dựa trên ngữ cảnh và câu hỏi.
-
RAG Pipeline – Tổng thể pipeline kết hợp cả retriever và generator.
-
Post-processing (tuỳ chọn) – Xử lý đầu ra của LLM.
2. Cấu trúc ví dụ RAG
Giả sử bạn có pipeline như sau:
class RAGPipeline:
def __init__(self, retriever, generator):
self.retriever = retriever
self.generator = generator
def run(self, query):
documents = self.retriever.retrieve(query)
return self.generator.generate(query, documents)
3. Cách viết unit test
3.1. Tạo file test_rag.py
import pytest
from unittest.mock import MagicMock
from rag_pipeline import RAGPipeline
def test_rag_pipeline_returns_expected_output():
# Mock retriever
mock_retriever = MagicMock()
mock_retriever.retrieve.return_value = ["This is a test document."]
# Mock generator
mock_generator = MagicMock()
mock_generator.generate.return_value = "This is a generated answer."
# Create pipeline
pipeline = RAGPipeline(mock_retriever, mock_generator)
result = pipeline.run("What is this?")
# Assertions
mock_retriever.retrieve.assert_called_once_with("What is this?")
mock_generator.generate.assert_called_once_with("What is this?", ["This is a test document."])
assert result == "This is a generated answer."
3.2. Test retriever riêng biệt
def test_retriever_returns_relevant_docs():
from my_retriever import SimpleRetriever
retriever = SimpleRetriever(["Paris is the capital of France."])
docs = retriever.retrieve("What is the capital of France?")
assert any("Paris" in doc for doc in docs)
4. Công cụ và kỹ thuật nâng cao
-
pytest fixtures để khởi tạo dữ liệu.
-
mocking LLM API calls để tránh chi phí gọi thực tế.
-
test coverage để kiểm tra phần nào chưa được test.
-
snapshot testing để so sánh kết quả sinh tự động với mẫu.
5. Chạy test
pytest test_rag.py -vGợi ý mở rộng
-
Test tích hợp: Chạy full pipeline với vectordb thật (FAISS, Chroma).
-
So sánh kết quả RAG vs non-RAG (benchmark chất lượng sinh).
-
Kết hợp với Promptfoo, LangSmith, hoặc TruLens để test LLM đầu ra tự động.
Repo mẫu cho hệ thống RAG có unit test
Cấu trúc thư mục repo: rag-pipeline-example/
rag-pipeline-example/
├── rag_pipeline/
│ ├── __init__.py
│ ├── retriever.py
│ ├── generator.py
│ └── pipeline.py
├── tests/
│ ├── __init__.py
│ └── test_pipeline.py
├── requirements.txt
└── README.md
1. rag_pipeline/retriever.py
class SimpleRetriever:
def __init__(self, documents):
self.documents = documents
def retrieve(self, query):
# Tìm văn bản chứa từ khoá
return [doc for doc in self.documents if any(word.lower() in doc.lower() for word in query.split())]
2. rag_pipeline/generator.py
class SimpleGenerator:
def generate(self, query, documents):
if not documents:
return "I don't know."
return f"Based on the documents, the answer to '{query}' is related to: {documents[0]}"
3. rag_pipeline/pipeline.py
class RAGPipeline:
def __init__(self, retriever, generator):
self.retriever = retriever
self.generator = generator
def run(self, query):
docs = self.retriever.retrieve(query)
return self.generator.generate(query, docs)
4. tests/test_pipeline.py
import pytest
from unittest.mock import MagicMock
from rag_pipeline.pipeline import RAGPipeline
from rag_pipeline.retriever import SimpleRetriever
from rag_pipeline.generator import SimpleGenerator
def test_pipeline_with_mock():
retriever = MagicMock()
generator = MagicMock()
retriever.retrieve.return_value = ["Mock document"]
generator.generate.return_value = "Mock answer"
rag = RAGPipeline(retriever, generator)
result = rag.run("What is this?")
assert result == "Mock answer"
retriever.retrieve.assert_called_once()
generator.generate.assert_called_once()
def test_pipeline_with_real_components():
retriever = SimpleRetriever([
"Paris is the capital of France.",
"Berlin is the capital of Germany."
])
generator = SimpleGenerator()
rag = RAGPipeline(retriever, generator)
result = rag.run("What is the capital of France?")
assert "Paris" in result
5. requirements.txt
pytestBạn có thể thêm langchain, transformers, faiss-cpu nếu mở rộng thực tế.
6. README.md
# RAG Pipeline Example
This is a simple Retrieval-Augmented Generation pipeline with unit tests.
## Run tests
```bash
pip install -r requirements.txt
pytest tests/ -v
---
## ▶️ Cách chạy
```bash
# Tải repo
git clone <repo-url> rag-pipeline-example
cd rag-pipeline-example
# Cài đặt & chạy test
pip install -r requirements.txt
pytest tests/